Xlearn是你面对结构化数据分类/回归任务时,除了xgboost/lightgbm/catboost之外,又不想搞训练很慢的深度学习模型时,可以尝试考虑的一个能够快速落地的机器学习baseline基准。
你可以将它单独使用 (在某些场景中可能会好于GBDT类模型),也可以尝试将它和GBDT类模型进行模型融合(基本在所有场景中都会有所提升)。
它常常在广告点击率预测、推荐系统等存在大规模稀疏特征,并且特征交叉比较重要的场景中表现比较亮眼。
XLearn 一般用于解决二分类问题和回归问题。主要支持以下三种模型。
LR(Linear Regression): 线性回归/逻辑回归。LR无法直接捕捉特征之间的交叉,适合作为Baseline使用。工业应用场景中可以根据业务理解手工设计出有效的特征交叉。也可以利用树模型的叶子节点的特征分裂规则自动产生高阶交叉特征输送给LR。
FM(FactorizationMachine):在LR基础上用隐向量点积实现自动化特征二阶交叉,且交互项的计算复杂度是O(n),效果显著好于LR,速度极快接近LR。
FFM(Field Aware FM): 在FM的基础上考虑对不同的特征域(Field,可以理解成特征的分组)使用不同的隐向量。效果好于FM,但参数量增加,预测速度下降。
公众号 算法美食屋 后台回复关键词:xlearn,获取本文notebook源代码,以及cretio_small.zip广告点击预测数据集。
〇,安装Xlearn
xlearn依赖gcc和cmake。linux环境可以用apt-get安装。
依赖安装好后,可以直接用pip安装xlearn。也可以git克隆下最新源码进行一键安装。
推荐使用git clone下源码的安装方式,版本更新,并且可以download下git项目中的范例数据集和代码。
1,安装依赖
!gcc --version #查看gcc是否存在,一般都是存在的
#!yes|apt-get install gcc#!yes|apt-get install cmake
!pip install cmake2,安装xlearn
#直接pip安装
#!pip install xlearn#从源码下载最新版本,然后一键安装
!git clone https://github.com/aksnzhy/xlearn/%%bash
cd xlearn
./build.sh3,检验是否安装成功
我们通过一个非常简单的xlearn的sklearn接口
进行iris花瓣分类问题建模来测试xlearn是否安装成功 。
import os
os.environ['USER'] = 'test' #没有USER环境变量可能会报错import numpy as np
import pandas as pd
import xlearn as xl
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score #1,准备数据
dfiris = load_iris()
X,y = dfiris['data'],(dfiris['target'] == 2)
X_train, X_val, y_train,y_val = train_test_split(X, y, test_size=0.3, random_state=0)#2,定义模型
model = xl.LRModel(task='binary', init=0.1,epoch=10, lr=0.1, reg_lambda=1.0)#3,训练模型
model.fit(X_train, y_train,eval_set=[X_val, y_val])#4,使用模型
y_pred = model.predict(X_val)
val_auc = roc_auc_score(y_val.astype(float),y_pred)
print('val_auc=',auc)一, 回归问题范例
下面我们使用房价预测范例来演示使用xlearn来解决回归问题。
我们将使用xlearn的原生接口xl.create_fm()来构建模型,
使用xl.DMatrix来准备数据集。
import os
os.environ['USER'] = 'test' #没有USER环境变量可能会报错
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import xlearn as xl#1,准备数据
dfdata = pd.read_csv("xlearn/demo/regression/house_price/house_price_train.txt", header=None, sep="\t")
dftrain,dfval = train_test_split(dfdata,test_size=200)
dftest = pd.read_csv("xlearn/demo/regression/house_price/house_price_test.txt", header=None, sep="\t")Xtrain,ytrain = dftrain[dftrain.columns[1:]],dftrain[0]
Xval,yval = dfval[dfval.columns[1:]],dfval[0]
Xtest,ytest = dftest[dftest.columns[1:]],dftest[0]
dm_train = xl.DMatrix(Xtrain, ytrain)
dm_val = xl.DMatrix(Xval, yval)
dm_test = xl.DMatrix(Xtest, ytest)# 2,定义模型
model = xl.create_fm() #xl.create_linear(), xl.create_ffm()
model.setTrain(dm_train)
model.setValidate(dm_val)
param = {'task':'reg', #task 可以为 'binary' 或者 'reg', 'lr':0.2, 'lambda':0.002, #参数L2正则系数'metric':'mae','nthread':8, #使用线程数'epoch':20,'stop_window':10 #10个epoch未提升早停}# 3,训练模型
model_path = "./model.out"
model.fit(param, model_path)# 4,验证模型
model.setTest(dm_train)
yhat_train = model.predict(model_path)
train_acc = 1- np.abs(yhat_train-ytrain).sum()/np.abs(0.5*(yhat_train+ytrain)).sum()model.setTest(dm_val)
