一、设计原则之 DevOps
DevOps 一词来自 Development 和 Operation 的组合,突出重视软件开发人员和运维人员的沟通合作,通过自动化流程来使得软件构建、测试、发布更加快捷、频繁和可靠。它要求开发、测试、运维进行一体化的合作,进行更小、更频繁、更自动化的应用发布,以及围绕应用架构来构建基础设施的架构。这就要求应用充分内聚,也方便运维和管理。这个理念与微服务理念不谋而合。
DevOps 的出现是为了填补开发端和运维端之间的信息鸿沟,改善团队之间的协作关系。不过需要澄清的一点是,从开发到运维,中间还有测试环节。DevOps 其实包含了三个部分:开发、测试和运维。
换句话说,DevOps 希望做到的是软件产品交付过程中 IT 工具链的打通,使得各个团队减少时间损耗,更加高效地协同工作。
那么如何来评估 DevOps 的能力呢?可以通过能力环来对环境进行整体评估。DevOps 能力环如图所示。
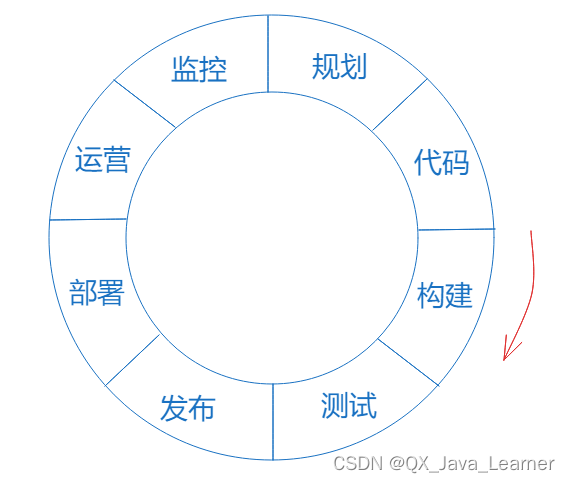
无尽头的可能性:DevOps 涵盖了代码、部署目标的发布和反馈等环节,闭合成一个完整的 DevOps 能力闭环。
良好的闭环可以大大增加整体的产出。
执行 DevOps 的推荐工具如表所示。
| 服务注册与发现 | 部署 | 监控 |
| ZooKeeper Doozer etcd SmartStack Eureka NSQ Serf Spotify DNS SkyDNS Consul | Cloud Foundry Gradle Docker Docker Hub Docker Machine Kitematic Docker Compose Docker Swarm AWS Jenkins Continuum Hudson Artifactory Terraform Grunt OpenShift | SonarCube Logstash New Relic Graphite Mesosphere / DCOS Winston Hystrix |
不同的团队,情况都不相同 —— 不同的技术栈,不同的公司文化,所以要选择适合自身团队的 DevOps 工具。
二、设计原则之无状态服务
对于无状态服务,首先说一下什么是状态:如果一个数据需要被多个服务共享,才能完成一笔交易,那么这个数据被称为状态。进而依赖这个 “状态” 数据的服务被称为有状态服务,反之称为无状态服务。
无状态服务原则并不是说在微服务架构中不允许存在状态,其表达的真实意思是要把有状态的业务服务变无状态的计算类服务,那么状态数据也就相应的迁移到对应的 “有状态数据服务” 中。
场景说明:例如我们以前在本地内存中建立的数据缓存、Session 缓存,到现在的微服务架构中就应该把这些数据迁移到分布式缓存中存储,让业务服务变成一个无状态的计算节点。迁移后,就可以做到按需动态伸缩,微服务应用在运行时动态增删节点,就不再需要考虑缓存数据如何同步的问题。
无状态服务(Stateless Service)对单次请求的处理,不依赖其他请求,也就是说,处理一次请求所需的全部信息,要么都包含在这个请求里,要么可以从外部获取到(比如数据库),服务器本身不存储任何信息。Server 要设计为无状态的。
对服务器来说,究竟是有状态服务,还是无状态服务,其判断依旧是指两个来自相同发起者的请求在服务器端是否具备上下文关系。如果是状态化请求,那么服务器端一般都要保存请求的相关信息,每个请求可以默认地使用以前的请求信息。而对于无状态请求,服务器端所能够处理的过程必须全部来自请求所携带的信息,以及其他服务器端自身所保存的,并且可以被所有请求所使用的公共信息。
无状态的服务程序,最有名的就是 Web 服务器。每次 HTTP 请求和以前都没有关系,只是获取目标 URL。得到目标内容之后,这次连接就被 “杀死”,没有任何痕迹。在后来的发展进程中,逐渐在无状态化的过程中,加入状态化的信息,比如 Cookie。服务端在响应客户端的请求时,会向客户端推送一个 Cookie,这个 Cookie 记录服务端上面的一些信息。客户端在后续的请求中,可以携带这个 Cookie,服务端可以根据这个 Cookie 判断请求的上下文关系。Cookie 的存在,是无状态化向状态化的一个过渡手段,通过外部扩展手段,Cookie 来维护上下文关系。
参考资料:《微服务架构实战》—— 张锋
一 叶 知 秋,奥 妙 玄 心