目录
- 一、像素级OCR统一模型:UPOCR
- 1.1、为什么提出UPOCR?
- 1.2、UPOCR是什么?
- 1.2.1、Unified Paradigm 统一范式
- 1.2.2、Unified Architecture统一架构
- 1.2.3、Unified Training Strategy 统一训练策略
- 1.3、UPOCR效果如何?
- 二、OCR大一统模型前沿研究速览
- 2.1、Donut:无需OCR的用于文档理解的Transformer模型
- 2.2、NouGAT:**实现文档图像到文档序列输出**
- 2.3、SPTS v3:基于SPTS的OCR大一统模型
- 三、大模型时代下的智能文档处理应用
- 3.1、LLM与文档识别分析应用
- 3.2、智能文档处理应用产品
- 四、文末抽奖
2023年12月28-31日,由中国图象图形学学会主办的第十九届CSIG青年科学家会议在中国广州隆重召开,会议吸引了学术界和企业界专家与青年学者,会议面向国际学术前沿与国家战略需求,聚焦最新前沿技术和热点领域,共同探讨图象图形学领域的前沿问题,分享最新的研究成果和创新观点,在垂直领域大模型专场,合合信息智能技术平台事业部副总经理、高级工程师丁凯博士为我们带来了《文档图像大模型的思考与探索》主题报告。
本文将围绕以下问题,分享主题报告中大模型时代下的智能文档图像处理领域研究问题与深度思考:
- 以GPT4-V Gemini为代表大模型能为IDP领域的技术方案和研发范式上带来什么样的启发?
- 能否吸取大模型的优点,提出精度好、泛化强的OCR大一统模型?
- 能否更好的将LLM与文档识别分析引擎相结合来解决IDP领域的核心问题?
一、像素级OCR统一模型:UPOCR
UPOCR是合合信息-华南理工大学文档图像分析识别与理解联合实验室于2023年12月提出的像素级OCR统一模型。UPOCR基于视觉Transformer(ViT)的编码器-解码器架构,将多样OCR任务统一为图像到图像变换范式,并引入了可学习任务提示,将编码器提取的通用特征表示推向任务特定空间,使解码器具有任务意识。实验表明,模型能够具有对不同任务的建模功能,能够同时实现文本擦除、文本分割和篡改文本检测等像素级OCR任务。
1.1、为什么提出UPOCR?
当前通用文字识别(OCR)领域面临多项主要问题,这些问题实然限制了其在各个应用领域的广泛应用。
- 任务特定性模型的碎片化:虽然OCR领域研究涌现出许多面向特定任务的模型,但每个模型都仅针对特定领域进行优化,模型过于碎片化,不同任务之间难以协同使用,跨领域和多场景的通用性受到较大限制。
- 缺乏统一接口:现有的一些通用模型依赖于特定的接口或解码机制如VQGAN,这种依赖性限制了模型在像素空间的灵活性和适应性,难以关联实现不同任务。
- 像素级OCR难题:当前模型在生成像素级的文本序列方面仍然面临挑战。这是因为文本生成不仅涉及语义理解,还需要考虑像素级别的细节,改善模型在生成像素级文本方面的能力仍是一个重要的研究方向。
1.2、UPOCR是什么?