yhat_val = model.predict(model_path)
val_acc = 1- np.abs(yhat_val-yval).sum()/np.abs(0.5*(yhat_val+yval)).sum()print('\n'*5+'='*80)
print('train_acc =',train_acc)
print('val_acc =',val_acc)
print('='*80+'\n'*5)# 5,使用模型
#(模型已经保存在model_path了,可以直接加载预测)
import xlearn as xl
model_loaded = xl.create_fm()
model_loaded.setTest("xlearn/demo/regression/house_price/house_price_test.txt")
out_path = './ypred.txt'
model_loaded.predict(model_path,out_path)二, 分类问题范例
我们以使用FFM算法处理Criteo广告点击率预测问题为例,展示xlearn的处理分类问题的典型流程。
Criteo数据集是一个经典的广告点击率CTR预测数据集。
这个数据集的目标是通过用户特征和广告特征来预测某条广告是否会为用户点击。
数据集有13维数值特征(I1~I13)和26维类别特征(C14~C39), 共39维特征, 特征中包含着许多缺失值。
训练集4000万个样本,测试集600万个样本。数据集大小超过100G.
此处使用的是采样100万个样本后的criteo_small数据集。
1,准备数据
Xlearn为FFM模型组织数据集最高效的方法是将数据整理成libffm格式。
libffm格式是专门为FFM算法设计的一种txt数据格式,当然这种格式也支持Xlearn中的FM模型和LR模型。
libffm格式的每一行是一条样本,按照如下格式排布。
label field1:feature1:value1 field1:feature2:value2 field2:feature3:value3在FFM相关的模型中,有field(阈)和feature(特征)的概念区分,一个field可以对应一个或者多个features.
下面我们对数值类特征做缺失值填充和分位数归一化处理,并添加分桶化类别特征,对原始的类别特征做编码转换处理,最后转换成libffm的格式。
from sklearn.base import BaseEstimator, TransformerMixin
from tqdm.auto import tqdm
class CatEncoder(BaseEstimator, TransformerMixin):def __init__(self, cat_features, max_dictionary_size=200):self.cat_features = cat_featuresself.max_dictionary_size = max_dictionary_size self.trans_dics = {}def fit(self, X, y=None):for col in tqdm(self.cat_features):Xcol = self._fillna(X[col])self.trans_dics[col] = self._get_trans_dic(Xcol)return selfdef transform(self, X, y=None):Xs = [self._fillna(X[col]).apply(lambda a:self.trans_dics[col].get(a,0))for col in self.cat_features]return pd.concat(Xs,axis=1).values def _fillna(self, seri):return seri.astype(str).fillna("nan")def _get_trans_dic(self,seri):max_dictionary_size = self.max_dictionary_sizedfi = pd.DataFrame(seri.value_counts()).rename(lambda _:"count",axis = 1)dfi.sort_values("count",ascending=False,inplace = True)n = len(dfi)if n<=max_dictionary_size:dfi["index"] = range(n)else:cum = np.cumsum(dfi["count"])cum = cum/cum.iloc[-1]cum_split = cum.iloc[max_dictionary_size//2]get_index = lambda i: i if cum.iloc[i]<=cum_split else max_dictionary_size//2 + int((max_dictionary_size-max_dictionary_size//2)*(cum.iloc[i]-cum_split-1e-12)/(1-cum_split))dfi["index"] = [get_index(i) for i in range(n)]trans_dic = dict(dfi["index"]) return trans_dicdef get_feature_names(self):return self.cat_featuresfrom sklearn.preprocessing import LabelEncoder,QuantileTransformer,KBinsDiscretizer
from sklearn.impute import SimpleImputer
from tqdm.auto import tqdm dfdata = pd.read_csv("criteo_small.zip",sep="\t",header=None)
dfdata.columns = ["label"] + ["I"+str(x) for x in range(1,14)] + ["C"+str(x) for x in range(14,40)]label_col = 'label'
cat_cols = [x for x in dfdata.columns if x.startswith('C')]
num_cols = [x for x in dfdata.columns if x.startswith('I')]dfdata[cat_cols] = CatEncoder(cat_features = cat_cols).fit_transform(dfdata[cat_cols])
