👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:Redis:原理+项目实战——Redis实战3(Redis缓存最佳实践(问题解析+高级实现))
📚订阅专栏:Redis速成
希望文章对你们有所帮助
上次已经讲解了企业级用Redis进行缓存更新的基础用法,并且进行了最佳实践。但是其实Redis在使用的过程中还是会出现各种问题:缓存穿透、缓存雪崩、缓存击穿。
其中缓存穿透比较好解决,在这里会进行解决。
缓存雪崩提一下解决方案就好了,真正的解决在Redis学到比较高级的时候,或者说在肝微服务架构的时候去具体解决。
缓存击穿的解决方法在这里也提一下,具体编码的解决在下一节进行
缓存穿透、雪崩、击穿及解决方案
- 缓存穿透
- 缓存穿透解决思路
- 编码解决商铺查询的缓存穿透问题
- 缓存雪崩及解决思路
- 缓存击穿及解决思路
- 解决思路——互斥锁
- 解决思路——逻辑过期
- 解决思路总结
缓存穿透
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。过程即:
(1)客户端访问Redis,未命中
(2)接着访问数据库,未命中
这样的话,如果有人恶意多线程地访问不存在的内容,可能就把我们的系统弄垮了。
缓存穿透解决思路
常见的解决方案如下:
1、缓存空对象:
(1)客户端请求Redis,未命中
(2)接着访问数据库,未命中
(3)数据库将空值null缓存到Redis里
这样如果继续访问的话,就会访问Redis了,不会一直去对数据库造成攻击,尽管访问Redis以后返回的内容是NULL。
优点:实现简单,维护方便
缺点:额外内存消耗(每次进行不同的访问,都创建null,不过设置TTL可以解决);可能造成短期的不一致(设置为NULL之后,数据库真的新增了这个数据,不过设置TTL可以有效缓解这种情况的出现概率)
2、布隆过滤:
这其实是一种算法,它在客户端与Redis交互之间加了一个布隆过滤器:
(1)用户请求布隆过滤器,不存在就直接拒绝
(2)存在的话就放行,让客户端去访问Redis,有就返回,没有就访问数据库
布隆过滤器存储的一系列的二进制位,这种二进制数是先对数据库数据进行某种哈希运算以后再转成二进制存储到布隆过滤器的,具体原理可以自行查询,这种算法实现方式决定了过滤器存在概率性:
如果过滤器返回不存在,那就是不存在;如果返回存在,那就不一定了。
优点:内存占用较少,没有多余key
缺点:实现复杂(不过Redis里面存在,可以简化开发);存在误判可能。
因为布隆过滤器存在误判,所以我们的开发过程中,会选择缓存空对象的方式来解决缓存穿透。
编码解决商铺查询的缓存穿透问题
1、我们需要在之前业务流程环节中增加缓存空对象的环节,即可解决,也就是根据id查询数据库的时候,判断商铺不存在之后,不再直接结束,而是将空值写入Redis。