UPOCR是一个通用的OCR模型,其采用了华南理工大学团队AAAI 2024录用论文中的ViTEraser作为主干网,同时借鉴基于MIM和分割图引导的一种自监督文档图像预训练方法SegMIM进行自监督预训练,然后结合文本擦除、文本分割和篡改文本检测等3个不同的任务提示词进行统一训练。
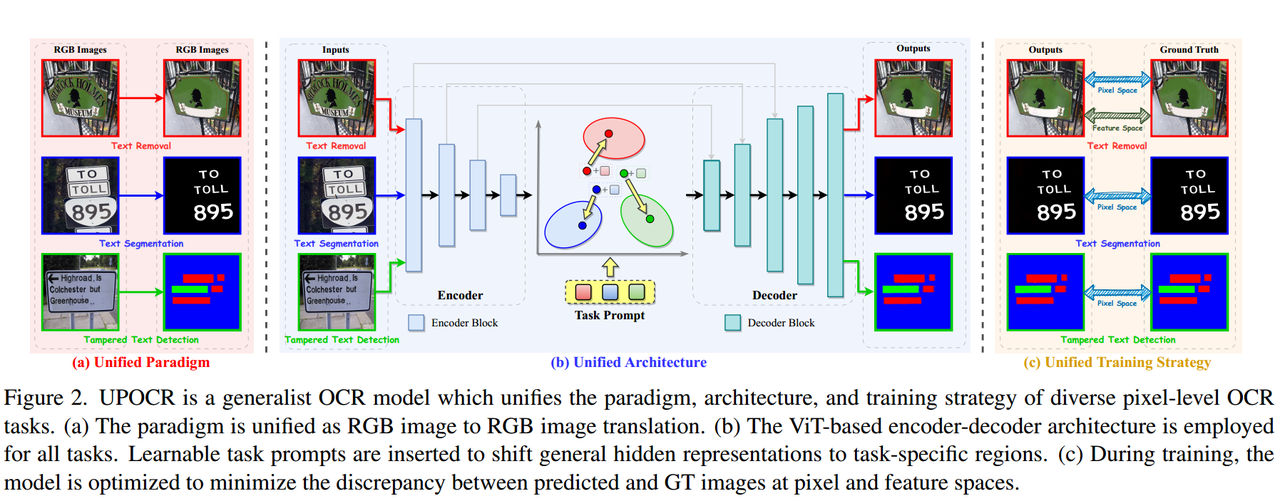
模型训练好后即可直接用于下游任务,无需再进行专门的精调,模型主要从统一范式、统一架构和统一训练策略三个方面进行研究。
1.2.1、Unified Paradigm 统一范式
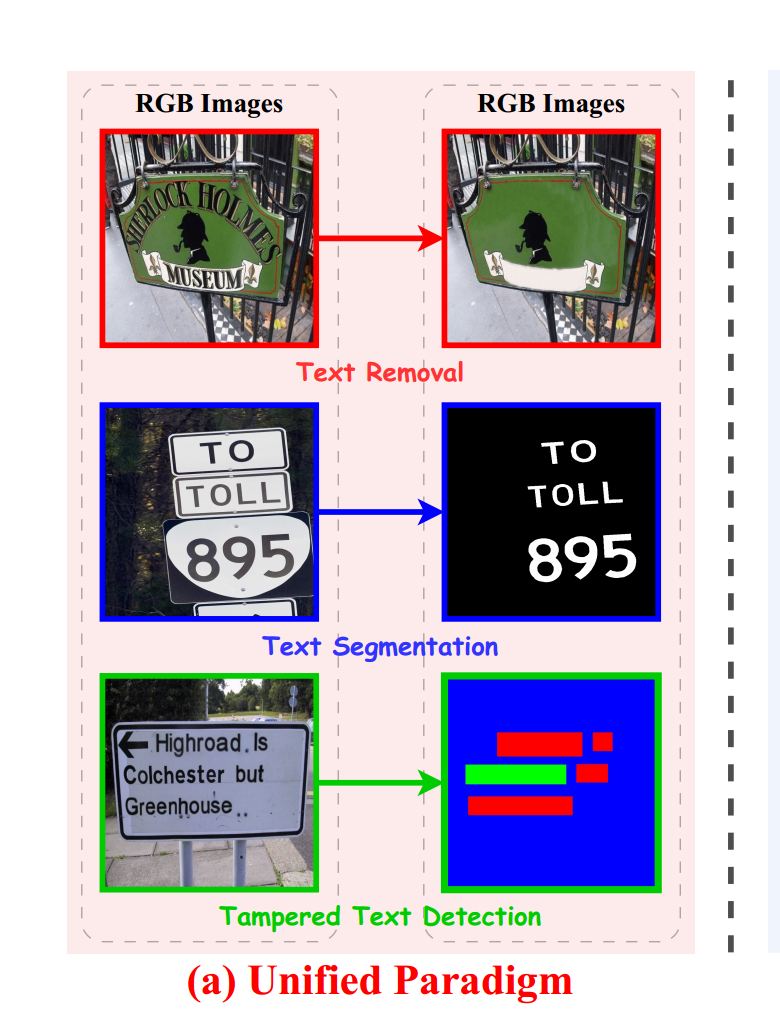
如图所示,作者提出了一个OCR任务统一范式,其将各种像素级OCR任务转化为RGBtoRGB的转换问题。尽管这些任务的目标不同(例如图像生成和分割),但它们都可以被统一为在共享的特征空间中进行操作:
- 文本擦除任务:对于文本擦除任务,输出是与输入对应的去除文本的图像,属于RGBtoRGB任务。
- 文本分割任务:文本分割旨在将每个像素分配给前景(即文本笔画)或背景,在统一的图像到图像翻译范式下,UPOCR预测具有白色和黑色颜色的RGB图像,通过对比生成的RGB值与预定义的前景RGB值的距离来确定类别。
- 篡改文本检测任务:将篡改文本检测任务定义为篡改文本、真实文本和背景类别的每像素分类,进而UPOCR分别为篡改文本、真实文本和背景分配红色(255, 0, 0)、绿色(0, 255, 0)和蓝色(0, 0, 255)颜色。在推断过程中,通过比较预测的RGB值与这三种颜色的距离来确定每像素的类别。
