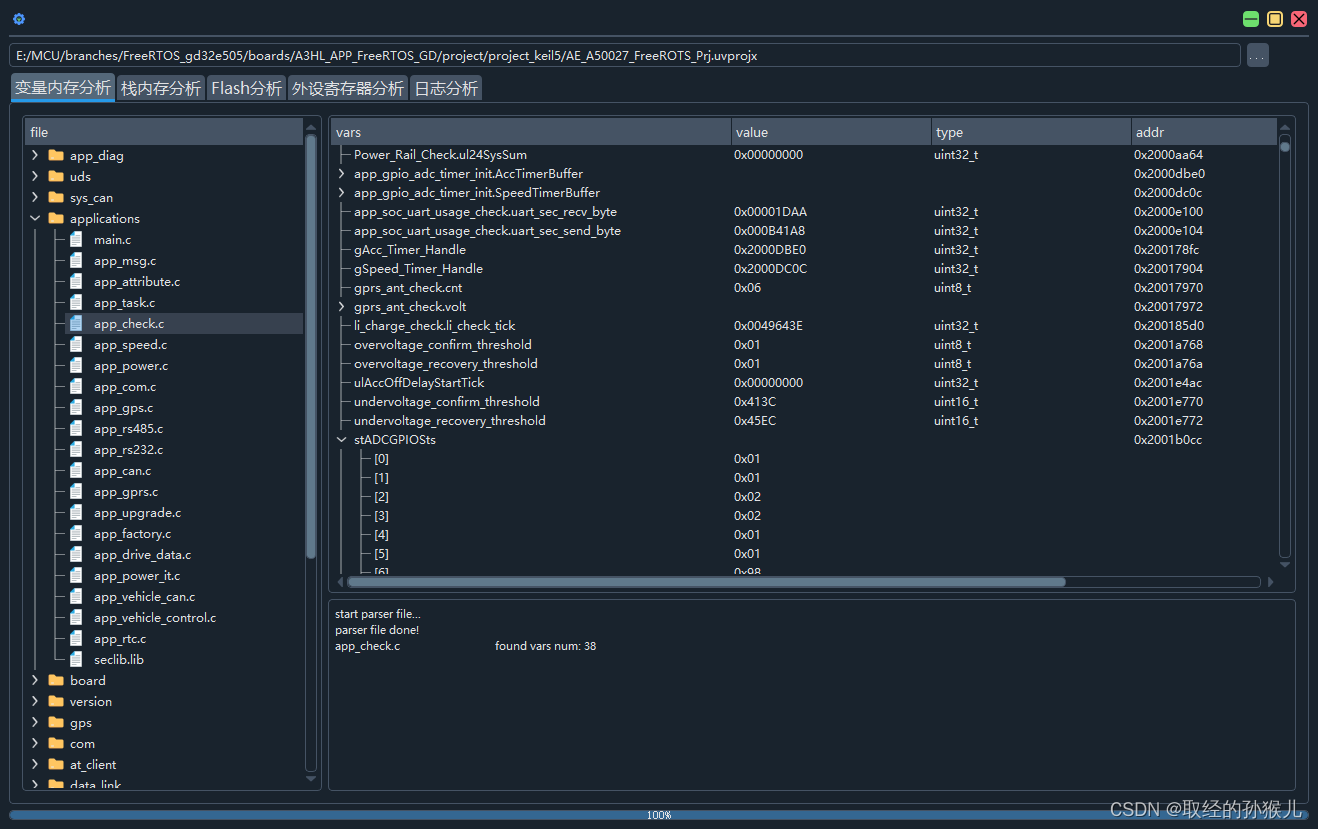
总览
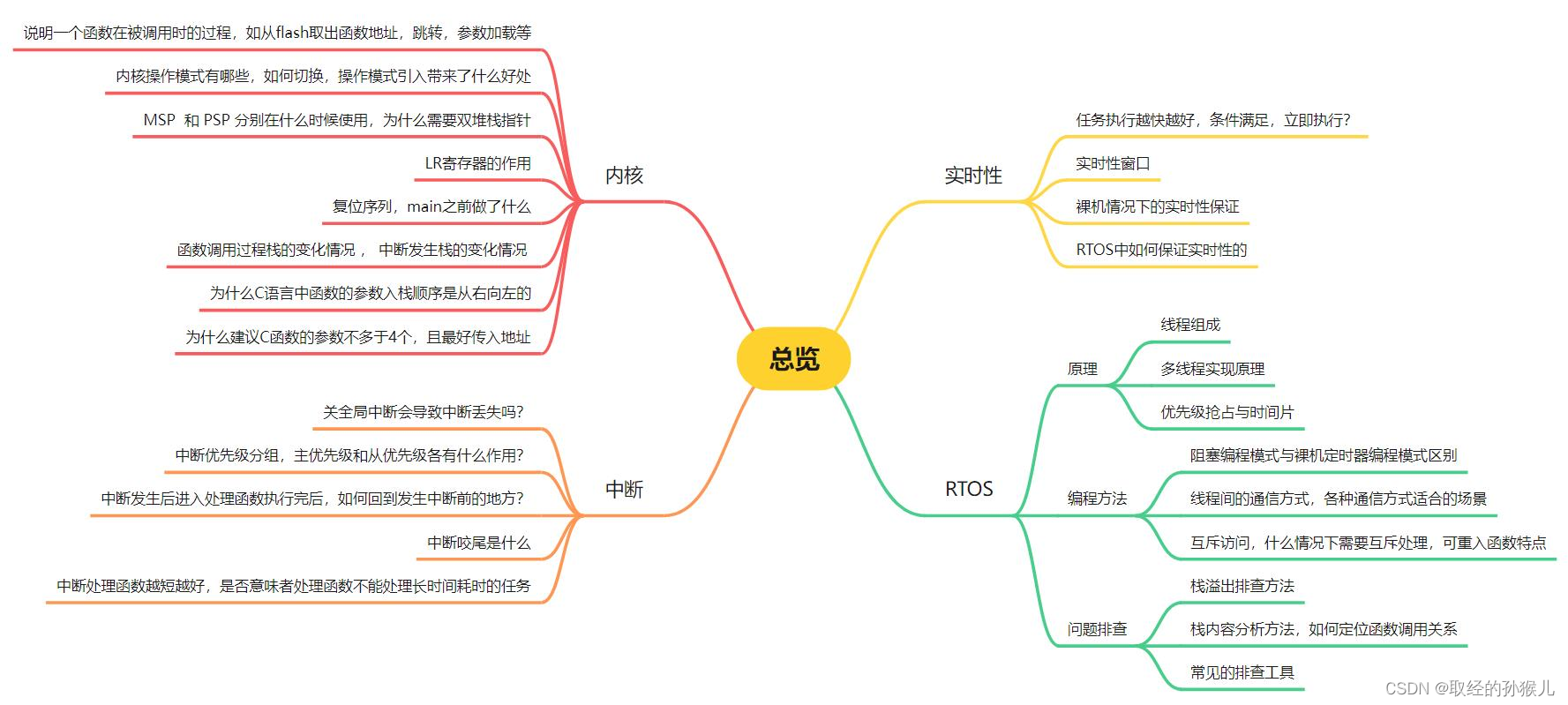
Cortex内核 基础
寄存器组
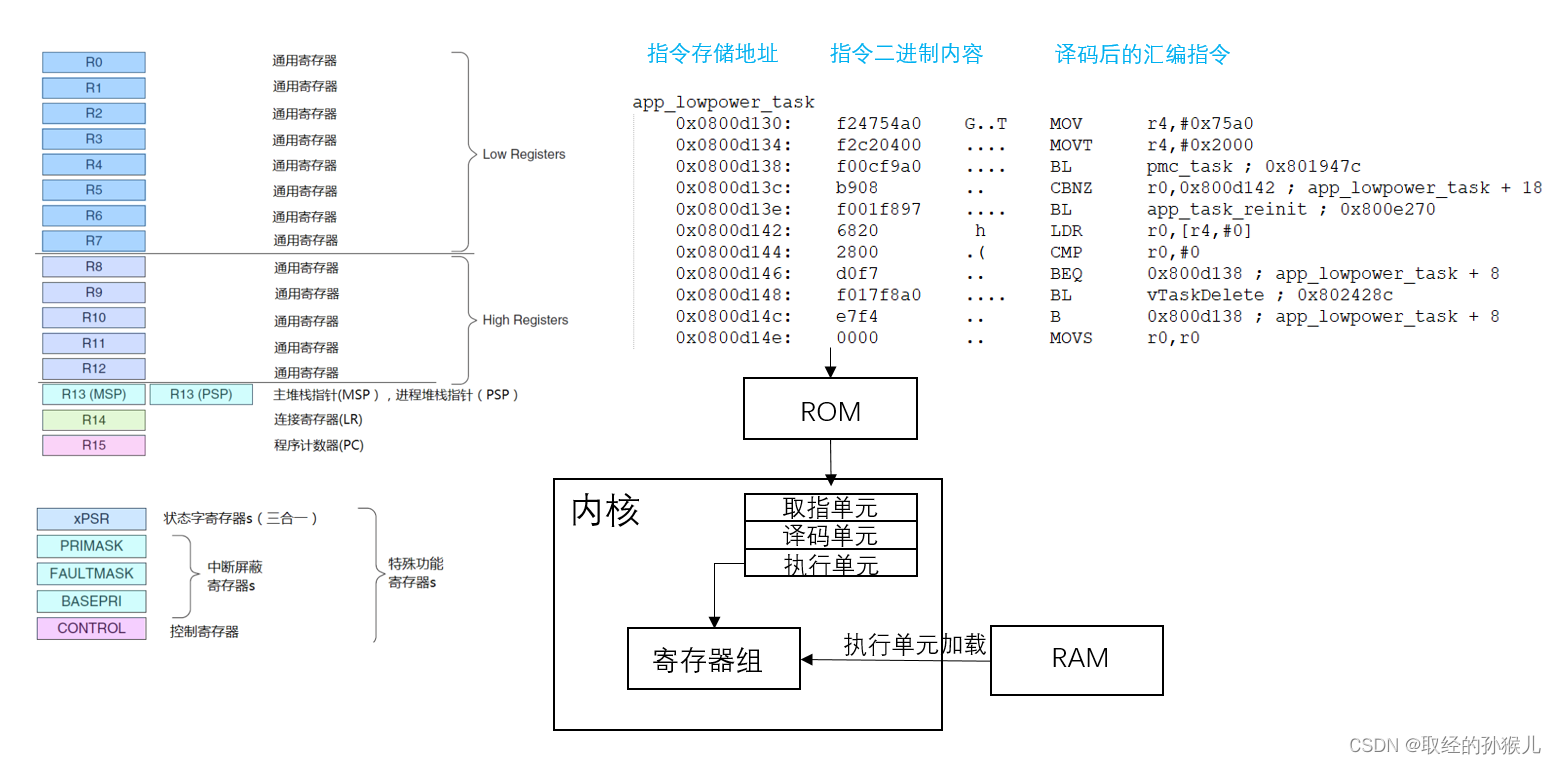
- 程序在经过编译后,生成可执行二进制文件,如上图,是截取某个函数在flash中存储的内容 (反汇编文件)
- 可以看到以下信息:
- 指令的存储地址 ,指令的二进制内容 , 指令代表的汇编类容
- 指令存在32位指令和 16位指令 ,具体可参考权威指南中的 :Thumb指令集 和 ARM指令集
- 此函数的执行过程细节:
- PC指针指向函数开始执行地址 0x0800d130 , 内核的取指单元根据地址,将内容 f24754a0 由flash读取到内核
- 译码单元翻译 f24754a0 ----> MOV r4 , #0x75a0 , 可以看出二进制格式和汇编是相关的,内核存在一套译码规则,比如 f2 表示 MOV
- 执行单元执行此指令 ,将立即数 0x75a0 存到 通用寄存器 R0
- PC 增加,继续上述过程,直到整个函数执行完成
===================================================================================================================
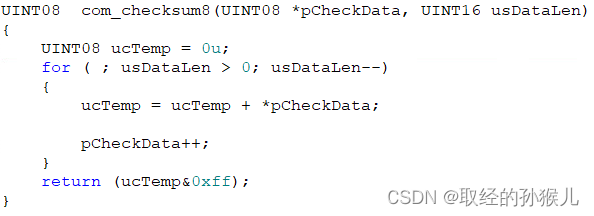
===================================================================================================================
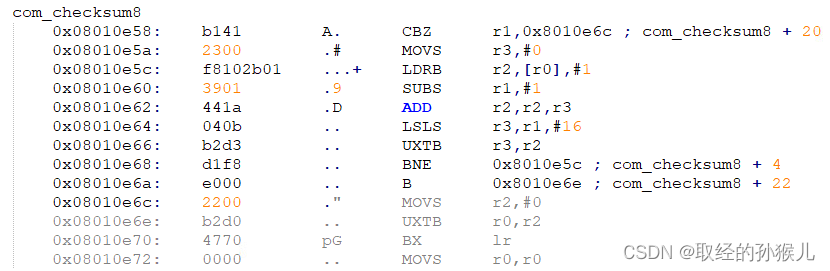
指令流水线
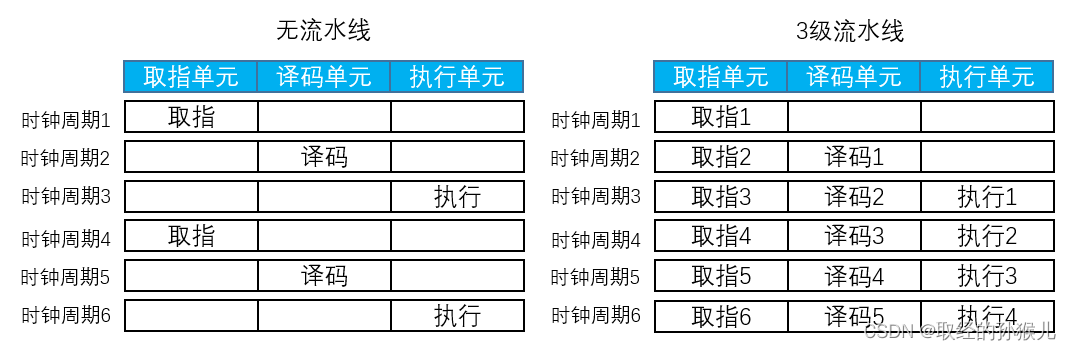
流水线的引入充分利用到了3个指令控制单元,提高了指令处理效率,同时也引入了一些问题。在时钟周期1完成了指令1的取指 ,在时钟周期3才执行指令1,若指令1是个条件分支语句 ,那个指令1的下一条指令是不确定的,这时候内核的取指2和取指3 是进行分支预测的,若预测失败,那么这两次的预先取指将无效,将花费更多的时间重新取指,因此在写if else 时,尽可能将最大可能发生的条件放在首位,这样能减小分支预测错误的概率。
复位序列
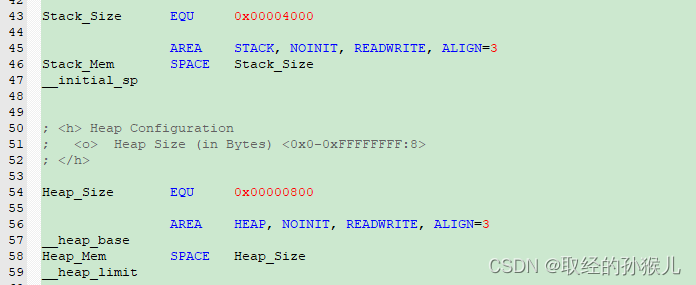
启动文件分析
- 栈与堆空间分配 (在不使用标准库中的malloc时,堆空间被优化)
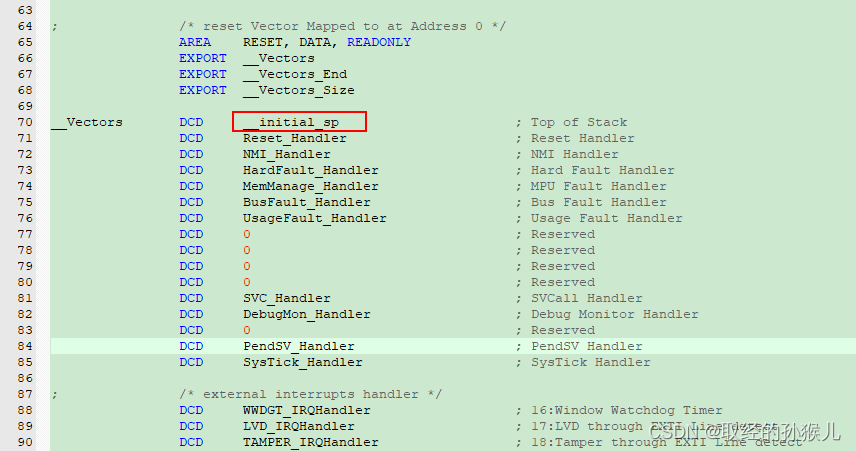
- 中断向量表
-
复位处理函数
- SystemInit : 初始化时钟,初始化中断向量表偏移
- __main
- 将未初始化内存区(.BSS or ZI)清零
- 调用下面的堆栈初始化函数 __user_initial_stackheap
- 进入main函数

- 堆栈初始化函数

复位过程

中断向量表的存储地址 0x08000000 + 4 , 0x08000000存储的为MSP的值 , ARM会将flash的0地址自动映射到 0x8000000。这里有一个需要思考的问题, 为什么需要将MSP的初值放到0地址?这个初值又是多少?原因如下:
在Reset_Hander中 , 首先会调用 SystemInit 函数,这是一个C函数,且函数里边还会调用其他函数,此时汇编文件中的栈还未进行初始化(_main), 因此需要一个栈空间来保存函数调用过成,仿真可发现 初值MSP是一段内存0x20000000很靠前的一个地址,MSP会零时使用此值,待SystemInit 执行完后归还,在调用 __main后 MSP的值初始化成map文件中的值。
数据结构-栈
走迷宫的过程:
- 每次经过一个分叉口 , 给分叉口一个编号 , 选择一个岔路口走下去
- 循环上诉过程,直到走出迷宫,或者走到死路
- 若走到死路,则根据记录的信息,回退到上一个岔路口,走之前未选的岔路 , 循环直到走出迷宫或者走到死路
- 重复此过程,直到找到出口
/*函数调用过程与走迷宫类似,下面的函数 func1在执行过程中 , 会打断当前执行流程,去执行func2 , 去执行func2前,应该记录当前func1的执行环境,如记录c的值 ,记录参数a和b , 当func2执行完后,要退回func1继续执行*/uint16_t func1(uint8_t a , uint8_t b)