2、那么我们之后的查询,可以在缓存中查询出null值,因此我们的查询就需要对查询出来的值进行判断,不是空值的话才能返回商铺信息到前端。
代码如下:
@Overridepublic Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;//从Redis中查询商铺缓存,存储对象可以用String或者Hash,这里用StringString shopJson = stringRedisTemplate.opsForValue().get(key);//判断是否存在if (StrUtil.isNotBlank(shopJson)) {//存在,直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}//判断命中的是否是nullif (shopJson != null){//返回错误信息return Result.fail("点评信息不存在");}//不存在,根据id查询数据库Shop shop = getById(id);//不存在,返回错误if (shop == null){//存一个null到Redis中//这种没用的信息,TTL没必要设置太长了,这里我设置成了2minstringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return Result.fail("店铺不存在");}//存在,写入RedisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);//返回return Result.ok(shop);}
当我们网页的id设置成0去查询店铺:

打开Redis,0号的商铺确实存入了Redis,且值为空:
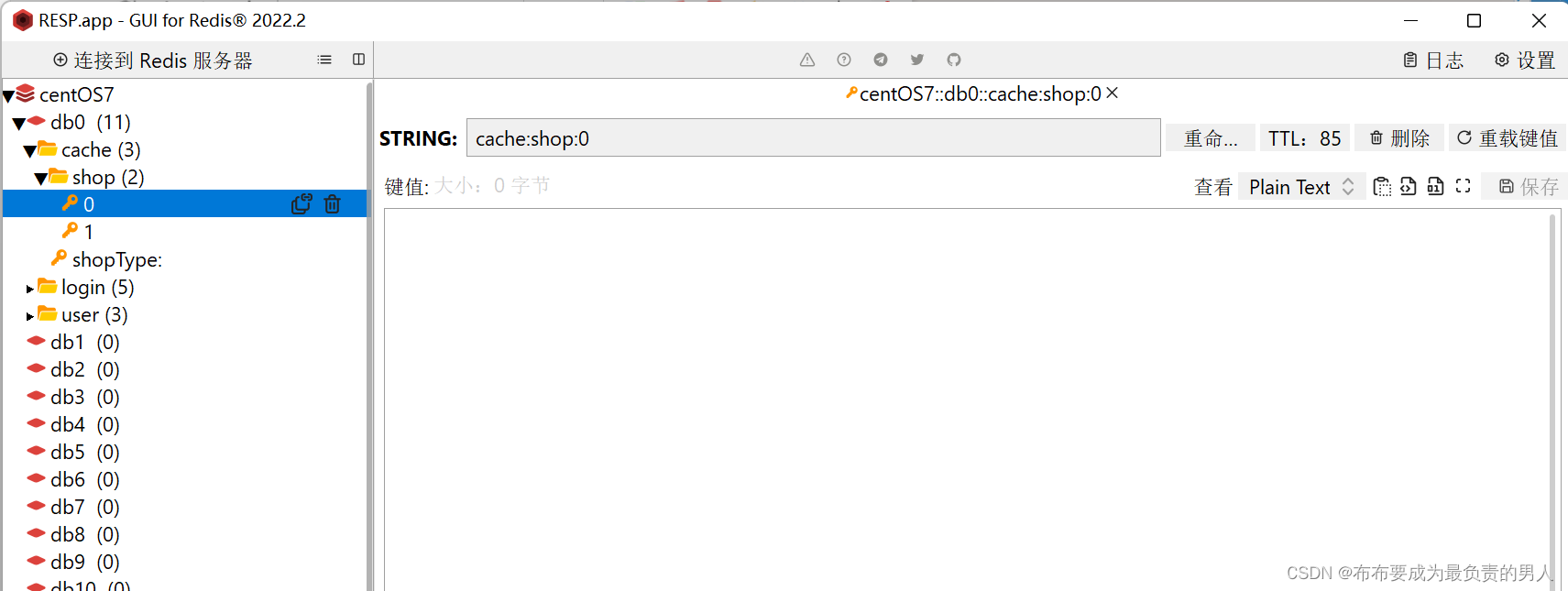
到此,我们成功用代码解决了这个问题。
缓存雪崩及解决思路
缓存雪崩是指同一时段有大量的缓存key失效,或者Redis服务宕机,导致大量请求到达数据库,带来的巨大压力。
正常情况下,大量请求会到达Redis,少数请求到达数据库。而Redis一旦宕机,或者Redis中的大量key都因为TTL到期而失效了,这时候的很多请求都会指向数据库。
针对这个问题,我们可以提出一些解决方案:
1、给不同的key的TTL添加随机值,避免大量的key在同一个小时段内失效
2、利用Redis集群提高服务的可用性(Redis哨兵机制可以实现服务的监控,发现宕机的主Redis,就可以立刻将从Redis替代上去),这个内容相对比较高级,在之后讲。
3、给缓存业务添加降级限流策略(如果整个集群的Redis全部都宕机了,我们可以提前做容错处理,当这些Redis都失效的时候,我们要及时的拒绝请求,防止大量请求到达数据库)
4、给业务添加多级缓存
缓存击穿及解决思路
缓存击穿也叫作热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