1.2.2、Unified Architecture统一架构
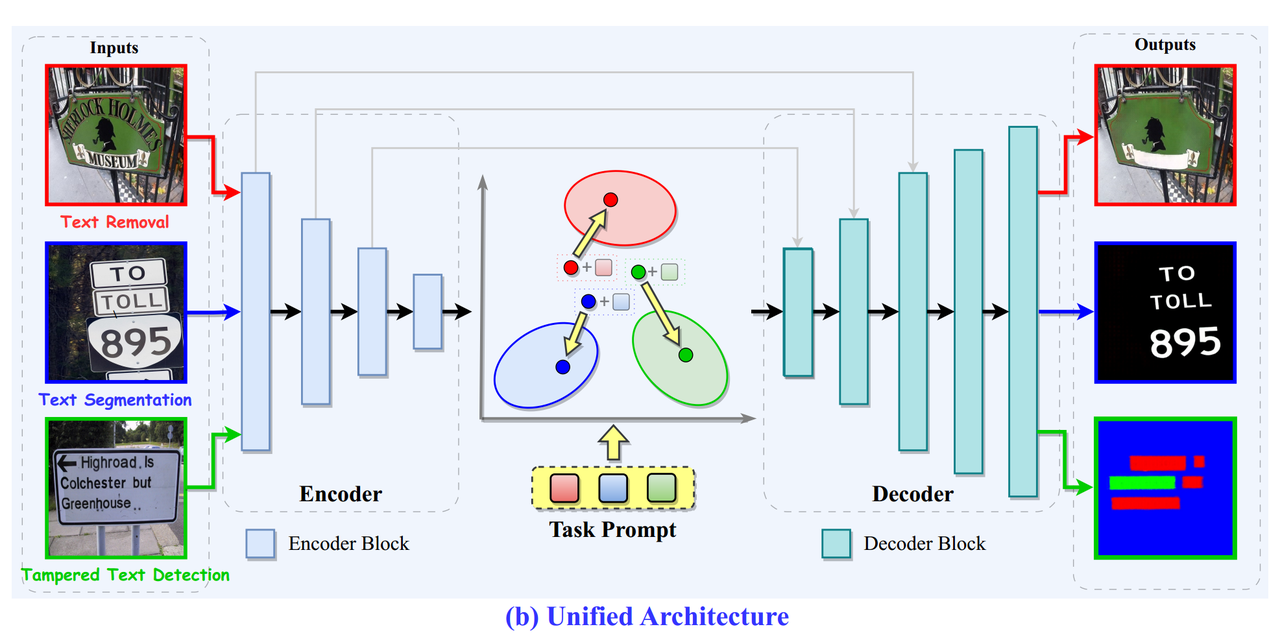
如图所示,作者通过采用基于ViT的编码器-解码器实现了一个统一的图像到图像翻译范式来处理各种像素级OCR任务。其中,编码器-解码器架构采用了ViTEraser作为主干网络,编码器包括四个顺序块,每个编码器块包含一个用于下采样的块嵌入层和Swin Transformer v2块。解码器部分包括五个顺序块,每个解码器块包含一个用于上采样的块分割层和Swin Transformer v2块。
另外,作者在编码器-解码器架构中引入可学习的任务提示,对应的提示被添加到编码器生成的隐藏特征的每个像素上,推动由编码器生成的通用OCR相关表示朝着任务特定区域。随后,解码器将调整后的隐藏特征转换为特定任务的输出图像。基于这种架构,UPOCR能够在极小的参数和计算开销下简单而有效地同时处理多样的任务。
1.2.3、Unified Training Strategy 统一训练策略
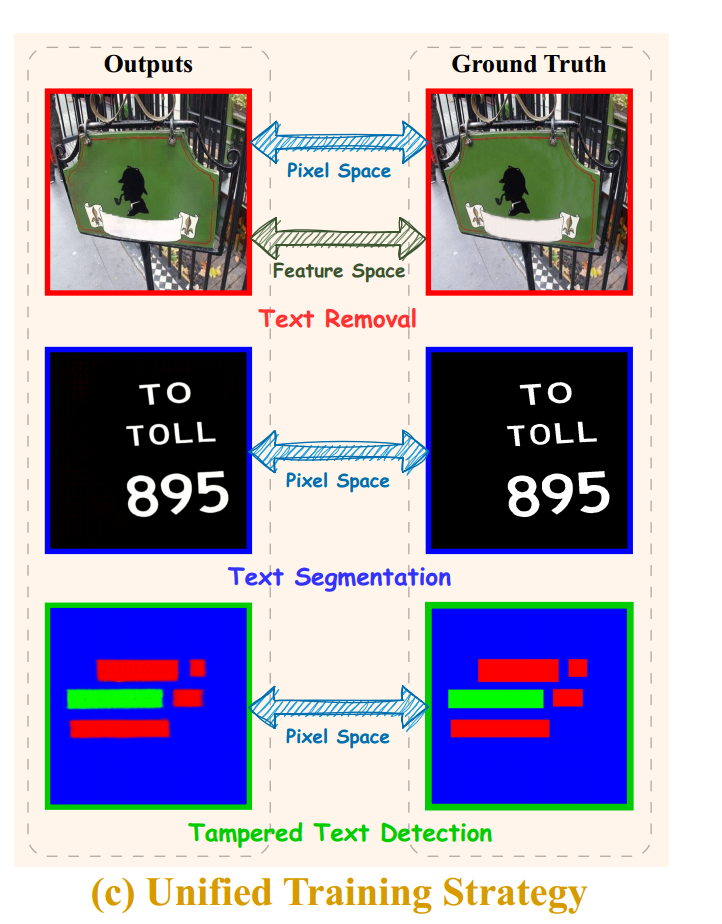
由于模型采用图像到图像的转换范式进行训练,所以在训练过程中,模型优化的目标只需要考虑最小化生成预测图像和真实图像在像素空间和特征空间上的差异,而不用考虑任务之间的差异。
