1. Redis 入门
1.1. Redis 诞生历程
1.1.1.从一个故事开始
08 年的时候有一个意大利西西里岛的小伙子,笔名 antirez(http://invece.org/),创建了一个访客信息网站 LLOOGG.COM。有的时候我们需要知道网站的访问情况,比如访客的 IP、操作系统、浏览器、使用的搜索关键词、所在地区、访问的网页地址等等。在国内,有很多网站提供了这个功能,比如 CNZZ,百度统计,国外也有谷歌的 GoogleAnalytics。我们不用自己写代码去实现这个功能,只需要在全局的 footer 里面嵌入一段JS 代码就行了,当页面被访问的时候,就会自动把访客的信息发送到这些网站统计的服务器,然后我们登录后台就可以查看数据了。
LLOOGG.COM 提供的就是这种功能,它可以查看最多 10000 条的最新浏览记录。这样的话,它需要为每一个网站创建一个列表(List),不同网站的访问记录进入到不同的列表。如果列表的长度超过了用户指定的长度,它需要把最早的记录删除(先进先出)。
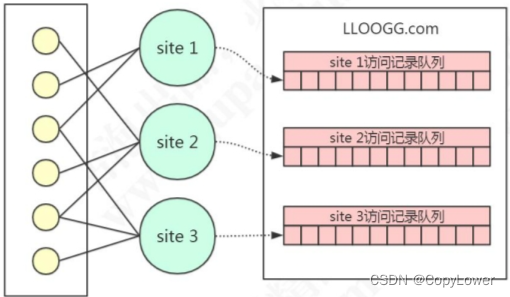
当 LLOOGG.COM 的用户越来越多的时候,它需要维护的列表数量也越来越多,这种记录最新的请求和删除最早的请求的操作也越来越多。LLOOGG.COM 最初使用的数据库是 MySQL,可想而知,因为每一次记录和删除都要读写磁盘,因为数据量和并发量太大,在这种情况下无论怎么去优化数据库都不管用了。
考虑到最终限制数据库性能的瓶颈在于磁盘,所以 antirez 打算放弃磁盘,自己去实现一个具有列表结构的数据库的原型,把数据放在内存而不是磁盘,这样可以大大地提升列表的 push 和 pop 的效率。antirez 发现这种思路确实能解决这个问题,所以用 C 语言重写了这个内存数据库,并且加上了持久化的功能,09 年,Redis 横空出世了。从最开始只支持列表的数据库,到现在支持多种数据类型,并且提供了一系列的高级特性,Redis 已经成为一个在全世界被广泛使用的开源项目。
为什么叫 REDIS 呢?它的全称是 REmote DIctionary Service,直接翻译过来是远程字典服务。
从 Redis 的诞生历史我们看到了,在某些场景中,关系型数据库并不适合用来存储我们的 Web 应用的数据。那么,关系型数据库和非关系型数据库,或者说 SQL 和 NoSQL,到底有什么不一样呢?
1.2. Redis 定位与特性
1.2.1.SQL 与 NoSQL
在绝大部分时候,我们都会首先考虑用关系型数据库来存储我们的数据,比如SQLServer,Oracle,MySQL 等等。
关系型数据库的特点:
1、它以表格的形式,基于行存储数据,是一个二维的模式。
2、它存储的是结构化的数据,数据存储有固定的模式(schema),数据需要适应表结构。
3、表与表之间存在关联(Relationship)。
4、大部分关系型数据库都支持 SQL(结构化查询语言)的操作,支持复杂的关联查询。
5、通过支持事务(ACID 酸)来提供严格或者实时的数据一致性。
但是使用关系型数据库也存在一些限制,比如:
1、要实现扩容的话,只能向上(垂直)扩展,比如磁盘限制了数据的存储,就要扩大磁盘容量,通过堆硬件的方式,不支持动态的扩缩容。水平扩容需要复杂的技术来实现,比如分库分表。
2、表结构修改困难,因此存储的数据格式也受到限制。
3、在高并发和高数据量的情况下,我们的关系型数据库通常会把数据持久化到磁盘,基于磁盘的读写压力比较大。
为了规避关系型数据库的一系列问题,我们就有了非关系型的数据库,我们一般把它叫做“non-relational”或者“Not Only SQL”。NoSQL 最开始是不提供 SQL 的数据库的意思,但是后来意思慢慢地发生了变化。
非关系型数据库的特点:
1、存储非结构化的数据,比如文本、图片、音频、视频。
2、表与表之间没有关联,可扩展性强。
3、保证数据的最终一致性。遵循 BASE(碱)理论。 Basically Available(基本可用); Soft-state(软状态); Eventually Consistent(最终一致性)。
4、支持海量数据的存储和高并发的高效读写。
5、支持分布式,能够对数据进行分片存储,扩缩容简单。
对于不同的存储类型,我们又有各种各样的非关系型数据库,比如有几种常见的类型:
1、KV 存储,用 Key Value 的形式来存储数据。比较常见的有 Redis 和 MemcacheDB。
2、文档存储,MongoDB。
3、列存储,HBase。
4、图存储,这个图(Graph)是数据结构,不是文件格式。Neo4j。
5、对象存储。
6、XML 存储等等等等。
1.2.2.Redis 特性
官网介绍:https://redis.io/topics/introduction
中文网站:http://www.redis.cn
