一、子线程 WorkerThread的实现
(1)工作线程
- 线程ID:每个线程都有一个唯一的ID,用于标识
- 线程的名字:非必需,主要用于识别线程
- 互斥锁:线程同步
- 条件变量:线程阻塞
- EventLoop:在每个子线程里边都有一个反应堆模型

// 定义子线程对应的结构体
struct WokerThread {pthread_t threadID;// 线程IDchar name[24];// 线程名字pthread_mutex_t mutex;// 互斥锁(线程同步)pthread_cond_t cond;// 条件变量(线程阻塞)struct EventLoop* evLoop;// 事件循环(反应堆模型)// 在每个子线程里边都有一个反应堆模型
};(2)工作线程初始化
// 初始化
int workerThreadInit(struct WokerThread* thread, int index);// 初始化
int workerThreadInit(struct WokerThread* thread, int index) {thread->threadID = 0;// 线程IDsprintf(thread->name, "SubThread-%d", index);// 线程名字// 指定为NULL,表示使用默认属性pthread_mutex_init(&thread->mutex, NULL);// 互斥锁pthread_cond_init(&thread->cond, NULL);// 条件变量thread->evLoop = NULL;// 事件循环(反应堆模型)return 0;
}(3)启动线程
// 启动线程
void workerThreadRun(struct WokerThread* thread);// 子线程的回调函数
void* subThreadRunning(void* arg) {struct WokerThread* thread = (struct WokerThread*)arg;// 还有子线程里边的evLoop是共享资源,需要添加互斥锁pthread_mutex_lock(&thread->mutex);// 加锁thread->evLoop = eventLoopInitEx(thread->name);pthread_mutex_unlock(&thread->mutex);// 解锁pthread_cond_signal(&thread->cond);// 发送信号(唤醒主线程,通知主线程解除阻塞)eventLoopRun(thread->evLoop);// 启动反应堆模型return NULL;
}// 启动线程
void workerThreadRun(struct WokerThread* thread) {// 创建子线程pthread_create(&thread->threadID, NULL, subThreadRunning, thread);/*在这里阻塞主线程的原因是:在于子线程的反应堆模型是否被真正的创建出来了?因此,可以判断一下thread->evLoop是否为NULL,如果等于NULL,说明子线程反应堆模型还没有被初始化完毕,没有初始化完毕,我们就阻塞主线程*/// 阻塞主线程,让当前函数不会直接结束pthread_mutex_lock(&thread->mutex);while(thread->evLoop == NULL) { // 多次判断pthread_cond_wait(&thread->cond, &thread->mutex);// 子线程的回调函数(subThreadRunning)里调用pthread_cond_signal(&thread->cond)可以解除这里的阻塞}pthread_mutex_unlock(&thread->mutex);
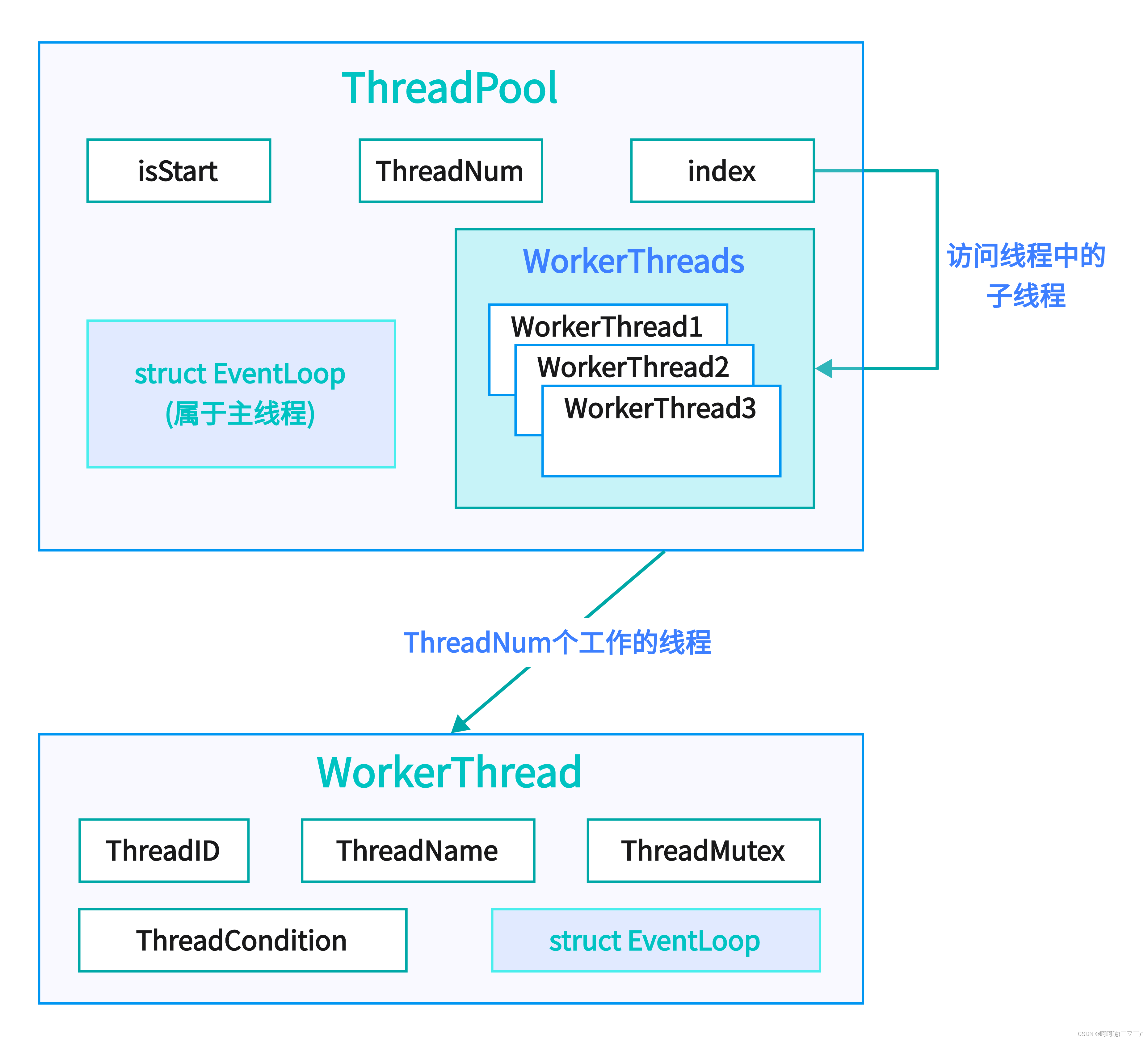
}二、线程池ThreadPool的初始化
- ThreadPool.h
// 定义线程池