dfdata[num_cols] = SimpleImputer().fit_transform(dfdata[num_cols])for col in tqdm(num_cols):unique_value_cnt = len(np.unique(dfdata[col]))if unique_value_cnt<100:dfdata['C'+col] = LabelEncoder().fit_transform(dfdata[col])else:kbins = KBinsDiscretizer(n_bins=20,encode='ordinal',strategy='kmeans')dfdata['C'+col] = kbins.fit_transform(dfdata[[col]])[:,0].astype(int)dfdata[num_cols] = QuantileTransformer().fit_transform(dfdata[num_cols])from sklearn.model_selection import train_test_splitdftrain_val,dftest = train_test_split(dfdata,test_size=0.2)
dftrain,dfval = train_test_split(dftrain_val,test_size=0.2)label_col = 'label'
cat_cols = [x for x in dfdata.columns if x.startswith('C')]
num_cols = [x for x in dfdata.columns if x.startswith('I')]field_features = defaultdict()
categories = num_cols+cat_cols
categories_index = dict(zip(categories, range(len(categories))))
max_val = 1def df_to_libffm(df,save_file='train.libffm'):from tqdm.auto import tqdm global max_valglobal label_colwith open(save_file, 'a') as the_file:for t in tqdm(range(len(df))):row = df.iloc[t]label = [str(int(row[label_col]))]ffeatures = []for field in categories:if field == label_col:continue feature = row[field]if field not in num_cols:ff = field + '_____' + str(feature)value = 1else:ff = field + '_____' + str(0)value = featureif ff not in field_features:if len(field_features) == 0:field_features[ff] = 1max_val = max_val+1else:field_features[ff] = max_val + 1max_val = max_val+1fnum = field_features[ff]ffeatures.append('{}:{}:{}'.format(categories_index[field],fnum,value))line = label + ffeaturesthe_file.write('{}\n'.format(' '.join(line)))df_to_libffm(dftrain,'train.libffm')0%| | 0/640000 [00:00<?, ?it/s]df_to_libffm(dfval,'val.libffm')0%| | 0/160000 [00:00<?, ?it/s]df_to_libffm(dftest,'test.libffm')0%| | 0/200000 [00:00<?, ?it/s]len(field_features)40122, 定义模型
%%writefile train_ffm.py
import os
os.environ['USER'] = 'test' #没有USER环境变量可能会报错
import xlearn as xl
model = xl.create_ffm()
model.setTrain('train.libffm')
model.setValidate('val.libffm')
#model.disableNorm()
#model.disableEarlyStop()
param = {'task':'binary', 'lr':0.05, 'lambda':0.000, 'nthread':64, 'epoch':200,'stop_window':15, 'metric':'auc'}
model_path = "./model.out"
model.fit(param, model_path)Overwriting train_ffm.py3,训练模型
!python train_ffm.py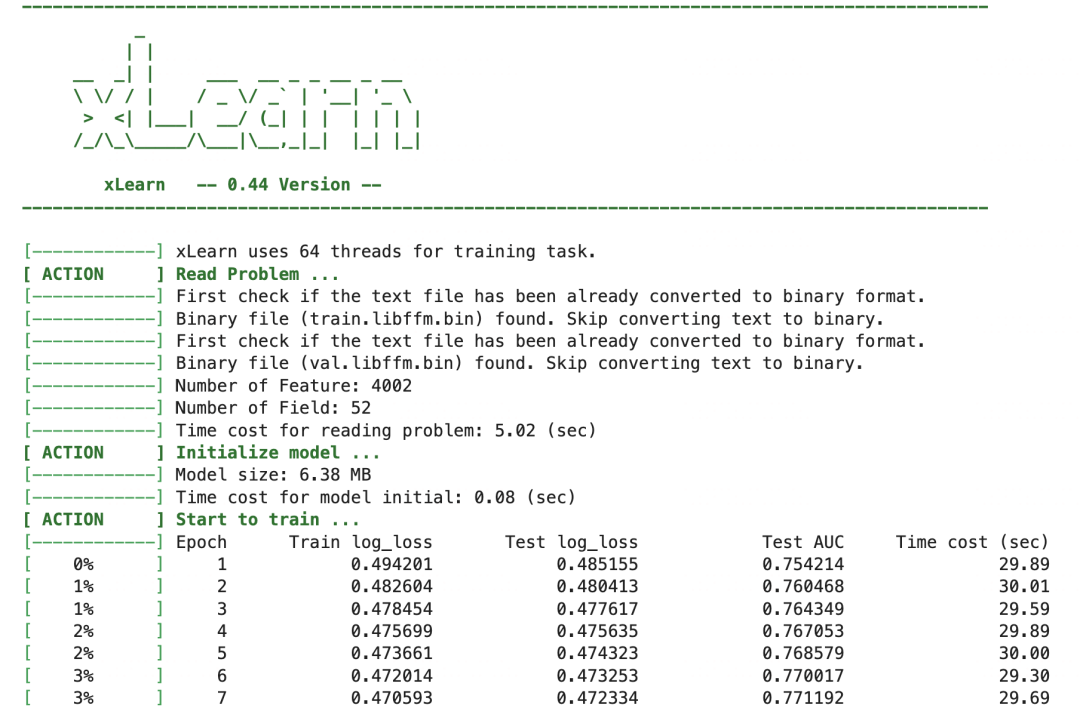
4,验证模型
import os
from sklearn.metrics import roc_auc_score
os.environ['USER'] = 'test' #没有USER环境变量可能会报错
import xlearn as xl
model = xl.create_ffm()
model.setSigmoid()
model_path = "./model.out"model.setTest('train.libffm')
yhat_train = model.predict(model_path)model.setTest('val.libffm')
yhat_val = model.predict(model_path)model.setTest('test.libffm')
yhat_test = model.predict(model_path)train_auc = roc_auc_score(ytrain.values,yhat_train)
val_auc = roc_auc_score(yval.values,yhat_val)
test_auc = roc_auc_score(ytest.values,yhat_test)