- 像素 空间损失:通过输出图像和真实图像之间的L1距离来测量像素空间中的差异: L p i x = ∑ i = 1 3 α i ∥ I out i − I g t i ∥ 1 L_{p i x}=\sum_{i=1}^{3} \alpha_{i}\left\|\mathbb{I}_{\text {out }}^{i}-\mathbb{I}_{g t}^{i}\right\|_{1} Lpix=∑i=13αi Iout i−Igti 1,其中 I o u t i \mathbb{I}_{out}^{i} Iouti表示输出图像, I g t i \mathbb{I}_{g t}^{i} Igti表示真实图像。
- 特征空间损失:对于与真实图像生成相关联的任务,还需要将输出图像和真实图像在特征空间对齐: L feat = 0.01 × L per + 120 × L sty L_{\text {feat }}=0.01 \times L_{\text {per }}+120 \times L_{\text {sty }} Lfeat =0.01×Lper +120×Lsty
- 整体损失:模型整体损失是像素损失和特征损失的和: L total = L p i x + L feat L_{\text {total }}=L_{p i x}+L_{\text {feat }} Ltotal =Lpix+Lfeat
1.3、UPOCR效果如何?

实验结果如上图三个表所示,左上方表格是文本擦除实验对比,即使与擦除领域专用的精调模型相比,UPOCR统一模型在大部分指标上也领先领域的SOTA方法;右上方表格是文本图像分割实验对比,可以看到,UPOCR在所有指标都比专门单一任务的分割方法好;左下方表格是文本篡改检测,UPOCR也取得了很好的效果。图5显示UPOCR模型设计的任务相关Prompt也可以很好的区分不同的任务,下图是文本擦除、分割、及篡改检测与现有子任务的SOTA方法的可视化对比图。

综上所述,UPOCR提出了一种简单而有效的统一像素级OCR接口,其采用基于ViT的编码器-解码器,通过可学习的任务提示来处理各种任务,在文本去除、文本分割和篡改文本检测等任务上都表现出极高的性能。
二、OCR大一统模型前沿研究速览
2.1、Donut:无需OCR的用于文档理解的Transformer模型
论文地址:https://link.springer.com/chapter/10.1007/978-3-031-19815-1_29
项目地址:https://github.com/clovaai/donut
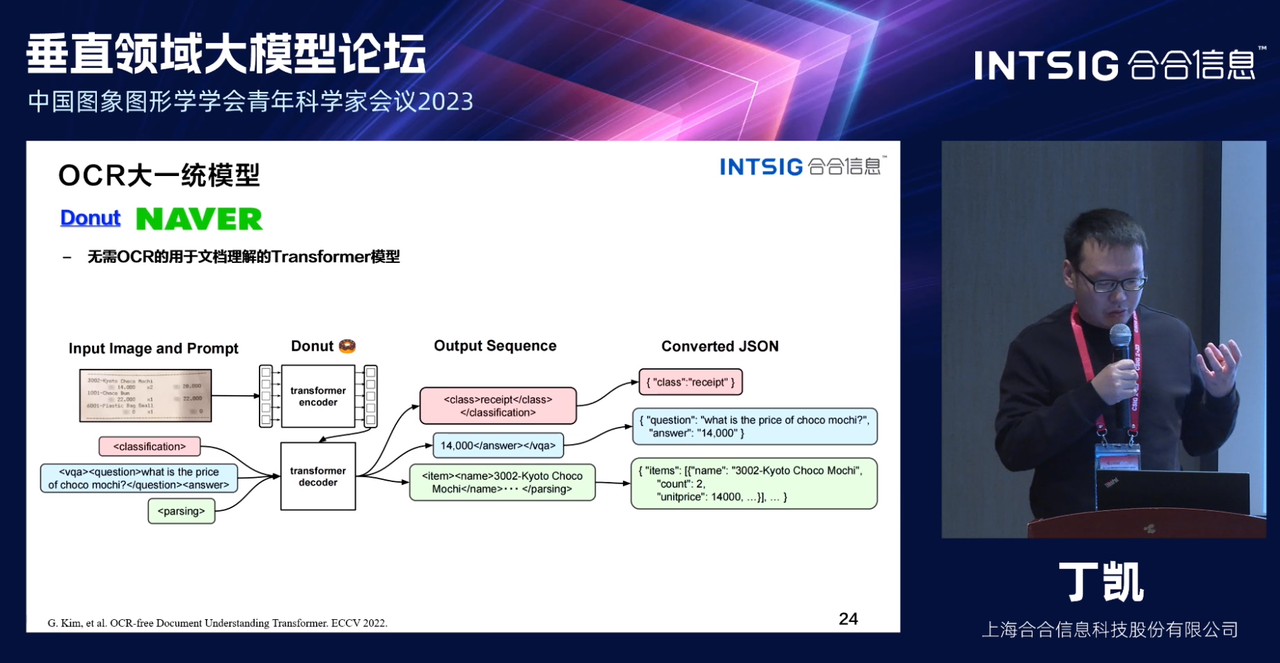
Donut模型是一种基于Transformer架构的新颖的OCR-free VDU模型,Donut模型首先通过一个简单的规则生成布局,然后应用一些图像渲染技术来模拟真实的文档,其通过预训练和微调两个阶段进行训练。在预训练阶段,模型使用IIT-CDIP数据集进行视觉语言建模,学习从图像中读取文本。