前言
本文不涉及ES的具体安装下载、操作、集群的内容,这部分内容会放在后面一篇文章中。本文只包含ES的核心理论,看完本文再去学ES的细节会事半功倍。


目录
1.由日志存储引出的问题
2.什么是ES?
3.ES的数据结构
4.ES的核心原理
5.联系作者
1.由日志存储引出的问题
本文或者说本系列的来源:
前面我们聊过了分布式链路追踪系统,在基于日志实现的分布式链路追踪的方式seluth+zipkin中为了防止数据丢失,需要将数据持久化。我们给出的是持久化进mysql中的示例。
【JAVA】分布式链路追踪技术概论-CSDN博客
【分布式链路追踪技术】sleuth+zipkin-CSDN博客
这里就需要关注一个问题了:
用mysql来存储日志真的合适吗?或者说用什么方式来存储日志合适喃?
从两个场景来具体切入:
-
聚合
-
搜索
聚合:
我们收集到日志后,需要对内容进行一些统计,比如请求报错的比列,就要去统计error的数量。
搜索:
我们收集到日志后需要进行一些搜索,比如在进行问题排查的时候搜索一些具体的报错信息。
以上两个操作MySQL支持吗?很明显是支持的,用聚合函数和like函数可以轻松实现。但是性能喃?
日志是文本类的数据,是非结构化的,不是结构化的。要存储到mysql中也是将日志内容存到一个字段上,对这个字段内的内容进行模糊查询根本没办法用到索引,一旦数据量大了以后,会迎来性能上的灾难。除此之外我们再仔细思考一下,内容存在单字段内,似乎聚合也不是很好做。
所以我们说,关系型的数据交给关系型数据库来做,非关系型的数据还是交给非关系型的数据来做才合适。
这里复习一下什么是关系型和非关系型最核心的区别:
关系型,数据之间(表之间)可以通过主键、外键之间建立起很强的关系。
非关系型,数据之间相对独立,没有建立起很强关联关系的方式。
2.什么是ES?
前面我们聊过了对于文本内容来说,关系型数据库是很难满足业务要求的。这时候就需要用到专业的做文本搜索的组件。Elasticsearch(简称ES) 是为全文搜索而设计的,可以快速且高效地搜索大量文本数据。它支持复杂的查询,包括全文、模糊、通配符、范围和正则表达式查询等。
ES的架构其实可以类比数据库来理解:
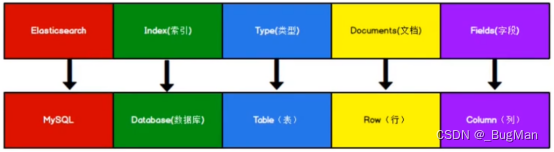
| ES | database |
|---|---|
| 索引 | 库 |
| 类型 | 表 |
| 文档 | 行 |
| 字段 | 列 |
目前新版本的ES中是没有type这一层级的,这是因为ES使用了倒排索引,层级过多会影响性能,而且随着在实际应用中的铺开,大家发现对于文档来说,类型其实是多余的,如果非要使用类型的概念,索引层面已经可以实现了,把不同分类的数据放到不同的索引中就行了。于是在之前的三个大版本的迭代中,ES围绕淡化和去除type做了一些工作:
-
5.X及其以前,一个index下允许存在多个type。
-
6.X一个index下只允许存在一个type。
-
7.X即其以后,取消了type这个概念。
3.ES的数据结构
ES是用Json的方式来组织数据的,下面来演示一下一篇文章在ES中是怎样存储的。
随便打开百度上今天的一条热搜新闻:

建立好索引并声明好各个字段的配置:
ES是采用rest api的方式通过http method+参数的方式来进行操作的,创建index是put方法跟上index的名字和index的详细描述。
PUT /my_article_index
{
"settings": {
"number_of_shards": 3, // 设置分片数量
"number_of_replicas": 1 // 设置副本数量
},
"mappings": {
"properties": {
"title": {
"type": "text", // 文本类型,用于全文搜索
"fields": {
"keyword": {
"type": "keyword", // 关键字类型,用于精确匹配
"ignore_above": 256 // 忽略较长的文本
}
}
},
"content": {
"type": "text", // 文本类型,用于全文搜索
"analyzer": "standard" // 使用标准分析器
},
"author": {
"type": "keyword" // 关键字类型,用于精确匹配
},
"publish_date": {
"type": "date", // 日期类型
"format": "yyyy-MM-dd HH:mm:ss||epoch_millis" // 支持的日期格式