{uint16_t c = 0;c = a + b; /*a 和 b 作为参数 通过 R0 和 R1传递 , 计算结果会存在 R0 , R1 , R3*/func_2(c); /*在跳转执行func2 前 , 参数 a ,b ,c 需要保存 ,*/return c;
}void func2(uint16_t d)
{uint32_t e;e = d*d +2*d;
}
栈在内存中的地方
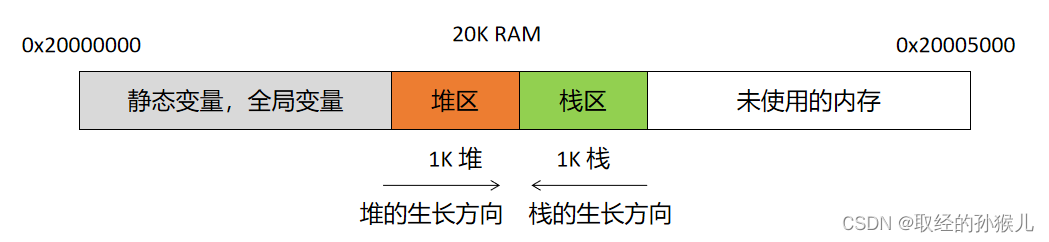
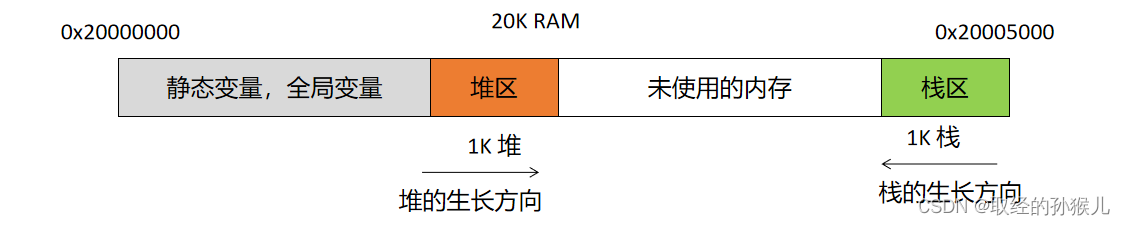
函数调用过程中栈帧结构
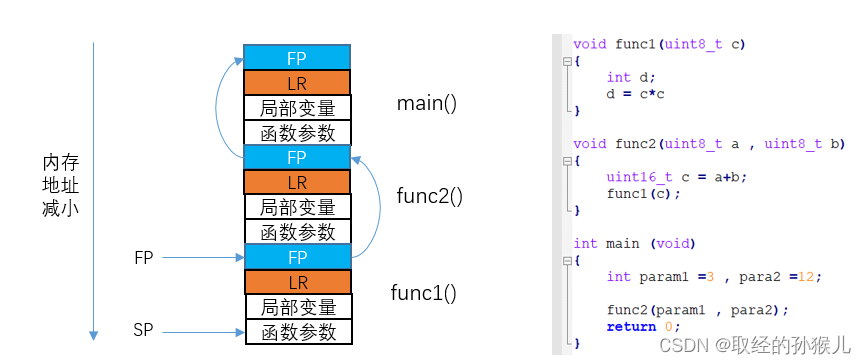
如上图所示,函数调用过程 为 main -> func2->func1 , 最终执行到 func1中后 栈的结构如图 ,下图表示函数func2的栈帧
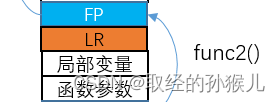
- FP 栈帧底部,用于返回查找,FP将所有的栈帧构建成一个链表
- LR 连接寄存器,保存了函数退出后的下一个PC地址,用于函数返回
- 局部变量:函数中定义的局部变量
- 函数参数:当函数参数大于4个 ,大于的部分需要入栈,其余通过R0-R3传递
示例一:无参数,无返回值的函数调用
可以看到左边为C 程序 ,右边为其对应的汇编程序 , 看到汇编可能会慌张,但其实观察可以看到 , 只是在重复几条指令而已。
mov R0 , #1 ;将立即数1(也就是常数)写入到 R0 , MOV只能赋值8位的数值,32位的需要用伪指令LDR
ldr R3 , [fp,#-8] ;将 [FP-8] 内存地址的内容加载到 R3
str R3 , [sp,#-12] ;将 R3的值写入到 [FP-12] 内存地址
add fp , sp ,#0 ; fp = sp + 0
sub sp , sp ,#28 ; sp = sp - 28
push {fp ,lr} ;使用 push 指令是 默认从左往右依次入栈(但是R0-R12通用寄存器会先入大的编号) , ;栈指针 sp 会自动"增加" , 压fp 和 lr 则 sp = sp -8 (思考为何是减而不是加)pop {fp} ;pop 指令会将栈内数据依次弹出 , 赋值给{}内的寄存器 , 同时栈指针会自动"减小"
bl <func> ; 跳转指令 ,调整PC指针到对应的跳转地址 , 并且自动将跳转地址的下一个地址写入到 lr 寄存器
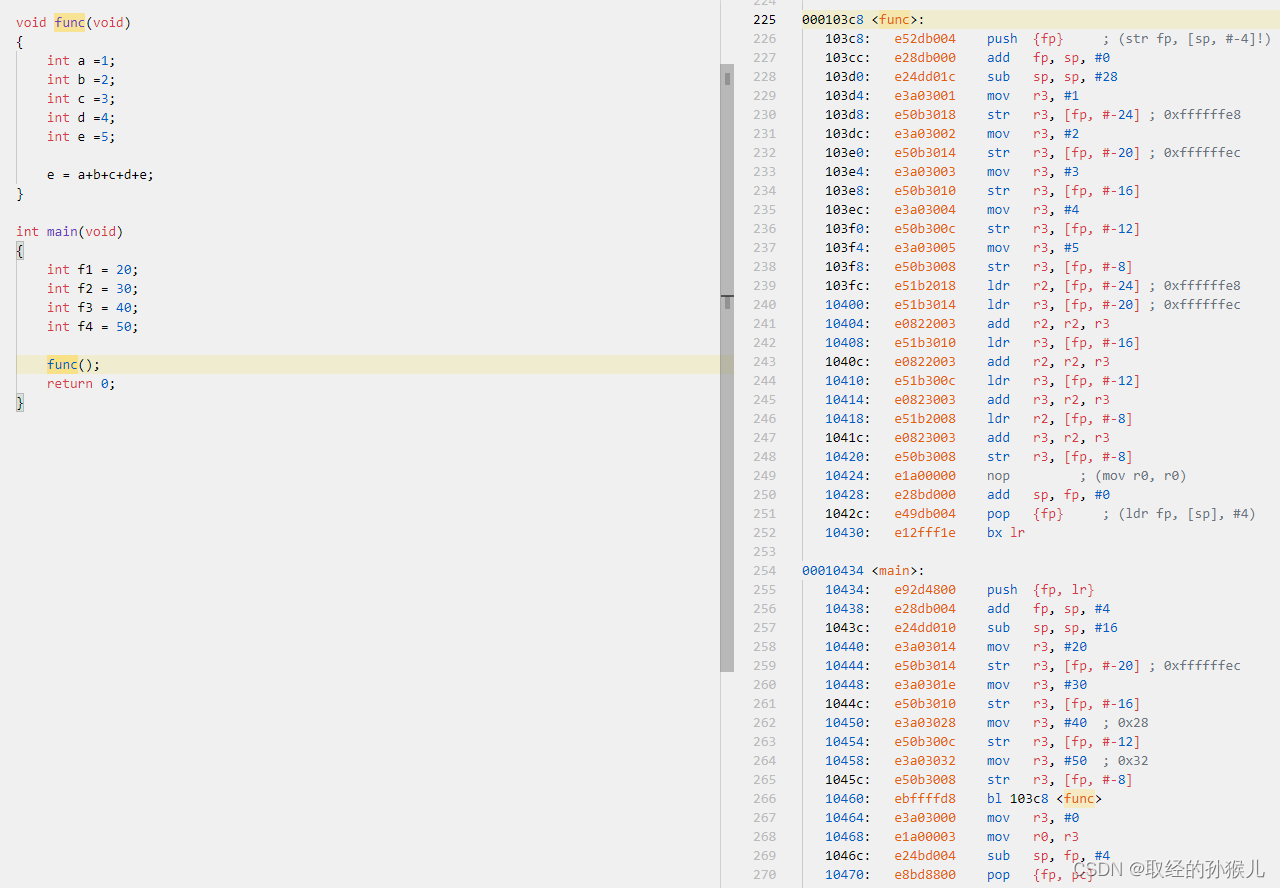
sp我们知道是栈指针 , 每次使用 push 指令,sp都将自动生长(减小,栈是向低地址方向生长),每次使用pop指令时,sp都将增大。fp是什么呢,它是frame point的缩写 , 直译过来就是栈帧指针。我们在进入main 函数后,sp和fp都指向栈底,此时栈是空的,如下图所示。

从main函数的汇编开始分析

我们假设栈底在内存中的地址是 0x20005000 ,栈的大小为 1K 。 在执行 push {fp , lr} 后,栈的变化情况如下(当栈是空的时使用push指令sp的偏移会少一个单元,如下图,push两个单元进入,正常sp = sp-8 ,但这里是sp=sp-4 , 只要记住一点,sp指针永远指向栈顶,这里就是lr所在地址):
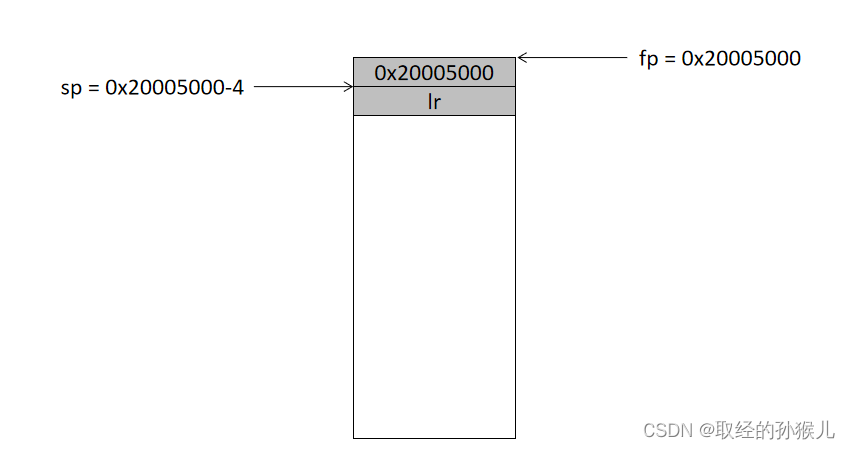
接下来的 两条指令 add fp , sp , #4 和 sub sp , sp , #16 执行后的结果为,这个16的由来是因为main函数里有4个局部变量需要存到栈中。
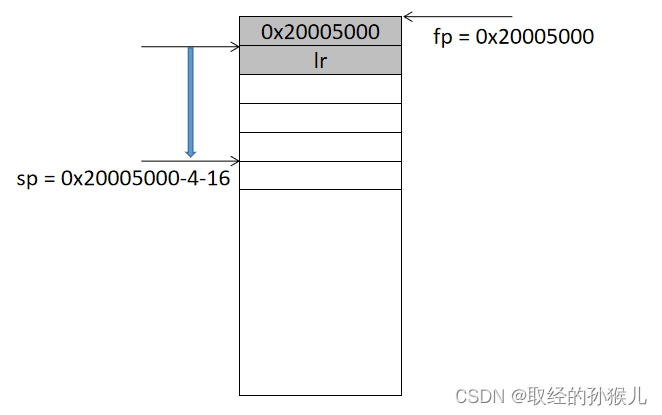
接下来就是一直到 bl 跳转前,都是让局部变量入栈,注意局部变量的入栈顺序,最先定义的局部变量反而最后入栈 , fp指针和sp指针之间我们称为main函数的栈帧。
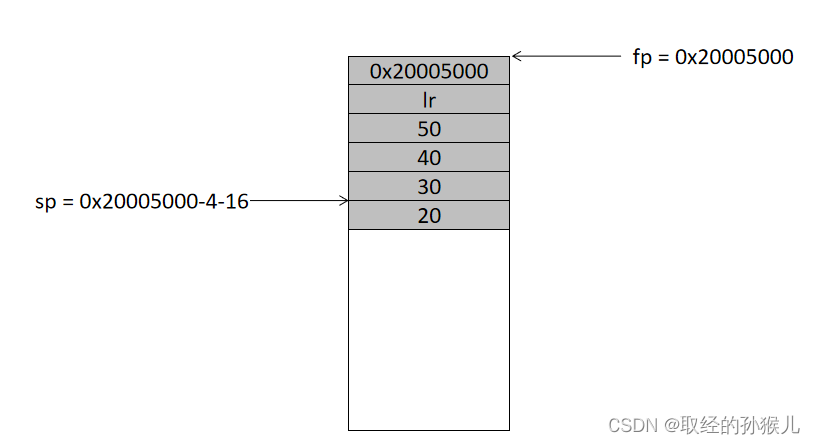
接下来跳转到 函数func , 具体看右侧注释过程,可以分为4个部分 , 我们分别将4个过程 栈的变化情况用图形表示出来
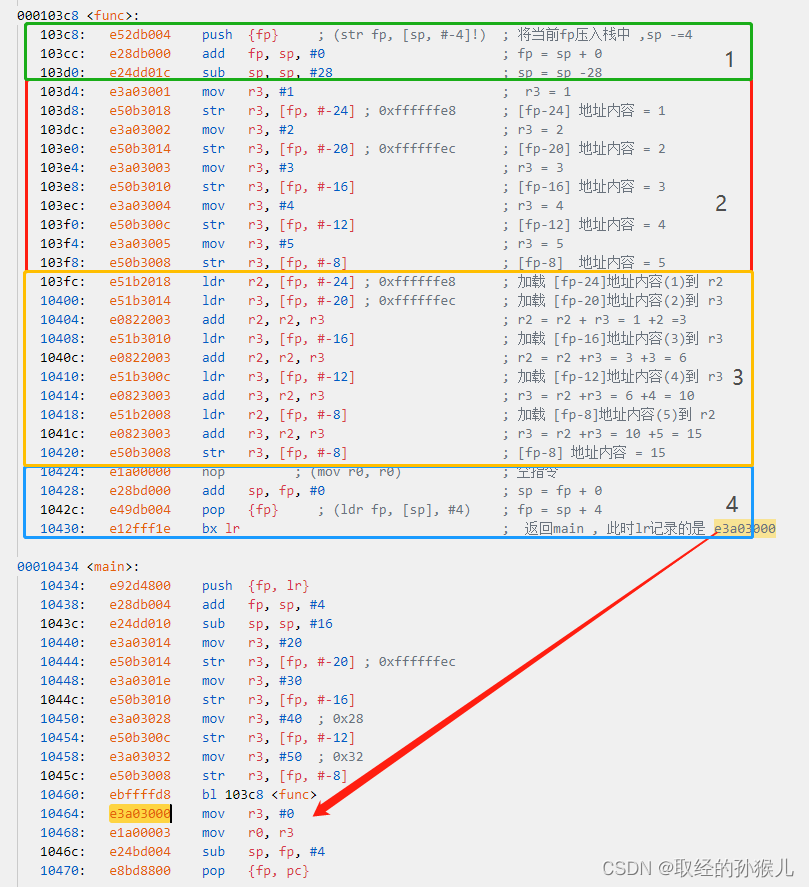
第一部分,划分出函数func 的栈帧空间(移动fp 和sp) , 这里有一点需要注意,在main函数中,定义了4个局部变量,在分配栈帧空间时,刚好分配4个32位空间来存储4个整形的 , 而在func 中,有5个整型局部变量,但这里却分配了6个单位(4*6=24字节),因为栈空间需要8字节对齐。一般我们都是熟悉的4字节对齐,但是由于浮点数的原因 (double)需要8字节 , 所以使用8字节对齐。还有一点与main函数的栈帧不同 , func函数的栈帧未将lr 寄存器入栈,因为func函数已经是调用最深的函数 , 它内部没有其他调用函数,因此lr的值不会变,当函数执行完后 , 直接令 pc = lr 即可返回。