print('train_auc = ',train_auc)
print('val_auc = ',val_auc)
print('test_auc = ',test_auc)
三,Xlearn的速查列表
1,Xlearn的API列表
import xlearn as xl # Import xlearn packagexl.hello() # Say hello to user#This part is for data
#X is feautres data, can be pandas DataFrame or numpy.ndarray,
#y is label, default None, can be pandas DataFrame\Series, array or list,
#filed_map is field map of features, default None, can be pandas DataFrame\Series, array or list
dmatrix = xl.DMatrix(X, y, field_map)model = create_linear() #Create linear model.model = create_fm() #Create factorization machines.model = create_ffm() #Create field-aware factorizarion machines.model.show() #Show model information.model.fit(param, "model_path") #Train model.model.cv(param) #Perform cross-validation.#Users can choose one of this two
model.predict("model_path", "output_path") #Perform prediction, output result to file, return None.
model.predict("model_path") #Perform prediction, return result by numpy.ndarray.#Users can choose one of this two
model.setTrain("data_path") #Set training data from file for xLearn.
model.setTrain(dmatrix) #Set training data from DMatrix for xLearn.#Users can choose one of this two
#note: this type of validate must be same as train
#that is, set train from file, must set validate from file
model.setValidate("data_path") #Set validation data from file for xLearn.
model.setValidate(dmatrix) #Set validation data from DMatrix for xLearn.#Users can choose one of this two
model.setTest("data_path") #Set test data from file for xLearn.
model.setTest(dmatrix) #Set test data from DMatrix for xLearn.model.setQuiet() #Set xlearn to train model quietly.model.setOnDisk() #Set xlearn to use on-disk training.model.setNoBin() #Do not generate bin file for training and test data.model.setSign() #Convert prediction to 0 and 1.model.setSigmoid() #Convert prediction to (0, 1).model.disableNorm() #Disable instance-wise normalization.model.disableLockFree() #Disable lock-free training.model.disableEarlyStop() #Disable early-stopping.2,Xlearn超参数列表
task : {'binary', #Binary classification'reg'} #Regressionmetric : {'acc', 'prec', 'recall', 'f1', 'auc', #for classification'mae', 'mape', 'rmse', 'rmsd'} #for regressionlr : float value #learning ratelambda : float value #regular lambdak : int value #latent factor for fm and ffminit : float value #model initializealpha : float value #hyper parameter for ftrlbeta : float value #hyper parameter for ftrllambda_1 : float value #hyper parameter for ftrllambda_2 : float value #hyper parameter for ftrlnthread : int value #the number of CPU coresepoch : int vlaue #number of epochfold : int value #number of fold for cross-validationopt : {'sgd', 'agagrad', 'ftrl'} #optimization methodstop_window : Size of stop window for early-stopping.block_size : int value #block size for on-disk training公众号 算法美食屋 后台回复关键词:xlearn,获取本文notebook源代码,以及cretio_small.zip广告点击预测数据集。
万水千山总是情,点个在看行不行?
一个有毅力的吃货祝大家元旦快乐~ 😋😋