}
}
}
}
将文章存进建立好的索引中:
ES是采用rest api的方式通过http method+参数的方式来进行操作的,向index中添加数据是post方法+index名字+_doc+id,id可以不指定自动生成,也可以指定。
POST /my_article_index/_doc/1
{
"title": "天南地北迎新年 喜庆欢乐庆元旦",
"content": "央视网消息(新闻联播):辞旧迎新,欢度元旦。天南地北的人们在丰富多彩的节庆活动中迎接2024年的到来。跨年夜,神州大地一派欢乐。在北京,新年倒计时主场活动在首钢园举行,精彩纷呈的光影秀、灯光雕塑、文艺表演等,将园区变成了欢乐的海洋。在江西南昌,充满科技与未来感的灯光秀,在城市楼宇间变幻出一幅幅美丽的画卷。在海南海口、安徽芜湖,数百架无人机摆出各种欢度节日的字样和图案,喜迎新年的到来。在重庆解放碑中央广场,众多市民和游客共同聆听新年钟声,许下美好的新年愿望。在福建平潭综合实验区、在太湖边的苏州湾、在北国江城吉林市,寓意着幸福安康、欢乐祥和的烟花秀在夜空绽放,为人们送上新年祝福。在河南郑州、山西忻州,打铁花、创意灯展等表演吸引了众多市民游客。在山东泰山脚下,民俗非遗夜游专场,让游客亲身体验民间习俗。在黑龙江鸡西,晶莹剔透的冰雕、栩栩如生的雪雕与五彩斑斓的花灯交相辉映,营造出浓浓的节日气氛。喜迎新年,尽享欢乐。今天(1月1日),广州白云国际机场、广州南站、广州白云站响起《我爱你中国》等歌曲,大家用快闪歌舞为祖国送上祝福。在内蒙古鄂尔多斯东胜区,堆雪人、亲子拉力赛,人们在冰雪那达慕活动中欢乐跨年。在浙江绍兴丰惠古城、在湖南益阳百年书院,糖画、扇绘、竹编等充满年味的古风集市处处洋溢着节日的喜庆。在贵州乌江寨,地方传统戏剧、杂技轮番上演,人们喝茶看戏,好不惬意。在广西富川瑶族村落,村民穿上节日盛装唱瑶歌,展示传统习俗,祝福新年五谷丰登、国泰民安。",
"author": "央视网",
"publish_date": "2024-01-01 20:07:27"
}
4.ES的核心原理
Elasticsearch中采用倒排索引来支持对文档进行高效的全局搜索。倒排索引是类比正排索引的一个概念。比如在文档中搜索关键字,正排索引的做法是指通过索引找到数据,再在数据中搜索关键字,比如通过id找到content,再在content中寻找关键字。
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引的做法是指的是通过数据找到索引,再通过索引找到文档,会有个地方专门记录每个字段和索引的对应关系。
| keyword | id |
|---|---|
| name | 1001,1002 |
| zhang | 1001 |
| ...... | ...... |
Elasticsearch 采用倒排索引的方式,将每个词汇与其在文档中的位置建立索引。这样的设计使得它更适合文本搜索,尤其是全文搜索。字段和索引的对应关系是在建立倒排索引的时候生成的,Elasticsearch 在建立倒排索引时采用了分词(tokenization)的过程,使用分词器,将文本字段中的文本切分成一个个有意义的词(token)以便进行检索。关于分词器,这是一项开源的技术,其实现是五花八门的,常见的分词器包括标准分词器(standard tokenizer)、较简单的空格分词器(whitespace tokenizer)、关键字分词器(keyword tokenizer)等。ES是支持替换分词器的。
我想到这里大家会有这样的疑惑:
比如ES中存储的是海量数量的文章,那么分词出来的索引和分词的关系也是海量的,即使使用倒排索引,应该也很慢吧。MySQL的索引用了B+树来提升索引的匹配速度,ES是怎么处理的喃?
ES给出了以下两个维度的优化
-
分布式
-
倒排索引的优化
分布式:
Elasticsearch 是为分布式和水平扩展而设计的,它将数据分布在多个节点上,每个节点负责部分数据。这样可以让每个节点上的倒排索引总的规模要小一些。
倒排索引的优化:
Elasticsearch 对倒排索引进行了多方面的优化,包括倒排索引的压缩、分段存储、合并和优化等策略,以提高查询性能。
总的来说倒排索引是文档全文搜索最好的解法,剩下要做的都是围绕采用倒排索引后带来问题进行优化,仅此而已。
5.联系作者
商务合作、各种交流:
公众号:每日十分钟系列,上下班通勤路上,花十分钟掌握一个新的计算机技术知识点,欢迎关注文末公众号。