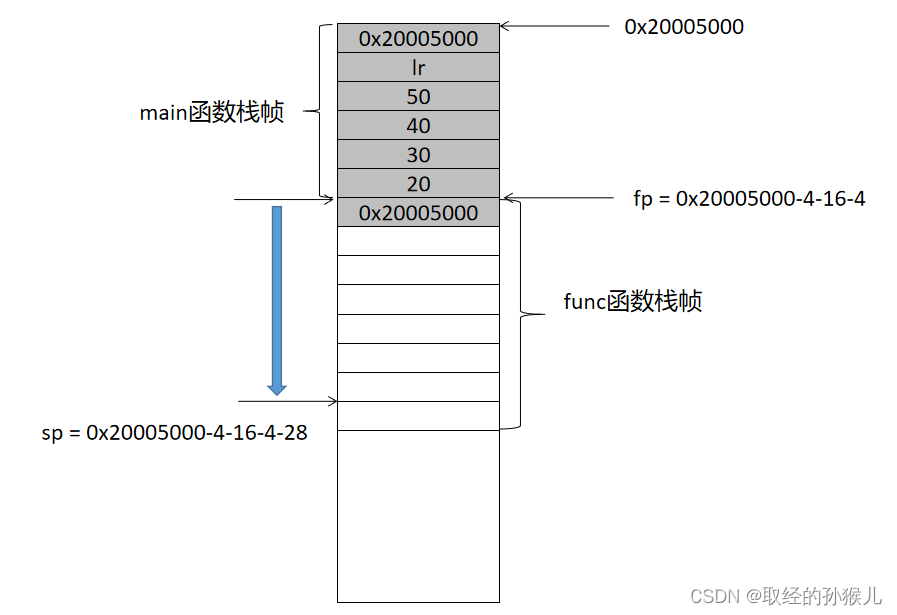
第二部分,func函数的局部变量入栈
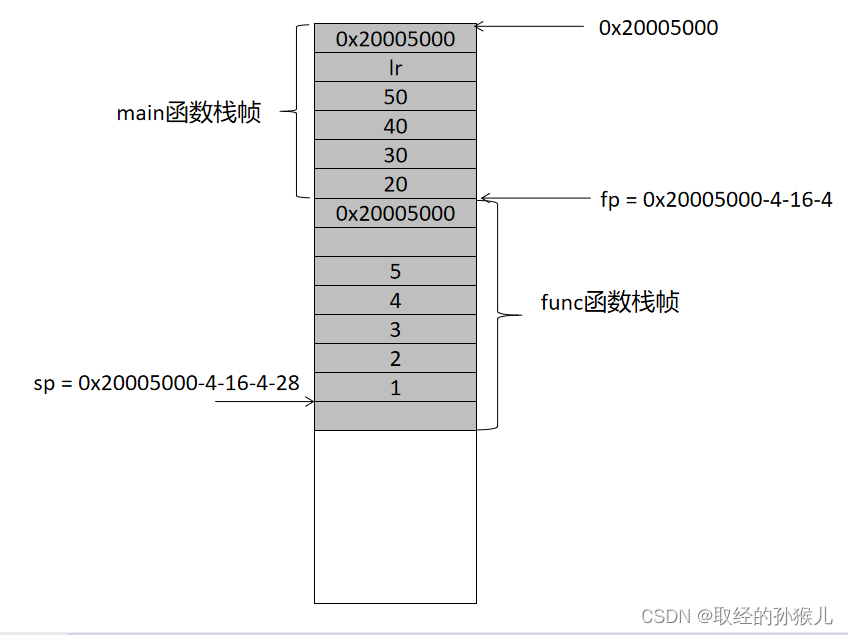
第三部分,依次求和,最终将就和结果保存到e , 也就是上图数值5的地方。
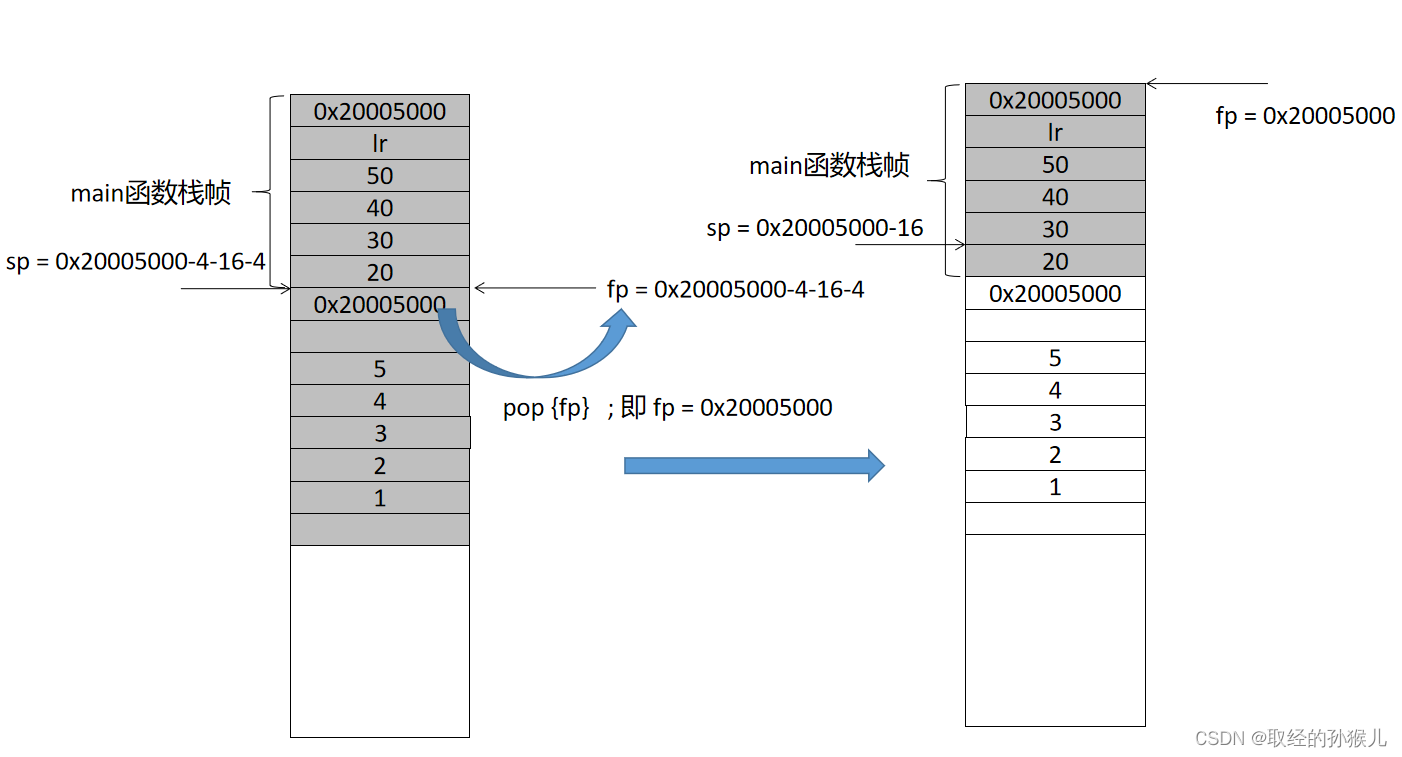
第四部分,出栈,首先调整栈指针 sp = fp + 0 , 在弹出保存的main_fp = 0x20005000 到 fp 指针 ,sp指针因为pop操作上移一个单元。最终的栈空间如下图右侧部分。虽然func的值依旧保留 , 但是由于sp 的值改变,当再次使用push压栈时,将覆盖旧值。func函数没有返回值 , 所以直接跳转到main 函数。也就是bx lr 。 还记得lr 保存得内容吗。在使用bl 指令时 , 会将bl 的下一条指令的地址自动写入 lr 寄存器。所以 返回时就可以接着执行了。
中断发生后栈的变化
中断和函数调用的区别在于中断任何时刻都可能发生,发生中断后,需要保存现场环境,然后执行中断服务函数,执行完后,需要恢复现场环境。从寄存器组章节可知,和当前环境相关的寄存器有 8个 ,这8个寄存器硬件上会按以下顺序自动入栈 ,若中断服务函数中还有局部变量或函数调用,按栈帧形式继续入栈
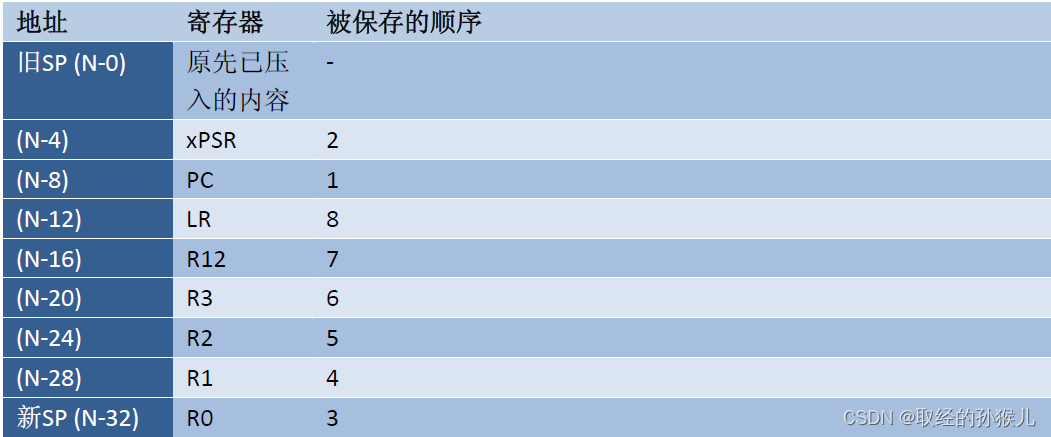
HardFault 问题查找步骤 : 发生HardFault时 ,当前PC 和 LR参考意义不大 ,应该根据当前SP指针的地址 , 获取此8个寄存器的值 ,其中PC为发生异常时的PC,
LR为发生异常代码所在函数的下一条执行的代码 , R0-R4 为过程值 ,可能为参数 ,返回值 ,内存加载值等等 ,具体依靠PC和LR能分析其内容。
以下为实际发生HardFault的Jlink读取情况
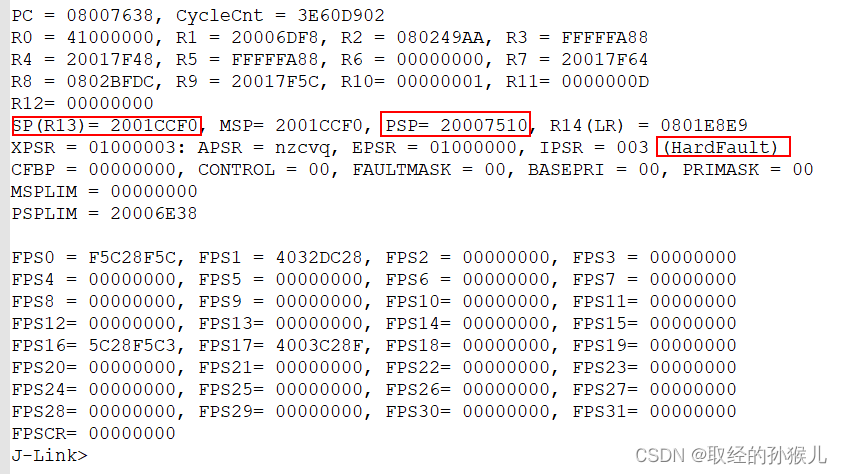
根据PSP(裸机使用MSP) 查找发生 入栈的 8个寄存器 PC : 0x080249AA LR:0x0801E895
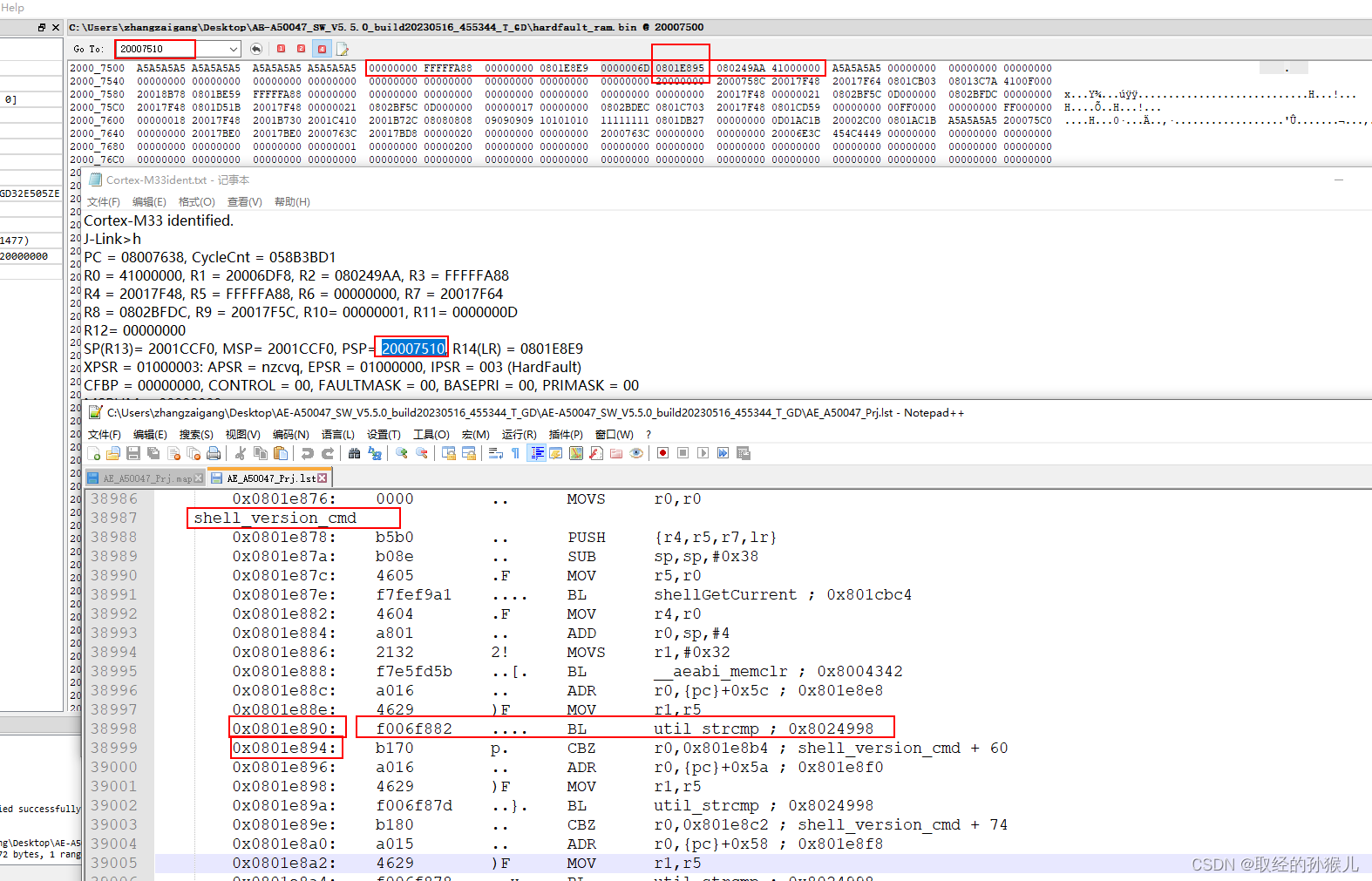
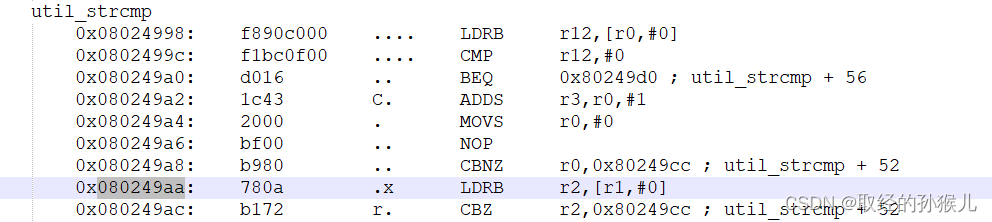
最终定位到发生问题的函数: shell_version_cmd --> unti_strcmp --> LDRB r2 ,[r1,#0] 。 进一步分析原因可继续追溯栈的内容,查出 until_strcmp 参数输入内容,最终发现为until_strcmp 的第二个参数在出异常是为非法地址,访问非法地址导致HardFault
深入理解中断
中断输入和悬起行为
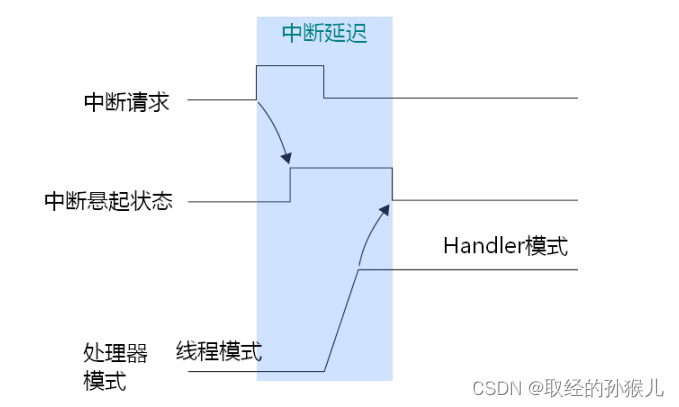
我们使用外部中断的高电平触发方式来解释中断的过程 , 如上图中断请求表示外部输入引脚高电平持续的时间 ,内核检测到中断请求后,将悬起对应的中断(中断标志置位) , 中断悬起后,可能不是立马执行服务程序 , 比如当前在临界区,退出临界区后,处理器模式切换成Handler 模式,并开始执行中断服务程序,清除中断标志,执行完成后 ,退出服务,处理器模式切换成线程模式。若中断请求不是期望中的只请求一次能,比如一直存在请求 , 多次间断请求等又会是怎样的情况呢
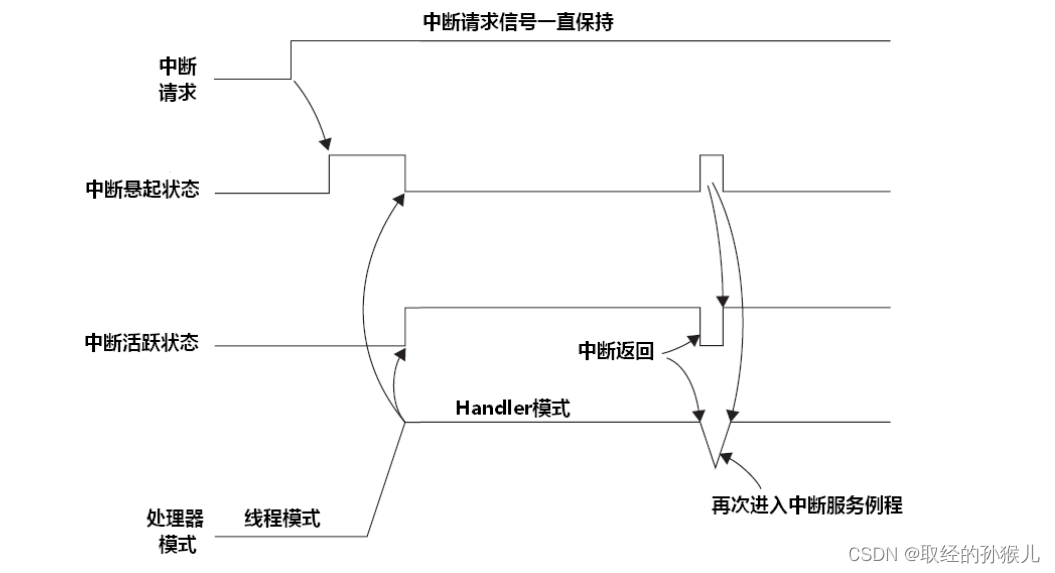
请求信号一直保持
首先中断悬起后,只会在服务程序中清除 , 因此在清除了悬起后,等待中断返回 , 由于请求信号一直有 ,中断会再次被悬起,然后再次执行中断服务程序。
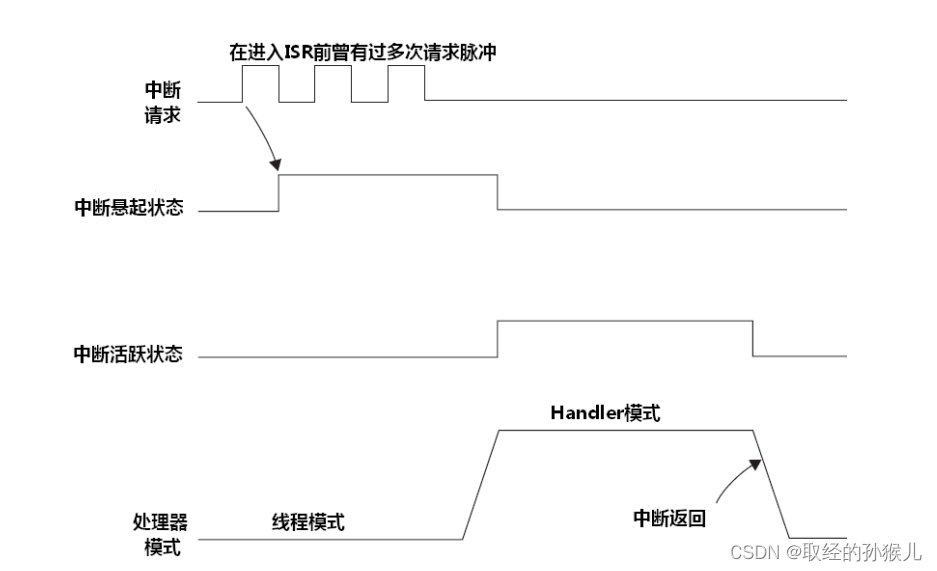
执行服务前多次请求
因为在第一次请求时中断就被悬起,且在下次请求前没有进入服务程序清除悬起,因此只会执行一次中断服务。
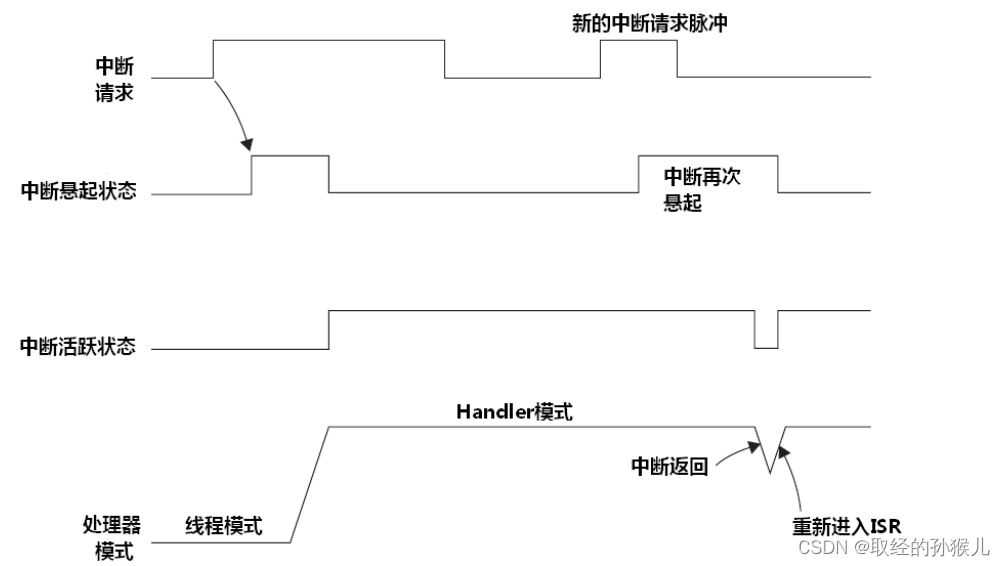
执行服务后再次请求
在下图中,进入中断服务程序后,悬起状态便被清除,但是还未退出中断后,中断请求再次到来,此时中断被再次悬起,且在服务程序退出后,立即又执行中断服务程序,这里内核会取消退出服务程序的出栈,以及进入服务程序的入栈(后面会具体介绍),这种中断情况称为:中断咬尾
中断优先级分组