在微调阶段,模型被训练为生成JSON格式的输出,以解决下游任务,如文档分类、文档信息提取和文档视觉问答等。与其他基于OCR的模型相比,Donut不需要依赖于OCR引擎,因此具有更高的速度和更小的模型大小。在多个公共数据集上进行的实验表明,Donut在文档分类任务中表现出了先进性能。
2.2、NouGAT:实现文档图像到文档序列输出
论文地址:https://arxiv.org/abs/2308.13418
项目地址:https://github.com/facebookresearch/nougat
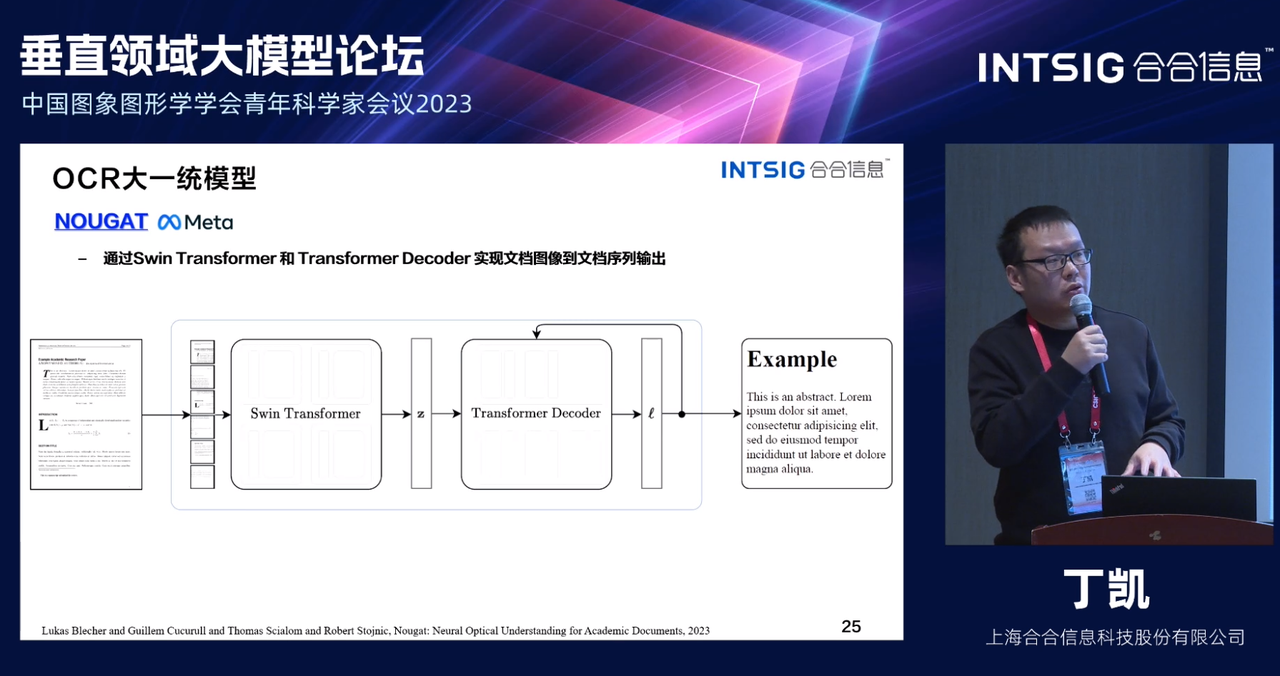
Nougat模型是一种通过Swing Transformer 和 Transformer Decoder实现文档图像到文档序列输出的OCR模型,模型采用基于OCR-free Transformer的端到端训练方法,采用预训练和微调的方式进行训练。在预训练阶段,Donut使用文档图像和它们的文本注释进行预训练,通过结合图像和之前的文本上下文来预测下一个词,从而学习如何读取文本。在微调阶段,Donut根据下游任务学习如何理解整个文档。各种VDU任务和数据集上的大量评估证明了Donut具有较强的理解能力。
2.3、SPTS v3:基于SPTS的OCR大一统模型
论文地址:https://arxiv.org/abs/2112.07917
项目地址:https://github.com/shannanyinxiang/SPTS