我们可以这么理解,网站中有一些内容是非常的重要的,很可能在同一时段被多个用户给同时访问,也就是高并发访问,而这个被高并发访问的key失效了,这时候访问就会到达数据库,大量请求到达数据库是很危险的,很容易造成缓存雪崩。
即便数据库比较坚强,也有可能用户进行访问的内容是很复杂的,可能涉及到了多表查询,也可能其转换到Redis中进行存储的时候需要进行一系列的业务。当缓存重建业务复杂的时候,如此大的请求在那一瞬间给数据库带来的冲击是非常巨大的。
缓存击穿问题,有两种比较主流的解决方法:
1、互斥锁
2、逻辑过期
解决思路——互斥锁
互斥锁还是比较好理解的:
1、当第一个线程未命中缓存的时候,获取互斥锁,直到这个线程查询数据库完,并且重建了缓存数据并存入Redis,才能释放互斥锁;
2、后面的线程在缓存数据存入Redis的过程中,同样会发生查询Redis未命中的情况,那么这些线程无法获得互斥锁,只能进行休眠,休眠一段时间后再重试,直到锁被解开(Redis中已经有数据了)。
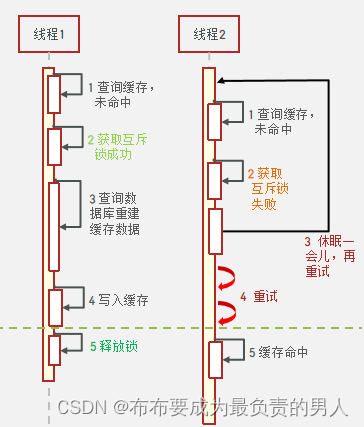
学过操作系统的同学应该知道,这个问题可能会出现的问题就是,线程之间很可能会出现相互等待的情况,当然操作系统中针对这些情况都还是有对应的一些解决方法的。
解决思路——逻辑过期
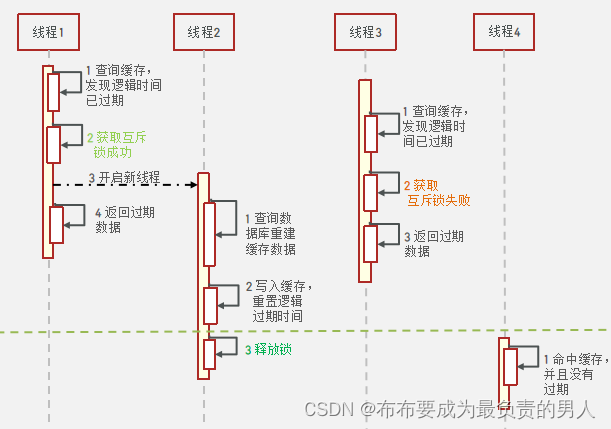
缓存击穿会出现的原因,其实无非就是TTL到期,Redis失效了,因此我们可以不给其设置TTL。但是我们该如何知道key过期了呢?我们要给这个key设置一个逻辑过期,类似:
| KEY | VALUE |
|---|---|
| wxj:user:1 | {name:“Jack”, age:21, expire:151467} |
这里的expire不是TTL,而是我们添加到Redis之前设定的,用代码逻辑来进行维护。
那么这个key一旦存储到了Redis里面,没有任何干预的情况下是永不过期的。
也就是说有一个线程在查询缓存的时候,代码逻辑里发现逻辑时间过期了,我们也直接把旧数据返还给客户端,毕竟已经是高并发,一时的旧数据在很多时候也能接受,在我看来这是一种牺牲策略,客户端无须等待新数据到来,当然了,旧数据迟早要进行修改,但数据的更新操作完全可以交给其他线程,这样可以提高效率:
解决思路总结
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外内存消耗;保持一致性;实现简单 | 线程要等待,性能受影响;可能死锁 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性;有额外内存消耗;实现复杂 |
其实我感觉两种思路完全是可以结合在一起的,当然具体还是要看业务的应用场景和需求。
在下面的文章将会进行缓存击穿的解决思路的编码实现。