在配置中断前 ,我们首先需要设置的就是优先级分组 , 然后设置抢占优先级和从优先级 , 数值越小优先级越高 , 类似下面的配置:
//选择使用优先级分组第1组
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_1);// 使能EXTI0中断
NVIC_InitStructure.NVIC_IRQChannel = EXTI0_IRQChannel;
NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 1; // 指定抢占式优先级别1
NVIC_InitStructure.NVIC_IRQChannelSubPriority = 0; // 指定响应优先级别0
NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;
NVIC_Init(&NVIC_InitStructure);// 使能EXTI9_5中断
NVIC_InitStructure.NVIC_IRQChannel = EXTI9_5_IRQChannel;
NVIC_InitStructure.NVIC_IRQChannelPreemptionPriority = 0; // 指定抢占式优先级别0
NVIC_InitStructure.NVIC_IRQChannelSubPriority = 1; // 指定响应优先级别1
NVIC_InitStructure.NVIC_IRQChannelCmd = ENABLE;
NVIC_Init(&NVIC_InitStructure);
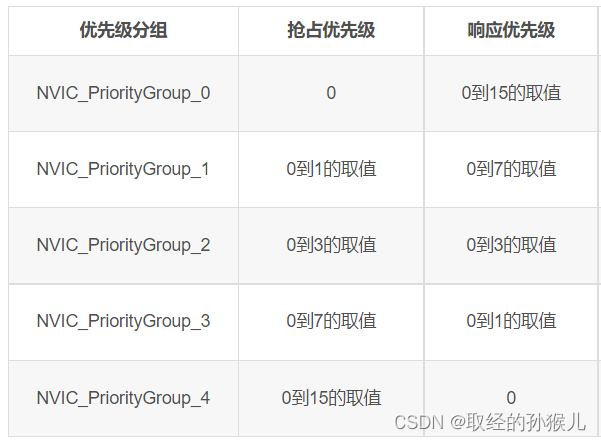
首先是分组 , 如上表,分组决定了抢占优先级和从优先级 (响应优先级)的取值范围 。抢占优先级好理解,抢占优先级高的中断可以打断抢占优先级低的中断,响应优先级呢? 在两个中断的抢占优先级相同时 , 它们不具备抢占功能。这时若两个中断同时到达 , 则按照从优先级的高低决定先执行哪个。 中断的同时到达很容易产生误解,同时触发?网上很少有详细解释这一点的 , 同时触发的机率是很小的(如外部中断同时触发),不管误差有多小总有个先来后到 , 如果只是这样,还有必要设计从优先级吗 , 概率极小,多数情况有个先来后到,完全可以像RTOS 线程优先级只一个抢占优先级那样处理。 在了解了中断悬起行为后 , 就能理解,为什么需要从优先级。通过下图理解所谓的中断同时到达。
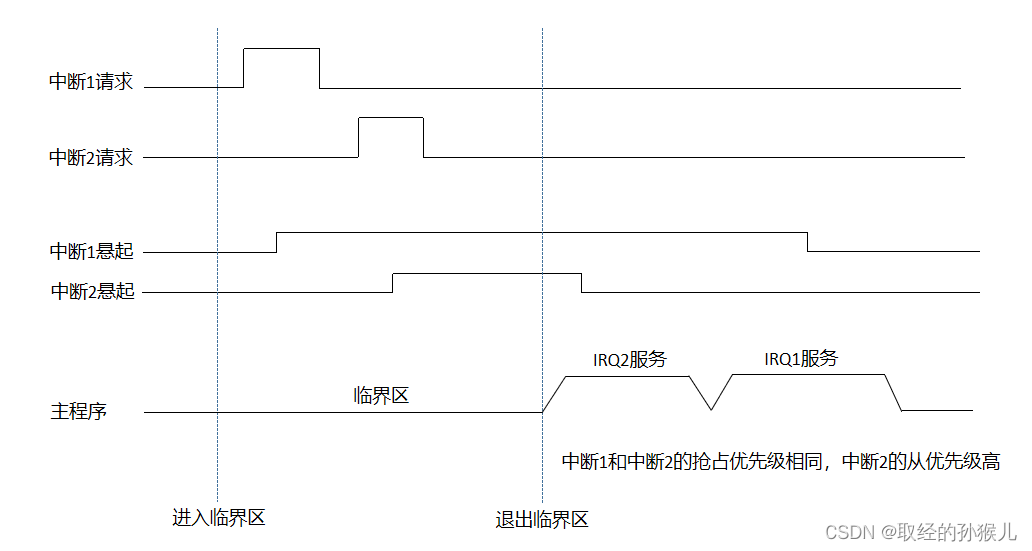
从上图可以看到,在进入临界区后 , 中断1的请求先到达 , 所以中断1先被悬挂 , 但是此时无法执行服务程序,中断2随后到达,也被悬挂,也无法执行。在退出临界区后 , 由于中断2的从优先级高 , 所以先得到执行,因此上面说的两个中断同时到达 ,并不是说中断同时请求 , 而是在执行服务前,存在两个相同抢占优先级的中断同时处于悬挂状态,这时根据从优先级决定先执行谁。
中断咬尾
在上面的相同抢占优先级,不同从优先级中 , IRQ2 服务和 IRQ1 服务 按一般的中断流程,在执行服务程序前需要保护现场(入栈),在退出中断服务程序前要恢复现场(出栈),但是上面的这种情况是可以省略这个过程的 , 因为栈的数据在这个过程中没变化(主程序没来得及执行,之前保存的现场未发生改变,另一个中断服务又开始了),将数据取出来,然后一模一样的又存进去完全没必要 。这样看起来就像是前一个中断的尾巴(出栈)被下一个中断咬住(去尾去头将两个中断连在一起), 咬尾中断有效的减少了中断的延迟。
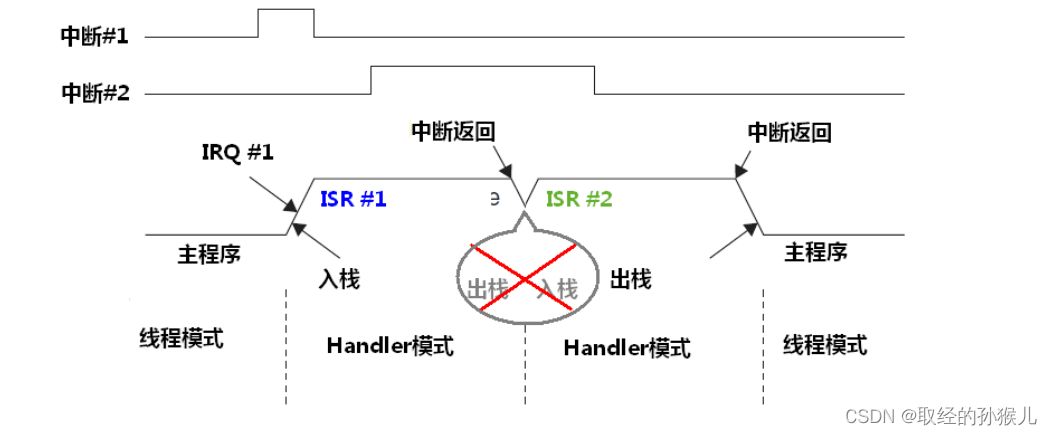

中断的具体行为
前面我们介绍了中断的请求与悬起 , 中断过程中处理器的模式和特权等级的变化。但是具体过程没有说明,比如中断过程寄存器是如何变化的 , 在中断跳转前,要进行哪些操作 ,中断返回后有需要哪些操作。理解了中断的具体行为,就能解释为何要求不要频繁进入中断。
入栈
在响应中断前,最先做的就是保护现场 ,比如当前正在计算 c = a + b , 我们已经将 a 的值从内存中加载到 R0 , 将 b 的值加载到 R1 然后进行了求和运算 , 并把结果存在R0中 , 若a , b 特别大,特殊功能寄存器程序状态字中的进位标志会被触发 , 此时还没有将结果从R0 写入到内存中(c在内存的地址),发生了中断,在中断中,可能会有运算,或者函数调用,也会用到R0-R15 以及特殊功能寄存器,但是前面的运算还没有结束 , 不能破坏了现场 ,不然中断返回后,就不能接着执行了 , 这时就需要保存寄存器中的值 , 保存到哪里?保存到栈中 , 栈在哪里?栈在内存中。由于我们做运算或者加载写入数值,函数调用一般只会用到 R0-R3 ,因此,R0-R3 ,R12(内部调用暂时寄存器 ) , R14(连接寄存器LR) , 程序状态字寄存器XPSR , PC 等将会被硬件自动保存到栈中 , 若用到了R4-R11 ,则需要用PUSH 指令手动保存。这些在第二部分会有详细介绍。 还有一点要注意,到底是 入哪个栈 , MSP 还是PSP , 裸机系统我们一般只使用MSP,而RTOS中线程会使用PSP 。
