正则表达式在程序开发中会经常用到,比如数据(格式)验证、替换字符内容以及提取字符串内容等等情况都会用到,但是目前许多开发人员对于正则表达式只是处于了解或者是基本会用的阶段。一旦遇到大批量使用正则表达式的情况(例如网络爬虫)可以说基本上就抓瞎了。这篇文章我将带领大家利用 Python 来学习一下正则表达式。在阅读这篇文章前你需要掌握 Python 基础知识,或者具有其他开发语言的基础知识也可以,因为基本上每种语言使用正则表达式的方式都是类似的。
零、正则表达式基础
1.提取字符(串) 有时我们需要从一个字符串中获取一段内容,这段内容可能是一个字符也可能是一段字符串,如果用逐字对比遍历的话不仅耗时耗力而且还容易出错。那么这个时候我们就可以用到正则表达式中的 字符匹配 功能。正则表达式为我们提供了 4 种字符匹配的方法,见下表:
语法说明例子可匹配字符串.匹配除了换行符 “\n” 以外的任意字符a.bacb、adb、a2b、a~b\转义,将转移字符后面的一个字符改变原来的意思a[b \ . \ \ ]cabc、a.c、a\c[]匹配括号内的任意字符a[b,c,d,e]fabd、acf、adf、aef[^]除了括号内的字符外,其他的字符都匹配a a,b,c,d,e fa1f、a#f、azf、agf
2.预定义字符 所谓预定义字符就是正则表达式中为我们预留的专门用来匹配格式化内容的字符,例如匹配数字用的 \d 和匹配空白符的 \s 等等。我们可以利用预定义字符快速的匹配出一个字符串中符合要求的内容。预定义字符匹配的内容,同样也可以利用前面所讲的字符匹配的方式匹配出来,但是代码量会相对来说多一点。下表所列的就是预定义字符:
语法说明例子可匹配字符串^以什么字符串开始^123123abc、123321、123zxc$以什么字符串结尾123$abc123、321123、zxc123\b匹配单词边界,不匹配任何字符\basd\basd\d匹配数字0-9zx\dczx1c、zx2c、zx5c\D匹配非数字zx\Dczxvc、zx$c、zx&c\s匹配空白符zx\sczx c\S匹配非空白符zx\Sczxac、zx1c、zxtc\w匹配字母、数字和下划线zx\wczxdc、zx1c、zx_c\W匹配非字母、数字和下划线zx\Wczx c、zx$c、zx(c
在预定义字符中有如下几点需要注意:
- \b 匹配的只是一个位置,这个位置的一侧是构成单词的字符,另一侧为非单词字符、字符串的开始或结束位置。\b 是零宽度。
- \w 在不同编码语言中匹配的范围是不一样的,在使用 ASCII 码的语言中匹配的是 [a-zA-Z0-9 ] ,而在使用 Unicode 码的语言中匹配的是 [a-zA-Z0-9 ] 和汉字、全角符号等特殊字符。
3.限制数量 在某些情况下我们需要匹配重复的内容,这时我们可以使用 数量限定 模式来进行操作。数量限定如下表:
语法说明例子可匹配字符串*匹配0到多次zxc*zx、zxccccc+匹配1次到多次zxc+zxc、zxccccc?匹配0次或1次zxc?zxc、zx{m}匹配m次zxc{3}vbzxcccvb{m,}匹配m次或多次zxc{3,}vbzxcccvb、zxccccccccvb{,n}匹配0次到n次zxc{,3}vbzxvb、zxcvb、zxccvb、zxcccvb{m,n}匹配m次到n次zxc{1,3}zxcvb、zxccvb、zxcccvb
4. 断言 断言,又称零宽断言,指的是当断言表达式为 True 时才进行匹配,但是并不匹配断言表达式内容。和 ^ 代表开头, $ 代表结尾, \b 代表单词边界一样,先行断言和后行断言也有类似的作用,它们只匹配某些位置,在匹配过程中,不占用字符,所以被称为零宽。所谓位置,是指字符串中第一个字符的左边、最后一个字符的右边以及相邻字符的中间。零宽断言表达式有四种:
- 零宽度负回顾后发断言 (?<!exp),表达式不成立时匹配断言后面的位置,成立时不匹配。例如 \w+(?<zxc)\d,匹配不以 zxc 结尾的字符串;
- 零宽度负回顾先行断言 (?!exp),表达式匹配断言前面的位置,成立时则不匹配。例如:\d(?!zxc)\w+,匹配不以 zxc 开头的字符串;
- 先行断言 (?=exp),断言为真时匹配断言前面的位置,例如要在 “a regular expression” 这个字符串中追匹配出 regular 中的 re ,我们可以这么写 re(?=gular);
- 后发断言 (?<=exp),断言为真时匹配断言后面的位置,例如对 “egex represents regular expression” 这个字符串要想匹配除 regex 和 regular 之外的re,可以用 re(?!g),该表达式限定了re右边的位置,这个位置后面不是字符g。先行和后发的区别就在于该位置之后的字符能否匹配括号中的表达式。
5.贪婪/非贪婪 正则表达式会尽可能多的去匹配字符,这被称为贪婪模式,贪婪模式是正则表达式默认的模式。但是有时候贪婪模式会给我们造成不必要的困扰,例如我们要匹配字符串 “Jack123Chen123Chen” 中的 “Jack123Chen”,但是贪婪模式匹配出的却是 “Jack123Chen123Chen”,这时我们就需要用到非贪婪模式来解决这个问题,非贪婪模式常用的表达式如下:
- 语法说明*?匹配0次或多次,但要尽可能少重复+?匹配1次或多次,但要尽可能少重复??匹配0次或1次,但要尽可能少重复{m,}?匹配m次或多次,但要尽可能少重复{m,n}?匹配m次或n次,但要尽可能少重复
6. 其他 上述内容在正则表达式中都是常用的,下面我们再来看看不常用到的,但是功能同样强大的语法。
- OR 匹配又称匹配分支,也就是说只要有一个分支匹配就算匹配,这和我们在开发中使用的 OR 语句类似。OR 匹配利用 | 分割分支,例如我们需要匹配出英文姓名,但是在英文中姓和名中间有可能是以 · 分割,也有可能是以空格分隔,这时我们就可以利用 OR 匹配来处理这个问题。格式如下:[A-Za-z]+·[A-Za-z]+|[A-Za-z]+\s[A-Za-z]+
- 组合,将几个项组合为一个单元,这个单元可通过* + ? | 等符号加以修饰,而且可以记住和这个组合相匹配的字符串以提供伺候的引用使用。分组使用 () 来表示。例如获取日期的正则表达式可以这么写:\d{4}-(0[1-9]|1[0-2])-(0[1-9]| |3[01])。第一个分组 (0[1-9]|1[0-2]) 代表月的正则匹配,第二个分组 (0[1-9]| |3[01]) 代表日的正则匹配。
一、Python 使用正则表达式
在 Python 中使用正则表达式很简单, re 模块向我们提供了正则表达式的支持。使用步骤一共三步:
- 将正则表达式字符串转换为 Pattern 的实例;
- 使用 Pattern 实例去处理要匹配的字符,匹配结果是一个 Match 实例;
- 利用 Match 实例去进行之后的操作。
在 Python 中我们常用的 re 的方法有六种,分别是: compile 、 match 、 search 、 findall 、 split 和 sub ,下面就针对这六种方法进行一下讲解。
compile compile 方法的作用是将正则表达式字符串转化为 Pattern 实例,它具有两个参数 pattern 和 flags ,pattern 参数类型是 string 类型,接收的是正则表达式字符串,flags 类型是 int 类型,接收的是匹配模式的编号,flags 参数是非必填项,默认值为 0 (忽略大小写)。flags 匹配模式有如下 6 种:
- 匹配模式说明re.I忽略大小写re.M多行匹配模式re.S任意匹配模式re.L预定义字符匹配模式re.U限定字符匹配模式re.V详细模式
上述六种模式在实际开发中很少用到,我们只需要了解即可。 使用 compile 很简单,如下:
import re
pattern = re.compile(r'\d')
2.match match 的作用是利用 Pattern 实例,从字符串左侧开始匹配,如果匹配到就返回一个 Match 实例,如果没有匹配到就返回 None。
import re
def getMatch(message): pattern = re.compile(r'(\d{4}[-年])(\d{2}[-月])(\d{2}日{0,1})') match = re.match(pattern, message) if match: print(match.groups()) for item in match.groups(): print(item) else: print("没匹配上")
if __name__ == '__main__': message = "2019年01月23日大会开始" getMatch(message) message = "会议于2019-01-23召开" getMatch(message)
在代码中我们使用了 groups 方法,这个方法用来获取匹配出来的字符串组。到这里过一会有很多读者感到纳闷,为什么第一段内容能匹配出来年月日,而第二段内容不能呢?这是因为 match 方法是从字符串的起始位置匹配的。 代码运行结果如图:

3.search search 方法与 match 方法功能是一样的,只不过 search 方法是对整个字符串进行匹配。将前一小节代码中的 getMatch 方法进行改动,即可将第二段内容中的年月日匹配出来。
import re
def getMatch(message): pattern = re.compile(r'(\d{4}[-年])(\d{2}[-月])(\d{2}日{0,1})') match = re.search(pattern, message) if match: print(match.groups()) for item in match.groups(): print(item) else: print("没匹配上")
if __name__ == '__main__': message = "2019年01月23日大会开始" getMatch(message) message = "会议于2019-01-23召开" getMatch(message)
上述代码运行结果如下图:

4.findall findall 方法的作用是匹配整个字符串,以列表的形式返回所有匹配结果。
import re
def getMatch(message): pattern = re.compile(r'\w+') match = re.findall(pattern, message) if match: print(match) else: print("没匹配上")
if __name__ == '__main__': message = "my name is 张三" getMatch(message) message = "张三 is me" getMatch(message)
代码运行结果如下图:

5.split split 方法是利用指定的字符来分割字符串。
import re
def getMatch(message): pattern = re.compile(r'-') match = re.split(pattern, message) if match: print(match) else: print("没匹配上")
if __name__ == '__main__': message = "2018-9-12" getMatch(message) message = "第一步-第二步-第三步-第四步-and more" getMatch(message)
上述代码运行结果如下图:

6.sub sub 方法用来替换字符串,它接受5个参数,其中常用的有三个:
![]()
- pattern,Pattern 实例
- string,等待替换的字符串
- repl,表示替换的新字符串或需要执行的替换方法
- count,替换次数,默认为0表示全部替换
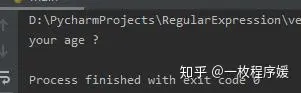
import re
def getMatch(match): return match.group(0).replace(r'年龄', 'age')
if __name__ == '__main__': message = "your 年龄 ?" pattern=re.compile(r'\w+') print(re.sub(pattern,getMatch,message))
代码运行结果如下图:
三、总结
Python 中正则表达式使用起来非常方便,上面所展示的代码,完全可以直接复制出来稍加修改后放在项目中使用。内容不多,主要是讲解代码怎么使用,希望大家完全理解掌握了正则表达式的写法。