近日,小编在内核pci模块变更提交记录里面,看到一条由联想工程师提交的一份变更,主要是针对DMA相关优化。小编根据提交内容,根据自己的理解分享给大家。(原始git地址获取,请在后台私信输入关键字“IO宕机”)

根据提交的commit记录来看:
-
发生场景:FIO压测
-
测试环境:448 core AMD CPU+NVME SSD
-
故障现象:系统出现CPU soft lockup
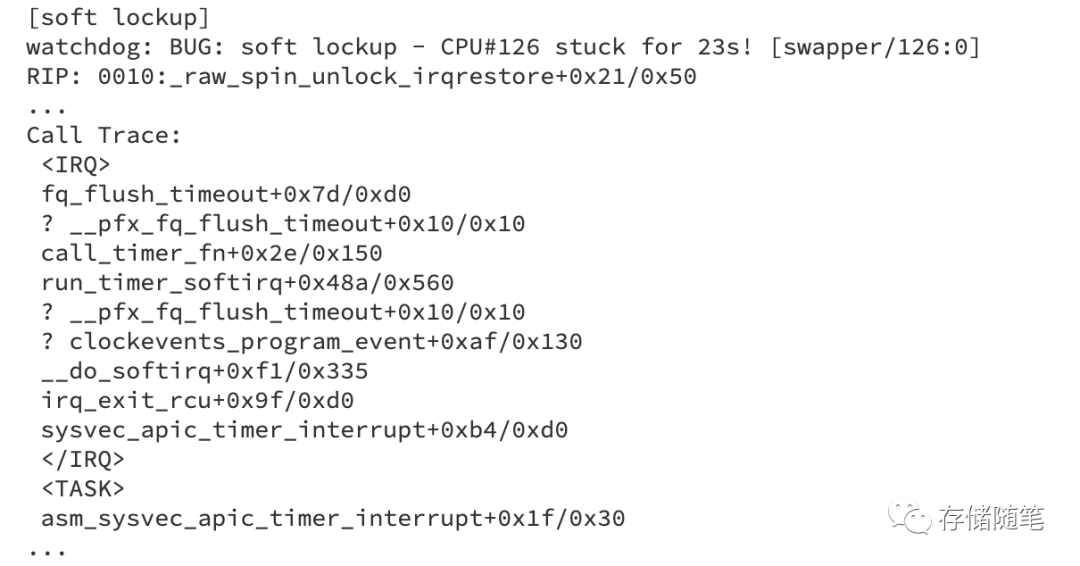
根据Call trace分析解读:“soft lockup”问题,CPU#126在执行特定操作时被卡住超过23秒。这种情况意味着该CPU在处理某个任务时未能及时响应系统调度,导致了软锁定(长时间无响应)。具体错误信息如下:
-
watchdog: BUG: soft lockup - CPU#126 stuck for 23s! [swapper/126:0]:这行表示系统的看门狗机制检测到CPU #126在执行idle进程(swapper进程)时发生了软锁定,已经停滞了23秒。 -
RIP: 0010:_raw_spin_unlock_irqrestore+0x21/0x50:RIP寄存器记录了程序崩溃时的指令指针位置,这里指向的是_raw_spin_unlock_irqrestore函数内部偏移地址为0x21的位置,而该函数总长度为0x50字节。这个函数通常用于解除自旋锁并恢复中断状态。 -
调用栈情况:
-
-
出现故障前最后执行的是
fq_flush_timeout+0x7d/0xd0,这是一个与数据刷新相关的函数,可能涉及到I/O队列或缓存的数据刷写至磁盘的操作。 -
然后是中断处理相关的函数如
irq_exit_rcu、sysvec_apic_timer_interrupt等,表明CPU在执行这些中断服务例程时发生问题。