取向量
在入栈的同时 , 指令总线会获取程序状态字中的异常号 ,在中断向量表中查询对应的 中断服务地址入口。
寄存器更新
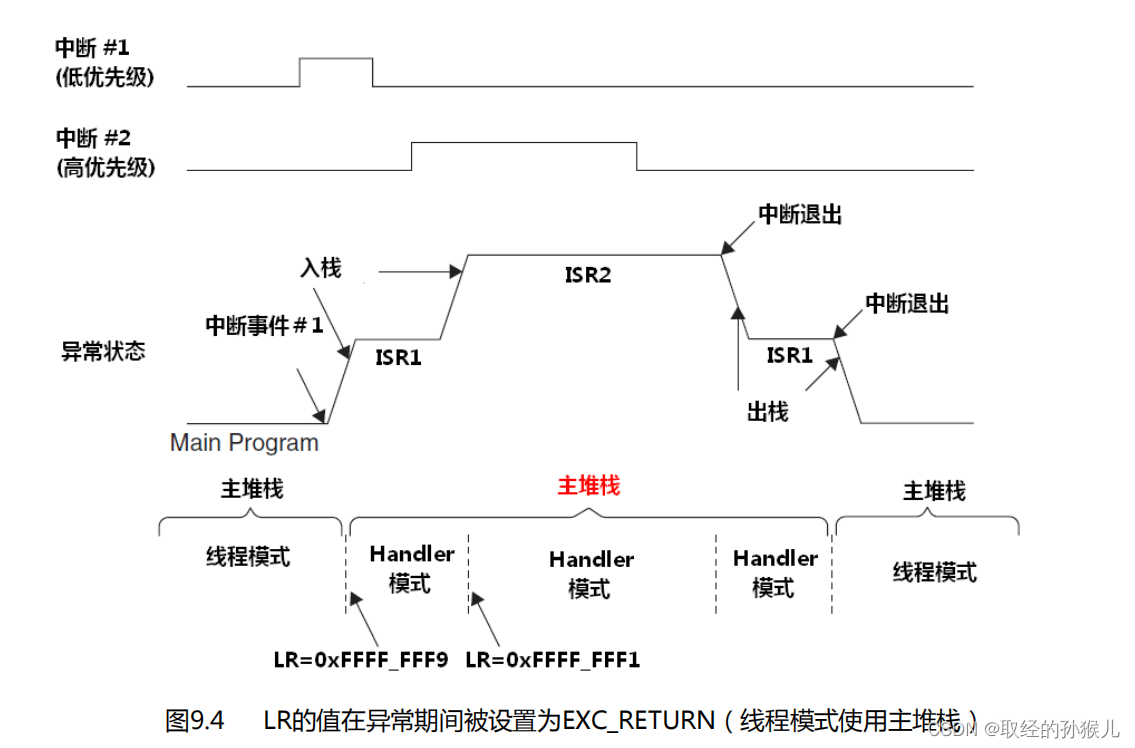
更新栈指针SP , 选择栈指针 MSP, 更新连接寄存器LR , 程序计数器PC,在入栈完成后,栈指针会更新(PSP或者MSP因为压栈操作而生长), 在执行服务程序时,将由MSP 负责对堆栈的访问。更新LR 比较特殊,前面我们说过LR 寄存器在函数调用过程中的作用 : 它记录了被调函数的下一条指令地址,这样函数返回后就可以继续执行。但在中断服务中LR 会有特殊的用法 ,在进入中断服务程序后 , LR 会被计算赋值为 EXC_RETURN (异常返回)
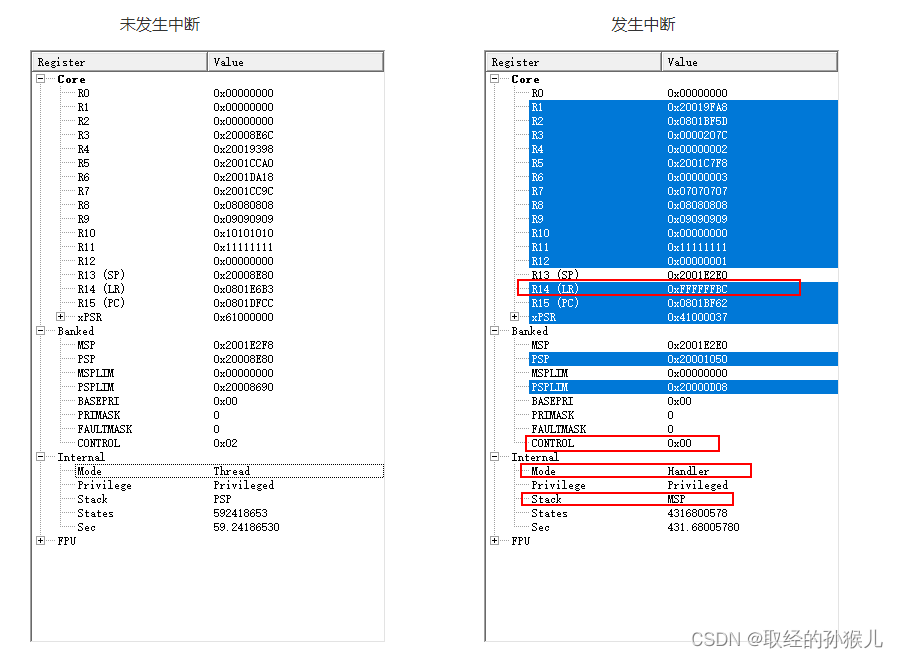


LR的取值只有以上3种(以上为CM3的异常返回,其余需要找对应的ARM核) , 他能修改中断服务返回后的模式和使用哪个堆栈指针 , 还记得CONTROL 寄存器吗 它在特权模式下,也能修改模式和选择栈指针。只不过,CONTROL 寄存器是主动修改 , 这里的LR 值是系统自己判断的 , 判断依据如下:
- 主程序在线程模式下 , 并且使用MSP 被中断 , 则 EXC_RETURN 的 值为 0xFFFFFFF9 (裸机系统为这个)
- 主程序在线程模式下 , 并且使用PSP 被中断 , 则 EXC_RETURN 的 值为 0xFFFFFFFD (RTOS系统为这个)
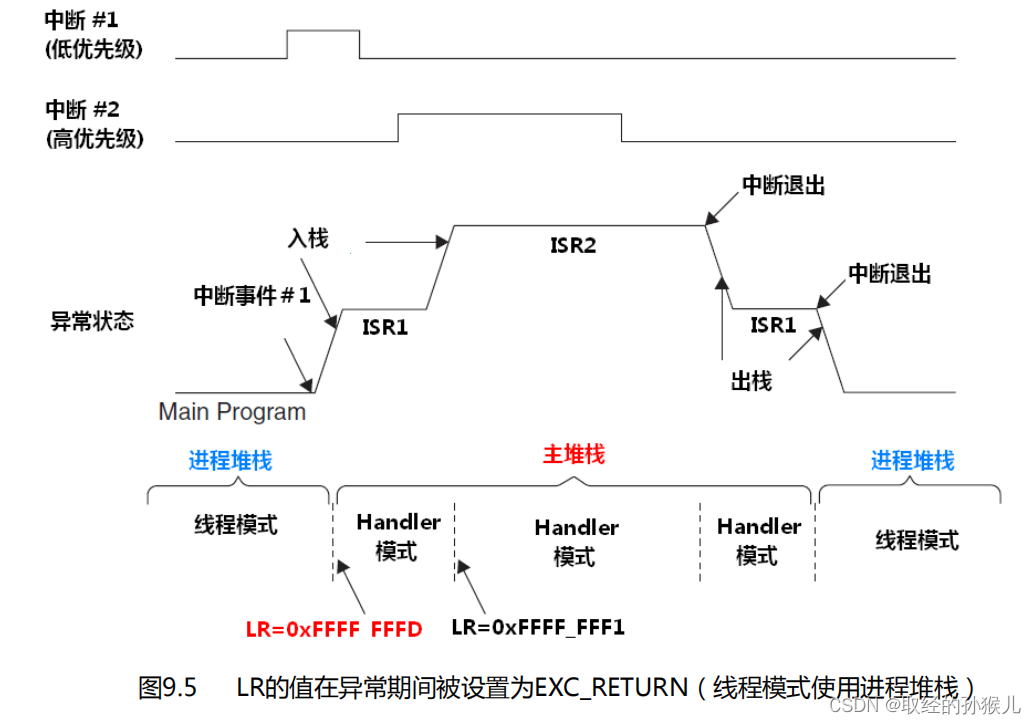
异常返回时,只需要令PC 等于 LR 即可, 系统会自动切换模式 和 选择栈指针 , 并且从栈中恢复先前寄存器的值(包括PC重新回到打断的地方)。可以看到,中断始终使用的是主堆栈 , 因此中断的嵌套深度,局部变量,函数调用都会消耗主堆栈,在RTOS设计时,不仅需要考虑每个线程的栈空间大小,还需要考虑主堆栈的空间大小。
调度器
为什么需要调度器
实时性
在顺序执行结构中,常见的任务处理模式如下:
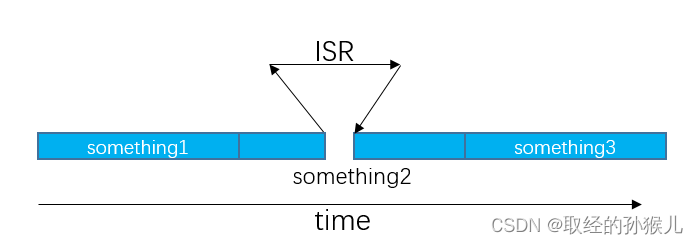
int main(void)
{while(1){do_something1();do_something2();do_something3();}
}
void ISR(void)
{do_something4();
}
可以发现,每一个任务的执行都受其余任务执行时间的影响,虽然有任务放在中断中执行 , 但其余非中断任务实时性得不到保证。为了提高实时性,基于一个事实,一般任务都有一个执行周期,比如按键检测任务,可以5ms扫描一次,显示任务可以50ms 刷新一次 ,传感器采集任务可以500ms采集一次。
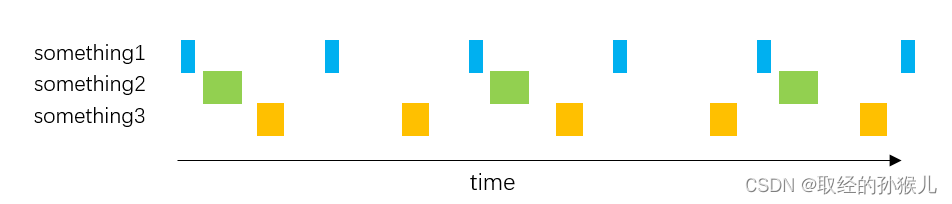
int main(void)
{while(1){if(Timer5ms_flag){do_something1();}if(Timer10ms_flag){do_something2();}if(Timer8ms_flag){do_something3();}}
}
void ISR(void)
{do_something4();
}
按照上述方式 , 由于将各个任务指定执行周期 , 在同一时刻让任务就绪错开 , 这样单个任务的实时性得到了提高。
按上述方法,实时性有一定的提高,多数情况下不会出现多个任务就绪的情况,但是极端情况下也会出现,如某个任务执行时间过长或执行时间不确定,破环了上图的任务错开时间运行的平衡 , 或者周期互为公约数,且启动时时间未使用质数错开 ,最终会出现类似 “共振”的现象,隔一段时间多个任务同时就绪。
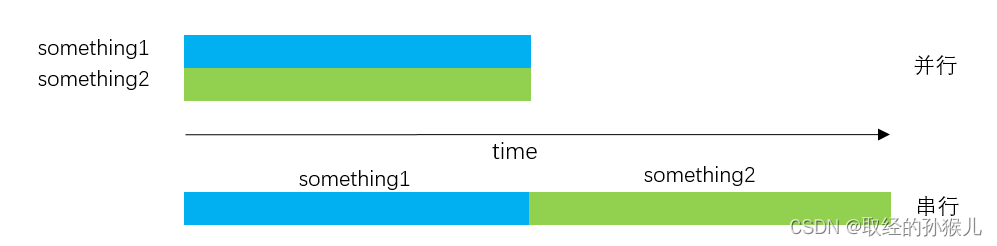
多个任务同时就绪 , 我们更期望的时并行处理,而不是串行,如上图所示。但是MCU为单核,无法并行处理,为了实现类并行处理,时间片轮转调度由此而生。

