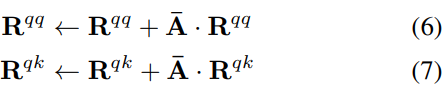在强化学习中,关注智能体在与环境的交互中学习,成为试错型学习。多臂老虎机不存在状态信息,只有动作和奖励,是最简单的“和环境交互中学习“。
什么是多臂老虎机
老虎机_百度百科 (baidu.com) 多臂老虎机即有多个摇杆的老虎机,每个摇杆获得奖励的概率分布 R 不同,每次拉动摇杆,可以根据该摇杆的奖励概率分布,有概率获得奖励 r 。
我们需要在每根拉杆的奖励概率分布未知的情况下,在操作T次后,获得最高的累计奖励,因此需要在寻找获奖概率最高的拉杆和从拉过的杆中选择获奖最多(间接体现在已知的拉杆中获奖概率最高)的拉杆进行权衡。

数学化表达多臂老虎机、累积懊悔与估计期望
数学化形式上表达多臂老虎机
定义一个元组 < A , R > <A,R> <A,R> ,其中:
- A表示动作合集,假定老虎机为K根拉杆,即 < a 1 , . . . . , a K > <a_1,....,a_K> <a1,....,aK> ,每一个动作 a x ∈ A a_x\in A ax∈A ,表示拉动一个第x个拉杆
- R为奖励概率分布,拉动每一根拉杆的动作 a x a_x ax 都对应着一个属于自己的奖励概率分布 R ( r x ∣ a x ) R(r_x|a_x) R(rx∣ax) ,不同拉杆的奖励分布一般不同
每一步只能拉动一个拉杆,则我们的目标为在有限的步数T的情况下,让奖励最大化,即 m a x ∑ t = 1 T r t , r t R ( r t ∣ a t ) max\sum_{t=1}^{T}r_t,r_t~R(r_t|a_t) max∑t=1Trt,rt R(rt∣at)
累积懊悔
对于每一个动作a,定义其期望奖励为 Q ( a ) Q(a) Q(a) (每次拉动不一定获奖,有获奖概率,则也有获奖期望),则至少存在一根拉杆,期望奖励不小于(可能等于)其他任意一个拉杆,将最大、最优期望奖励表示为 Q ∗ = m a x a ∈ A Q ( a ) Q*=max_{a\in A }Q(a) Q∗=maxa∈AQ(a) 。
我们引入懊悔(regret)的概念表示当前动作a与最优拉杆的期望奖励的差,为 R ( a ) = Q ∗ − Q ( a ) R(a)=Q*-Q(a) R(a)=Q∗−Q(a) ,在一些问题中,最大化累计奖励可以等于最小化累计懊悔,为此我们需要了解T次操作后,累计懊悔的表达式 σ R = ∑ t = 1 T R ( a t ) \sigma _R=\sum_{t=1}^{T}R(a_t) σR=∑t=1TR(at)
估计期望奖励
根据每次拉动拉杆得到的奖励,估计各动作的期望奖励。 ∀ a ∈ A \forall a \in A ∀a∈A ,并初始化计数器 N ( a ) = 0 N(a)=0 N(a)=0 ,初始化各动作的期望奖励估值 Q ^ ( a ) = 0 \hat Q(a)=0 Q^(a)=0
- for t=1 → \to → T do
- 选取某根拉杆,记作 a x a_x ax
- 得到奖励 r x r_x rx
- 更新计数器 N ( a x ) = N ( a x ) + 1 N(a_x)=N(a_x)+1 N(ax)=N(ax)+1
- 更新期望奖励估值 Q ^ ( a x ) = Q ^ ( a x ) + 1 N ( a t ) [ r t − Q ^ ( a t ) ] \hat Q(a_x)=\hat Q(a_x)+\frac{1}{N(a_t)}[r_t-\hat Q(a_t)] Q^(ax)=Q^(ax)+N(at)1[rt−Q^(at)]
- end for
最后一步推导过程如下面步骤所示:
Q k = 1 k ∑ i = 1 k r i = 1 k ( r k + ∑ i = 1 k − 1 r i ) = 1 k ( r k + ( k − 1 ) Q k − 1 ) = 1 k ( r k + k Q k − 1 − Q k − 1 ) = Q k − 1 + 1 k [ r k − Q k − 1 ] \begin{aligned} Q_{k}& =\frac1k\sum_{i=1}^kr_i \\ &=\frac{1}{k}\left(r_k+\sum_{i=1}^{k-1}r_i\right) \\ &=\frac1k(r_k+(k-1)Q_{k-1}) \\ &=\frac1k(r_k+kQ_{k-1}-Q_{k-1}) \\ &=Q_{k-1}+\frac1k[r_k-Q_{k-1}] \end{aligned} Qk=k1i=1∑kri=k1(rk+i=1∑k−1ri)=k1(rk+(k−1)Qk−1)=k1(rk+kQk−1−Qk−1)=Qk−1+k1[rk−Qk−1]
下面我们通过代码来表示拉杆数为10的多臂老虎机,每根拉杆奖励服从伯努利分布R统计学(01): 伯努利分布、二项分布 - 知乎 (zhihu.com),奖励为 1 代表获奖,奖励为 0 代表没有获奖。
import numpy as np
import matplotlib.pyplot as pltclass BernoullBandit:#K表示拉杆的个数def __init__(self, K):self.K = Kself.probs=np.random.uniform(size=K) #随机生成K个0-1之间的数,作为拉杆的概率self.bestIdx=np.argmax(self.probs) #返回概率最大的下标self.bestProb=self.probs[self.bestIdx] #最大的获奖概率def step(self,k):# 生成随机数,如果小于self.probs[k],则代表获得奖励1if np.random.rand()<self.probs[k]:return 1else:return 0np.random.seed(1) #设定随机种子,使得实验具有可重复性
K=10
bandit10Arm=BernoullBandit(K)
print(f'初始概率分布:{bandit10Arm.probs}')
print(f'初始概率最大的下标:{bandit10Arm.bestIdx},最大的概率:{bandit10Arm.bestProb}')
初始概率分布:[4.17022005e-01 7.20324493e-01 1.14374817e-04 3.02332573e-011.46755891e-01 9.23385948e-02 1.86260211e-01 3.45560727e-013.96767474e-01 5.38816734e-01]
初始概率最大的下标:1,最大的概率:0.7203244934421581
搭建框架,实现多臂老虎机的求解
class Solver:# 多臂老虎机基本框架def _init_(self,bandit):self.bandit=banditself.counts=np.zeros(self.bandit.K) #记录每个拉杆被点击的次数self.regret=0. #当前步的累积懊悔self.actions=[] #记录每次选择的拉杆self.regrets=[] #记录每一步的累积懊悔def updateRegret(self,k):# 更新当前步的累积懊悔,并保存累积懊悔self.regret+=self.bandit.bestProb-self.bandit.probs[k]self.regrets.append(self.regret)def runOneStep(self):# 返回当前动作选择哪一根杠杆raise NotImplementedErrordef run(self,numSteps):# numSteps为总运行次数for _ in range(numSteps):k=self.runOneStep()self.counts[k]+=1self.actions.append(k)self.updateRegret(k)
本文由博客一文多发平台 OpenWrite 发布!
![[python]gym安装报错ERROR: Failed building wheel for box2d-py](https://img-blog.csdnimg.cn/direct/7f45274d283e4d3d849f9b67567d58a4.png)