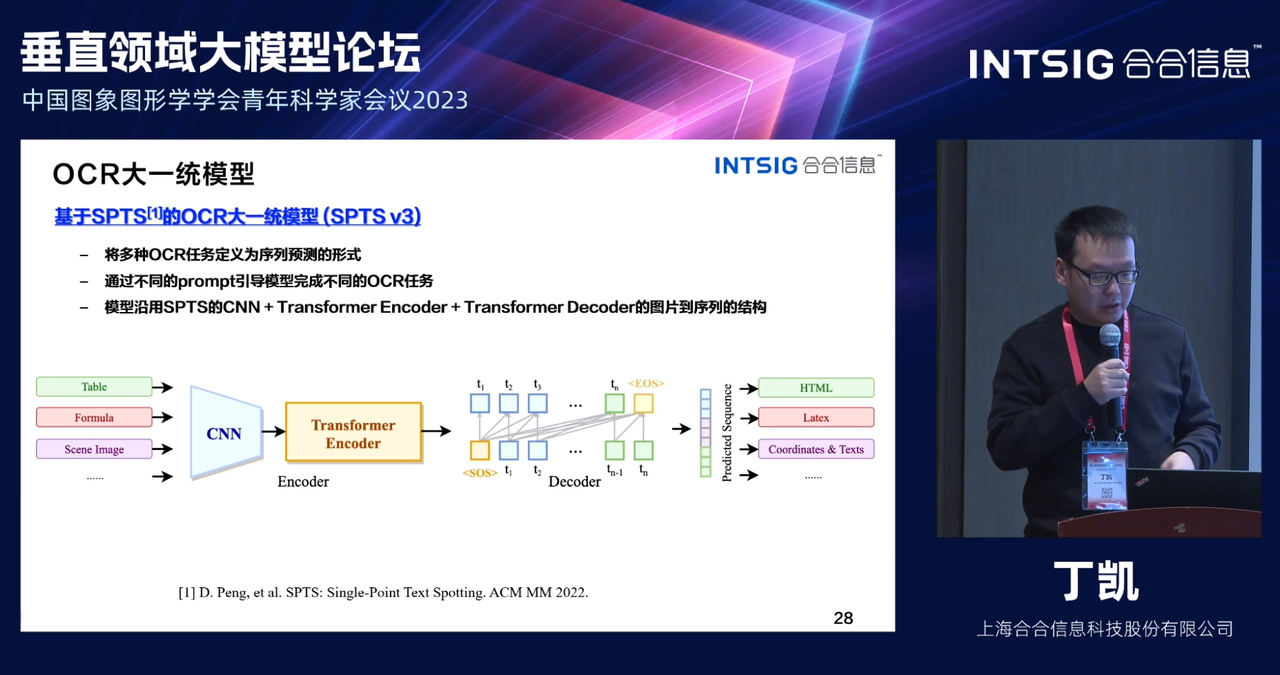
SPTS,全称Single-Point Text Spotting,是一种单点文本识别技术,它的主要创新之处在于:方法使用极低成本的单点标注进行训练将文本检测任务形式化为语言建模任务,只需要对每个文本实例进行单一点的标注,就可以训练出场景文本识别模型。SPTS基于自回归Transformer的框架,可以简单地将结果生成为顺序令牌,从而避免复杂的后处理或独占采样阶段。基于这样一个简洁的框架,SPTS在各种数据集上显示出先进性能。
三、大模型时代下的智能文档处理应用
3.1、LLM与文档识别分析应用
大语言模型能够理解自然语言文本,并具备上下文理解的能力,在文档识别分析应用中,将文档理解相关的工作交给大语言模型,自动进行篇章级的文档理解和分析,可以帮助系统更好地理解文档内容,包括上下文中的关系、实体识别、情感分析等。目前最常见和最广泛的应用包括检索增强生成(RAG)、文档问答。

- 检索增强生成:已经有大语言模型针对从大量文档中检索相关信息,并以生成的方式提供更详细、准确的答案。这在信息检索的场景中具有重要的应用价值。
- 文档问答:LLM可以直接用于构建文档问答系统,使用户能够通过提出问题来获取文档中的相关信息,可以应用于如法律文件的解读、技术手册的查询、知识库理解等场景。
3.2、智能文档处理应用产品