时间片即任务允许执行的最长时间,时间到了就需要切换到下一个任务执行,时间片轮转需要考虑的是任务执行时间到了,如何切换到下一个任务,如何保存当前任务执行环境,如何恢复下一任务的执行环境等,当前主流的RTOS都支持时间片调度。虽然任务切换会消耗一定的时间,但是任务本身在时间片足够小时,几乎可以任务是并行执行。
解耦合
调度器能提供统一的接口,管理任务执行时序,避免了各种就绪标志位胡乱分布耦合。后文中将介绍几种常见的调度器实现,可以发现基于调度器框架开发的优势
裸机下的调度器
使用软件定时器实现调度
/***************************************************************************//*** @brief 设置ctimer定时器* @details ** @param[in] period 运行周期* @param[in] counter 运行次数* @param[in] p_func 函数指针* @param[in] p_arg 函数* @return 分配的定时器指针,如果没有定时器分配,返回NULL** @note * @see * @warning ******************************************************************************/
struct ctimer* ctimer_set(UINT32 ulPeriod, UINT32 ulCount, void (*pfFunc)(void* p), void* pArg);
void ctimer_mainloop(void);
void task1_process(void* pArg)
{}
void task2_process(void* pArg)
{}
int main(void)
{ctimer_set( 5, 0 , task1_process, NULL);ctimer_set( 20, 0 , task1_process, NULL);while(1){ctimer_mainloop();}
}
使用事件驱动的调度器
- QP状态机框架: https://www.state-machine.com/
/********************************************************************
upgrade fsm:<--------------------------------------------------/ \ \idle -----> info ----->transfer ------------> finsh \\ \ \\ \ \--------------------------------------->error*********************************************************************/
R_state_t ecu_upgrade_state_idle(fsm_t* me, uint32_t evt)
{switch(evt){case SYS_ENTER_EVT:{log_d("enter idle state");memset(&upgrade_info , 0 , sizeof(struct ecu_upgrade_info));return S_HANDLE();}case ECU_UPGRADE_REQUEST_EVT:{return S_TRAN(ecu_upgrade_state_transfer);//return S_TRAN(ecu_upgrade_state_info);}default:{return S_IGNORE();}}
}
R_state_t ecu_upgrade_state_info(fsm_t* me, uint32_t evt)
{switch(evt){case SYS_ENTER_EVT:{/*step1: session control*//*step2: security_access*//*step3: file_download request*//*period: tester present*/fsm_set_timeout_evt(me , 3000 , SYS_TIMEOUT_EVT);return S_HANDLE();}case SYS_TIMEOUT_EVT:{/*period: tester present*/fsm_set_timeout_evt(me , 3000 , SYS_TIMEOUT_EVT);return S_HANDLE();} default:{return S_IGNORE();}}
}
...