struct ThreadPool {/*在线程池里边的这个mainLoop主要是做备份用的,主线程里边的mainLoop主要负责和客户端建立连接,只负责这一件事情,只有当线程池没有子线程这种情况下,mainLoop才负责处理和客户端的连接,否则的话它是不管其他事情的。*/struct EventLoop* mainLoop; // 主线程的反应堆模型int index; bool isStart;int threadNum; // 子线程总个数struct WorkerThread* workerThreads;
};在线程池里边其实管理一个WorkerThreads数组,在这个数组里边有若干个元素,每个元素里边都有一个WorkerThread对象,把这若干个子线程对象初始化出来。之后,每个子线程里边都有一个EventLoop(反应堆模型),子线程处理的任务其实就是EventLoop里边的任务。
除此之外,在线程池里边还可以添加一个变量用来标记当前线程池是否启动:isStart默认情况下,肯定是不启动的状态的,即isStart = false;
ThreadNum用来记录当前线程池里边的子线程的个数,就是WorkerThreads数组的元素个数,它们有对应关系。
index记录线程池里边子线程的编号,通过这个index就能够访问线程池里边某个线程。
>>思考:为什么我们要访问线程池里边的某一个线程?
场景:主线程和客户端建立了连接,之后,就需要和客户端通信,那么这个通信的文件描述符和客户端通信流程需要交给子线程去处理,每个子线程里边都有一个EventLoop(反应堆模型),就需要把这个通信的文件描述符交给这个反应堆模型去管理,检测这个文件描述符的事件,如果有读事件,说明客户端有数据发送过来,那么我们就需要接收数据,然后再给客户端回复数据,这些都是在子线程的反应堆模型里边做的。所以当这个连接建立之后,主线程就要从线程池里边找出一个子线程,并且把这个任务给到子线程去处理。
但是存在一个问题:假设只有三个子线程,在找子线程的时候,不可能每次都找workerThread1,如果每次都是workerThread1,那么workerThread2, workerThread3就空闲下来了,为了雨露均沾,可以用index来表示当前访问的线程到底是谁,如果这次访问线程1,那么下次就是线程2。如果这次访问线程2,那么下次就是线程3。如果这次访问线程3,那么下次就是线程1。
还有另外一个反应堆模型,这个是属于主线程的,并不用在ThreadPool线程池里边再去实例化一个EventLoop。其实是把主线程的这个EventLoop给到线程池,目的是:假设说这个线程池的ThreadNum=0,此时这个线程池里边就没有子线程了,也就没有反应堆模型了,也就没有办法工作,在这种情况下,我们就可以让线程池使用主线程的反应堆模型,这样就能够保证线程池还能够继续工作,只不过在当前服务器框架里边,它的反应堆模型就从多个变成了一个,所有的任务都变成了全部由主线程的反应堆模型来处理了。
在线程池里边的这个mainLoop主要是做备份用的,主线程里边的mainLoop主要负责和客户端建立连接,只负责这一件事情,只有当线程池没有子线程这种情况下,mainLoop才负责处理和客户端的连接,否则的话它是不管其他事情的。
- ThreadPool.h
// 初始化线程池
struct ThreadPool* threadPoolInit(struct EventLoop* mainLoop, int threadNum);- ThreadPool.c
// 初始化线程池
struct ThreadPool* threadPoolInit(struct EventLoop* mainLoop, int threadNum) {struct ThreadPool* pool = (struct ThreadPool*)malloc(sizeof(struct ThreadPool));pool->mainLoop = mainLoop; // 主线程的反应堆模型pool->index = 0;pool->isStart = false;pool->threadNum = threadNum; // 子线程总个数pool->workerThreads = (struct WokerThread*)malloc(sizeof(struct WokerThread) * threadNum); // 子线程数组return pool;
}