智能文档处理(Intelligent Document Processing,IDP)利用人工智能和机器学习技术来自动分析和理解文档,它通过识别、解析、理解文档内容,并将其转换成可操作的数据或信息,以提高业务流程的自动化程度,提升工作效率,降低成本。
丁凯博士还为我们带来合合信息文档图像识别与分析产品分享,基于这样的智能文档处理技术,产品可以快速、准确地处理大量的文档,帮助银行、保险、物流、供应链、客户服务等多个领域数智化转型,实现更高效、更可靠的业务流程管理。
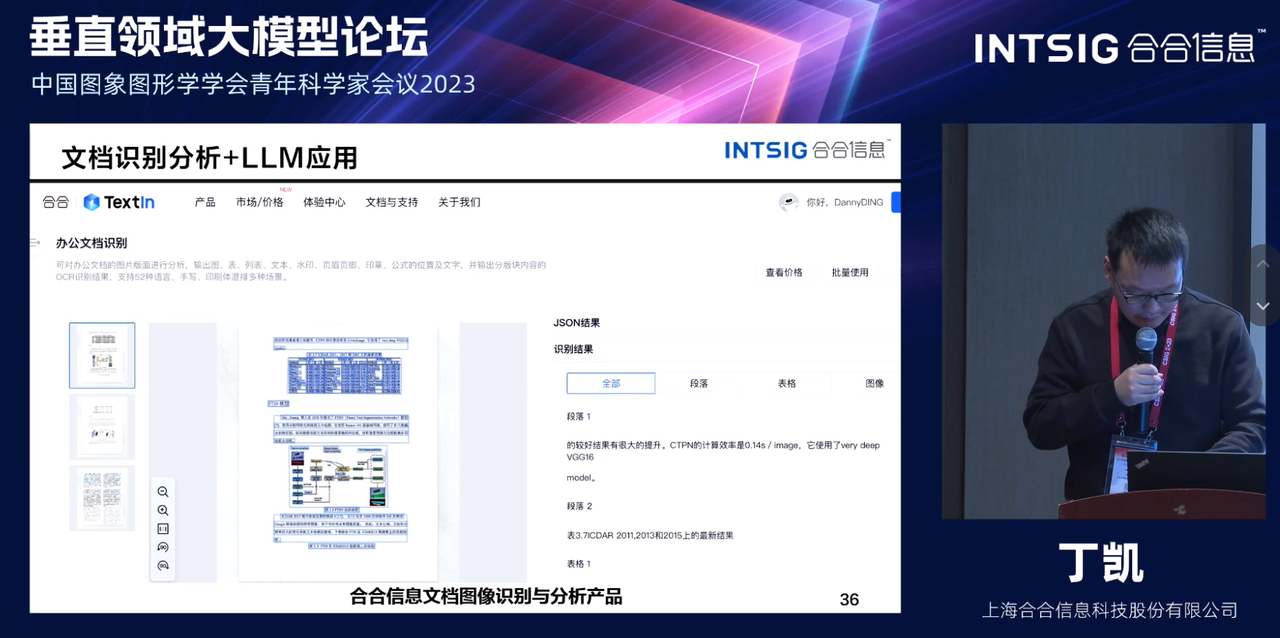
合合信息TextIn智能文字识别产品基于自研的文字识别技术、计算机图形图像技术和智能图像处理引擎,能够快速将纸质文档或图片中的文字信息转化为计算机可读的文本格式,在纸质文档电子化、办公文档/报表识别、教育类文本识别、快递面单识别、切边增强、弯曲矫正、阴影处理、印章检测、手写擦除等诸多场景中提供更好的文档管理解决方案,帮助企业实现数字化转型和自动化管理。
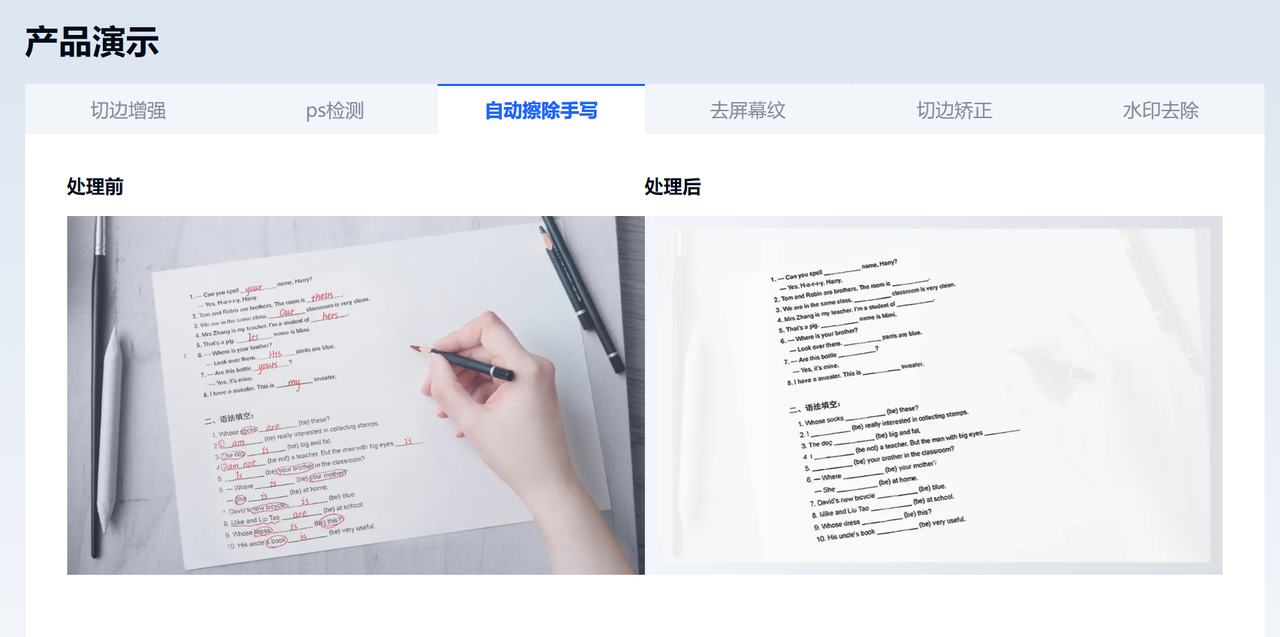
虽然GPT4-V为代表的多模态大模型技术极大的推进了文档识别与分析领域的技术进展,但并没有完全解决图像文档处理领域面临的问题,还有很多问题值得我们研究,如何结合大模型的能力,更好的解决IDP的问题,值得我们做更多的思考和探索。

四、文末抽奖

合合信息给大家送福利了!填写年度问卷:https://qywx.wjx.cn/vm/exOhu6f.aspx,1月12日将随机抽取10个人送50元京东卡,欢迎参与!