- OSAL事件驱动框架 :https://github.com/recheal-zhang/ZStack-CC2530-2.3.0-1.4.0/tree/master/Components/osal
/***********用户任务事件处理函数***********/
uint16 SimpleBLETest_ProcessEvent( uint8 task_id, uint16 events )
{VOID task_id;if ( events & SYS_EVENT_MSG ){uint8 *pMsg;/* 读取发送来的消息 */if ( (pMsg = osal_msg_receive( SimpleBLETest_TaskID )) != NULL ){/* 消息有效数据处理函数 */simpleBLETest_ProcessOSALMsg( (osal_msg_send_dat *)pMsg );/* 清除消息内存 */VOID osal_msg_deallocate( pMsg );} return (events ^ SYS_EVENT_MSG); }if ( events & SBP_START_DEVICE_EVT ){/* 每500毫秒发送一个事件 */if ( SBP_PERIODIC_EVT_PERIOD ){osal_start_reload_timer( SimpleBLETest_TaskID, SBP_PERIODIC_EVT, SBP_PERIODIC_EVT_PERIOD );} return ( events ^ SBP_START_DEVICE_EVT ); }if ( events & SBP_PERIODIC_EVT){ static uint8 byTmp = 0;if(byTmp > 7) byTmp = 0;/* 发送消息及有效数据 byTmp */osalSendUserDat(byTmp++);return (events ^ SBP_PERIODIC_EVT);}return 0;
}基于硬件定时器调度器
基于时间或事件的调度器已经能处理绝大多数裸机的应用情况 , 但有些特殊场景,上述两种调度器无法满足实时性。裸机的实时性需要靠中断来保证,上面两种调度器的本质都是定时产生就绪标志 ,然后在主循环里轮询标志 , 标志满足则执行,虽然任务错开时间运行对响应速度有一定的提高,但是还是避免不了排队执行,若某个任务本身的执行时间非常长,比如1S才能执行完,即使其执行周期长,但是在他执行时,其他任务都需要排队。
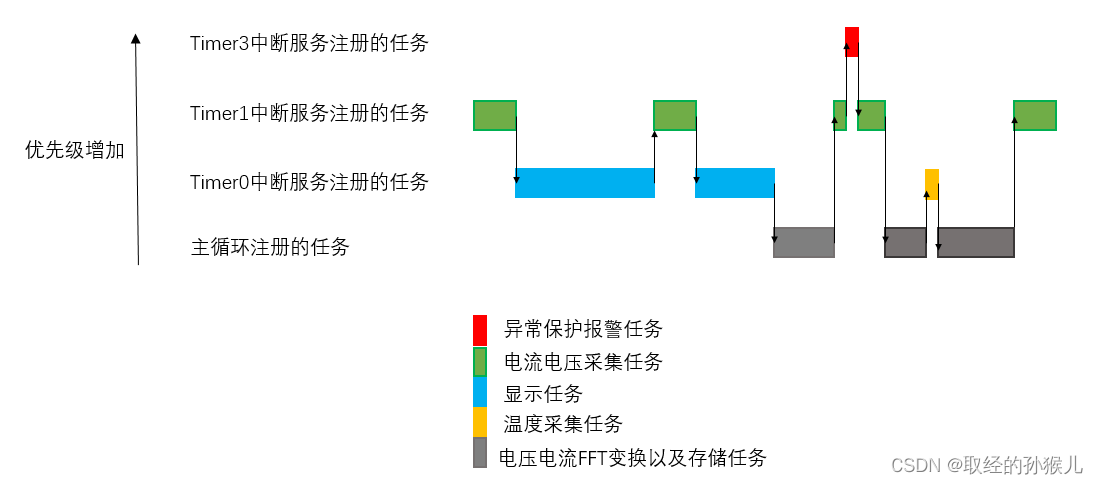
需求描述:
- 在仪器仪表行业,一般使用低端MCU (主频16MHZ),无法提供足够资源 跑 RTOS
- 如供电线路检测仪表,可能需要实现,线路电压采集,电流采集,温度采集 ,显示,无线传输等任务
- 要求 50ms 采集一次电压电流 , 1s采集一次温度,500ms刷新一次显示
- 采集的电压电流进行 FFT变换,并将结果存储到外部SPI flash
- 温度,电压,电流异常预警 , 从检查到异常发生,需要在 10ms内控制继电器断电,报警鸣笛
需求拆解:
- 16MHZ主频跑 FFT极其耗时间,在无硬件加速情况下,执行一遍可能到达秒级
- 电流电压50ms采集 是硬要求,异常初始优先级最高,须立即处理
- 电压电流 FFT变换对实时性要求不高,只是需要保存,类似一个历史数据,可供回查。
以上需求若使用上面两种调度方式无法满足实时性,需要使用主动中断的方式强行切换任务,处理流程如下图:
/*
创建任务:1)定义任务句柄2)定义任务处理函数 3)定义任务类型:周期任务或触发任务4)定义任务优先级 (根据任务优先级,任务处理函数会被注册到不同的硬件定时器)
*/int task_create(TaskHander_t handle , TaskCallBack_t cb , uint8_t type , uint8_t prior);/*
启动某个任务的调度1)任务句柄:根据任务句柄,能得知任务优先级,处理函数等,然后启动对应的定时器2)延时多久执行任务调度
*/
int task_schedule(TaskHander_t handle , uint32_t time);/*
停止某个任务的调度1)任务句柄:根据任务句柄,能得知任务优先级,处理函数等,然后启动对应的定时器2)延时多久停止任务调度
*/
int task_schedule(TaskHander_t handle , uint32_t time);
RTOS调度器
在裸机的几种调度器中,时间与事件调度器的本质是相同的,都是设置任务的就绪标志,在主循环里边查询就绪标志,执行就绪任务,而基于硬件定时器的调度器相较于前两者增加了抢占功能,它已经初具RTOS的雏形了,但还存在以下问题:
- 相同优先级的任务需要排队执行
- 高优先级的任务在执行时,无法主动释放cpu使用权,即高优先级任务执行完某一步,需要sleep一段时间再执行不好实现
- 高优先级任务(定时器中断注册的任务)和低优先级任务(主循环注册的任务)性质不同,不完全等价
- 会引入更多的中断嵌套,且调度定时器中断优先级要最低,否则会导致其他中断受影响
- 所有任务使用同一个栈,一崩全崩
为了解决上述问题,RTOS便应运而生
思考
有了前面几种调度器的铺垫 ,我们对 RTOS 需要实现哪些功能有个大概的认识,应该有以下几点:
-
各个任务性质相同 ,但有优先级区分 ,且同一优先级的任务,不能排队运行,而是时间片轮转
-
任务任何时间都能切换到其它任务 , 而有这种能力的只有中断 ,也就是需要有一个接口,供任务主动触发中断,然后在中断里边切换到其他任务
-
任务本身是函数 , 所谓的任务切换,其实就是切换当前运行的函数, 通过修改PC指针就可以实现
-
由A任务(函数)切换到 B任务(函数),不能直接令PC指针等于任务B(函数)的地址,这样先前B执行的过程和A执行的过程会丢失
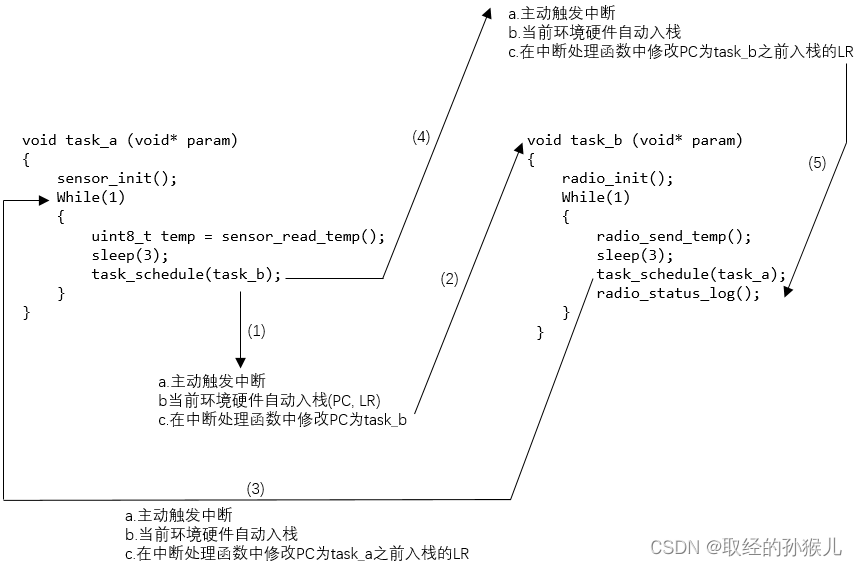
PendSV(可悬起系统调用)
一般设置成最低优先级,这样可以保证 优先级顺序: 高优先级中断 >低优先级中断 > 高优先级任务 > 低优先级任务 ,
线程栈与主栈
在上面的思考中。有一点没有明确:在task_a中主动触发中断,task_a的环境将保存到栈中,然后切换到task_b执行,再次触发中断,将task_b的环境保存到栈中,再回到task_a, 若a和b的环境都保存在同一个栈中,那么根据栈的特性先入后出,由b到a的切换必须先弹出b的环境,再弹出a的环境,这样显然不行。我们知道栈本身是一块连续的内存,PUSH 和 POP指令控制将内容压入栈中,然后移动对应的SP指针 ,若为每一个任务都定义一个栈和SP指针,就能解决上述问题。

在多线程模式下 系统SP指针使用的是 PSP , 若发生中断,在将线程环境压入当前 SP (PSP) 后 ,SP将切换成 MSP,后续的中断局部变量,中断函数调用以及中断嵌套,都将使用MSP 。将系统使用的栈和线程使用的栈分开,可减小全面崩溃的风险。(在中断的具体行为章节有详细描述)
线程切换汇编分析
;*************************************************************************
; 全局变量(4)
;*************************************************************************
IMPORT rt_thread_switch_interrupt_flag
IMPORT rt_interrupt_from_thread
IMPORT rt_interrupt_to_thread;*************************************************************************
; 常量(5)
;*************************************************************************
;-------------------------------------------------------------------------
; 有关内核外设寄存器定义可参考官方文档:STM32F10xxx Cortex-M3 programming manual
; 系统控制块外设SCB 地址范围:0xE000ED00-0xE000ED3F
;-------------------------------------------------------------------------
SCB_VTOR EQU 0xE000ED08 ; 向量表偏移寄存器
NVIC_INT_CTRL EQU 0xE000ED04 ; 中断控制状态寄存器
NVIC_SYSPRI2 EQU 0xE000ED20 ; 系统优先级寄存器(2)
NVIC_PENDSV_PRI EQU 0x00FF0000 ; PendSV 优先级值(lowest)
NVIC_PENDSVSET EQU 0x10000000 ; 触发PendSV exception 的值; *-----------------------------------------------------------------------
; * 函数原型:void rt_hw_context_switch_to(rt_uint32 to);