-
根据Call trace简单来说,问题现象是在处理I/O队列数据刷新过程中,CPU因某种原因陷入了无限循环或者无法退出的状态,进而引发了软锁定。
根据这个现象,联想工程师用ftrace抓取了故障函数stack,发现在fq_flush_timeout函数运行了超过20s。

ftrace里面还可以进一步看到,存在锁竞争(Lock Contention)。由于IOVA(I/O虚拟地址)flush队列机制的存在,大部分 CPU 核心都在尝试获取 iova_rbtree_lock 锁,但是由于资源有限,多个核心不能同时获得该锁,导致了严重的锁竞争现象。这会导致处理器核心等待锁的时间增加,进而影响系统的整体性能和响应速度。
-
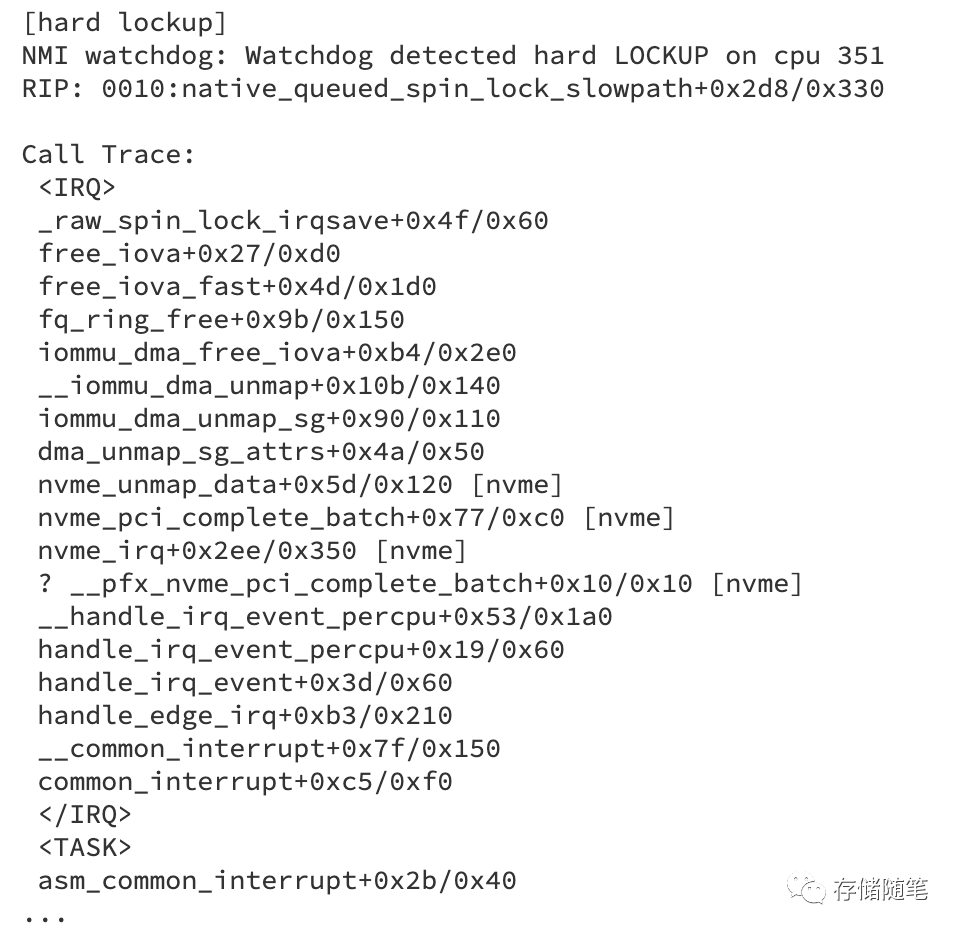
系统检测到CPU 351上发生了硬锁定故障,NMI watchdog(非屏蔽中断看门狗)检测到了这一异常情况。
-
错误发生在执行
native_queued_spin_lock_slowpath函数时,该函数用于自旋锁的获取操作,当多个线程竞争同一把锁且都无法获得时,会进入慢速路径。 -
调用栈显示,大部分内核线程都在尝试获取名为"iova_rbtree_lock"的锁,这个锁与IOVA flush队列机制有关,用于管理IO虚拟地址空间的分配和释放。
-
fq_ring_free函数花费了超过10秒的时间,这进一步印证了锁竞争导致的问题,因为正常情况下,这样的操作不应该需要这么长的时间来完成。 -
在调用栈中,可以看到nvme驱动的相关操作,包括数据映射、DMA unmapping等,这些操作触发了IOVA地址的释放,进而引发了对"iova_rbtree_lock"的争抢。