; * r0 --> to
; * 该函数用于开启第一次线程切换
; *-----------------------------------------------------------------------
rt_hw_context_switch_to PROCEXPORT rt_hw_context_switch_to ; 导出rt_hw_context_switch_to,让其具有全局属性,可以在C 文件调用LDR r1, =rt_interrupt_to_thread ; 将rt_interrupt_to_thread 的地址加载到r1STR r0, [r1] ; 将r0 的值存储到rt_interrupt_to_threadLDR r1, =rt_interrupt_from_thread; 将rt_interrupt_from_thread 的地址加载到r1MOV r0, #0x0 ; 配置r0 等于0 , ;设置rt_interrupt_from_thread 的值为0,表示启动第一次线程切换STR r0, [r1] ; 将r0 的值存储到rt_interrupt_from_threadLDR r1, =rt_thread_switch_interrupt_flag ; 设置中断标志位rt_thread_switch_interrupt_flag 的值为1 MOV r0, #1 ; 配置r0 等于1STR r0, [r1] ; 将r0 的值存储到rt_thread_switch_interrupt_flag; 设置PendSV 异常的优先级LDR r0, =NVIC_SYSPRI2LDR r1, =NVIC_PENDSV_PRILDR.W r2, [r0,#0x00] ; 读ORR r1,r1,r2 ; 改STR r1, [r0] ; 写; 触发PendSV 异常(产生上下文切换)LDR r0, =NVIC_INT_CTRLLDR r1, =NVIC_PENDSVSETSTR r1, [r0]; 开中断CPSIE FCPSIE I
; *-----------------------------------------------------------------------
; * void PendSV_Handler(void);
; * r0 --> switch from thread stack
; * r1 --> switch to thread stack
; * psr, pc, lr, r12, r3, r2, r1, r0 are pushed into [from] stack
; *-----------------------------------------------------------------------
PendSV_Handler PROCEXPORT PendSV_HandlerMRS r2, PRIMASK ; 失能中断,为了保护上下文切换不被中断CPSID ILDR r0, =rt_thread_switch_interrupt_flag ;加载rt_thread_switch_interrupt_flag 的地址到r0LDR r1, [r0] ; 加载rt_thread_switch_interrupt_flag 的值到r1CBZ r1, pendsv_exit ;判断r1 是否为0,为0 则跳转到pendsv_exitMOV r1, #0x00 ; r1 不为0 则清0 STR r1, [r0] ; 将r1 的值存储到rt_thread_switch_interrupt_flag,即清0LDR r0, =rt_interrupt_from_thread ; 加载rt_interrupt_from_thread 的地址到r0LDR r1, [r0] ; 加载rt_interrupt_from_thread 的值到r1CBZ r1, switch_to_thread ; 判断r1 是否为0,为0 则跳转到switch_to_thread ,第一次线程切换时肯定为0,则跳转到switch_to_thread;================================================================================================;上文保存;================================================================================================; 当进入PendSVC Handler 时,上一个线程运行的环境即:; xPSR,PC(线程入口地址),R14,R12,R3,R2,R1,R0(线程的形参); 这些CPU 寄存器的值会自动保存到线程的栈中,剩下的r4~r11 需要手动保存MRS r1, psp ; 获取线程栈指针到r1STMFD r1!, {r4 - r11} ; 将CPU 寄存器r4~r11 的值存储到r1 指向的地址(每操作一次地址将递减一次)LDR r0, [r0] ; 加载r0 指向值到r0,即r0=rt_interrupt_from_threadSTR r1, [r0] ; 将r1 的值存储到r0,即更新线程栈sp;========================================================================================================;下文切换;========================================================================================================switch_to_threadLDR r1, =rt_interrupt_to_thread ; 加载rt_interrupt_to_thread 的地址到r1, 它 是一个全局变量,里面存的是线程栈指针SP 的指针LDR r1, [r1] ; 加载rt_interrupt_to_thread 的值到r1,即sp 指针的指针LDR r1, [r1] ; 加载rt_interrupt_to_thread 的值到r1,即spLDMFD r1!, {r4 - r11} ; 将线程栈指针r1(操作之前先递减) 指向的内容加载到CPU 寄存器r4~r11MSR psp, r1 ; 将线程栈指针更新到PSPpendsv_exitMSR PRIMASK, r2 ; 恢复中断ORR lr, lr, #0x04 ; 确保异常返回使用的栈指针是PSP,即LR 寄存器的位2 要为1; 异常返回,这个时候栈中的剩下内容将会自动加载到CPU 寄存器:; xPSR,PC(线程入口地址),R14,R12,R3,R2,R1,R0(线程的形参); 同时PSP 的值也将更新,即指向线程栈的栈顶BX lr ENDP ; PendSV_Handler 子程序结束
任务优先级与时间片
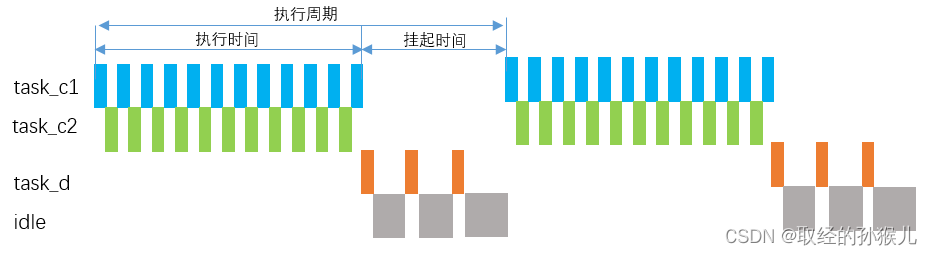
优先级实现了高优先级任务抢占低优先级任务 ,时间片实现了同等优先级的任务分时间片运行。RTOS由中断 ,优先级 ,时间片决定了 其 RealTime OS 中的RealTime特性。下图中,任务a,b,c,d 允许抢占发生 , b1, b2,b3 允许时间片轮转发生
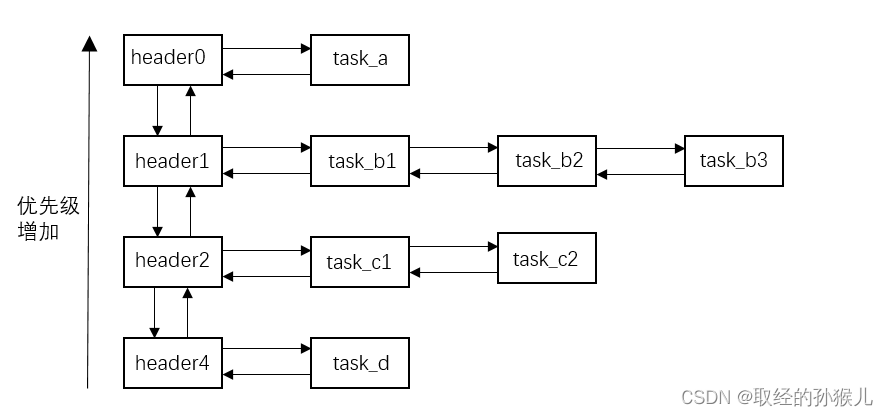
任务就绪表与系统滴答时钟
上图定义的就是任务优先级就绪表 ,就绪表的更新如下步骤:
- 任务在创建后,会根据任务的优先级,将任务插入到就绪表中
- 启动调度后,系统将从优先级最高的链表(header0)开始查询就绪任务,并执行最高优先级任务 task_a
- task_a中 调用sleep函数,等待下一个system_tick中断到来,在中断处理函数中获取优先级最高的就绪任务执行(b1,b2 ,b3)
- 依次执行完c1 ,c2 , d , 完成所有任务都运行一遍,此时,再次触发 system_stick 可能没有任务处于就绪态
- 在system_stick 中断处理函数中遍历任务,若任务剩余阻塞tick不为0 (vTaskDelay和其他阻塞函数设置tick),则tick-- , 否则调度任务
- c1 , c2 处于同一优先级 , 若c1运行一个周期需要 40ms(未调用阻塞函数,例如运行复杂计算),c2运行周期60ms
- 当任务时间片设置为5ms时 , c1运行5ms后,在system_tick中会判断c1剩余时间片为0 ,切换到c2运行5ms , 然后切换到c1运行,知道c1,c2运行完再运行低优先级任务
多线程编程模式
阻塞式编程
顺序逻辑结构
请求应答逻辑结构
发布与订阅逻辑结构
临界区与互斥访问
函数的可重入性
临界区使用场景
互斥访问使用场景
互锁的形成与避免
实时性窗口
推荐此系列文章: https://blog.51cto.com/u_15288275/2975971?articleABtest=0
以下是个人对此系列文章理解:
异常排查方法与工具
jlink-Command(在线)
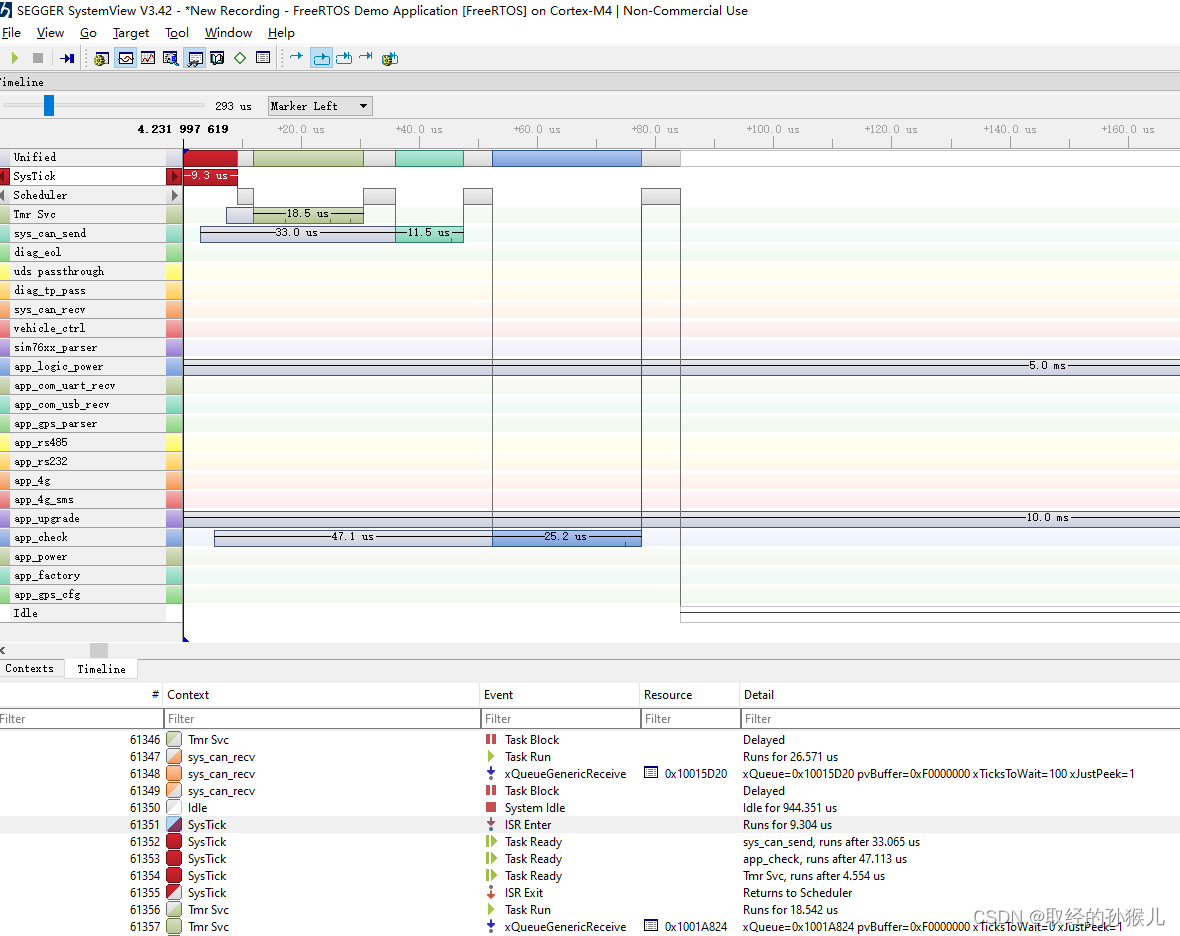
SystemView(在线)
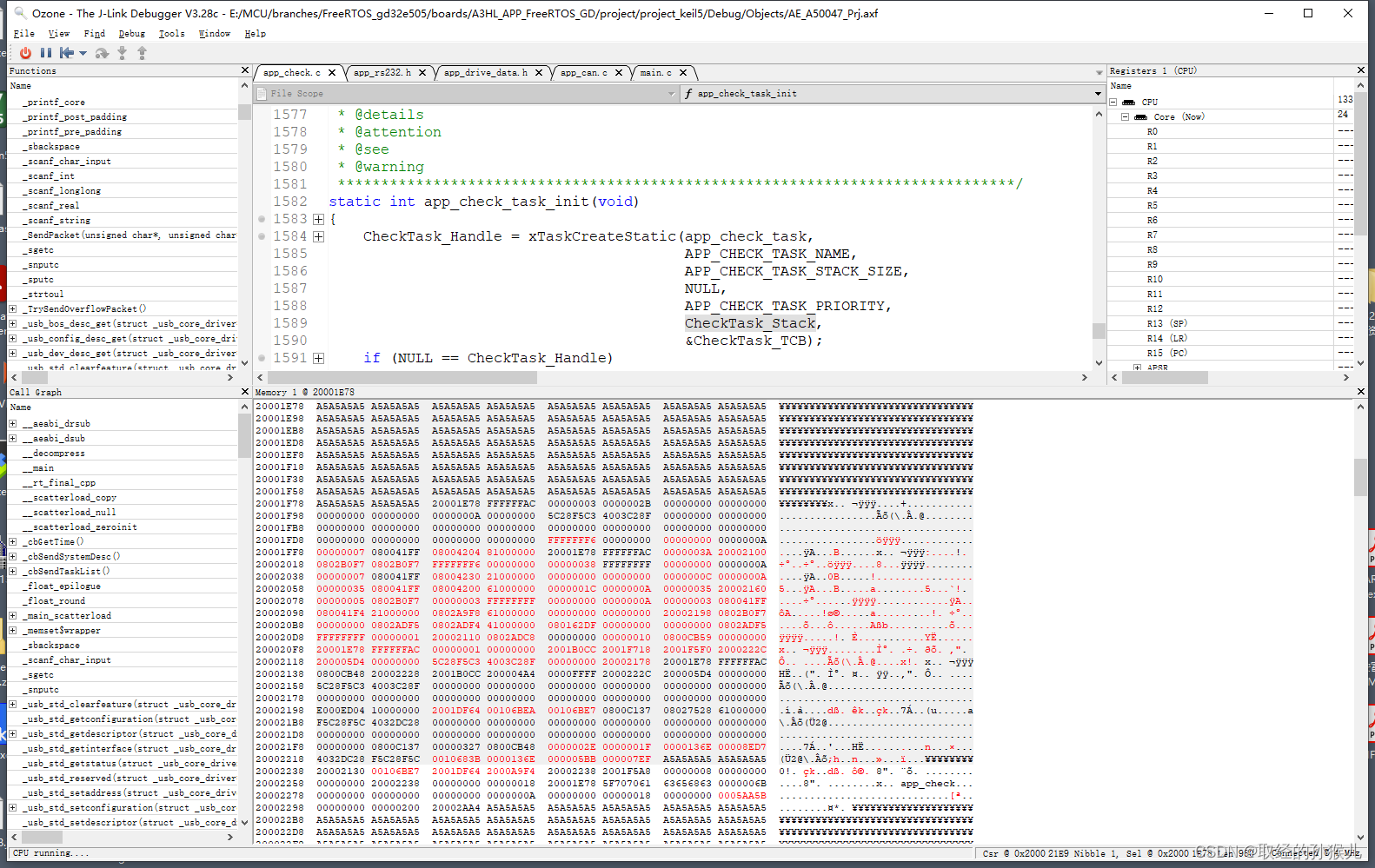
Ozone(在线)
离线分析工具