硬件层面有 CPU 的缓存;浏览器也有缓存;手机的应用也有缓存。我们把数据缓存起来的原因就是从原始位置取数据的代价太大了,放在一个临时位置存储起来,取回就可以快一些。
Redis 的特性:
1)更丰富的数据类型
2)进程内与跨进程;单机与分布式
3)功能丰富:持久化机制、过期策略
4)支持多种编程语言
5)高可用,集群
1.3. Redis 启动
1.3.1.服务启动
src 目录下,直接启动
./redis-server
后台启动(指定配置文件)
1、redis.conf 修改两行配置
daemonize yes
bind 0.0.0.0
2、启动 Redis
redis-server /usr/local/soft/redis-5.0.5/redis.conf
总结:redis 的参数可以通过三种方式配置,一种是 redis.conf,一种是启动时--携带的参数,一种是 config set。
1.3.2.基本操作
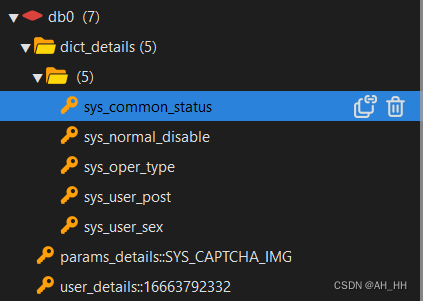
默认有 16 个库(0-15),可以在配置文件中修改,默认使用第一个 db0。
databases 1
因为没有完全隔离,不像数据库的 database,不适合把不同的库分配给不同的业务使用。
切换数据库
select ()
清空当前数据库
flushdb
清空所有数据库
flushall
Redis 是字典结构的存储方式,采用 key-value 存储。key 和 value 的最大长度限制是 512M(来自官网 https://redis.io/topics/data-types-intro/)。
键的基本操作。
命令参考:http://redisdoc.com/index.html
存值
set qingshan 2673
取值
get qingshan查看所有键
keys *
获取键总数
dbsize
查看键是否存在
exists qingshan
删除键
del qingshan jack
重命名键
rename qingshan pengyuyan
查看类型
type qingshan
Redis 一共有几种数据类型?(注意是数据类型不是数据结构)
官网:https://redis.io/topics/data-types-intro
String、Hash、Set、List、Zset、Hyperloglog、Geo、Streams
1.4. Redis 基本数据类型
最基本也是最常用的数据类型就是 String。set 和 get 命令就是 String 的操作命令。为什么叫 Binary-safe strings 呢?
1.4.1.String 字符串
存储类型
可以用来存储字符串、整数、浮点数。
操作命令
设置多个值(批量操作,原子性)
mset qingshan 2673 jack 66
设置值,如果 key 存在,则不成功
setnx qingshan
基于此可实现分布式锁。用 del key 释放锁。
但如果释放锁的操作失败了,导致其他节点永远获取不到锁,怎么办?
加过期时间。单独用 expire 加过期,也失败了,无法保证原子性,怎么办?多参数
set key value [expiration EX seconds|PX milliseconds][NX|XX]
使用参数的方式
set lock1 1 EX 10 NX
(整数)值递增
incr qingshan
incrby qingshan 100
(整数)值递减
decr qingshan
decrby qingshan 100
浮点数增量
set f 2.6
incrbyfloat f 7.3
获取多个值
mget qingshan jack
获取值长度
strlen qingshan
字符串追加内容
append qingshan good
获取指定范围的字符
getrange qingshan 0 8
存储(实现)原理
数据模型
set hello word 为例,因为 Redis 是 KV 的数据库,它是通过 hashtable 实现的(我们把这个叫做外层的哈希)。所以每个键值对都会有一个 dictEntry(源码位置:dict.h),里面指向了 key 和 和 value 的指针。next 指向下一个 dictEntry。
typedef struct dictEntry {void *key; /* key 关键字定义 */union {void *val; uint64_t u64; /* value 定义 */int64_t s64; double d;} v;struct dictEntry *next; /* 指向下一个键值对节点 */
} dictEntry
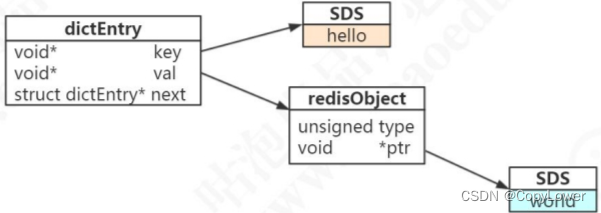
key 是字符串,但是 Redis 没有直接使用 C 的字符数组,而是存储在自定义的 SDS中。
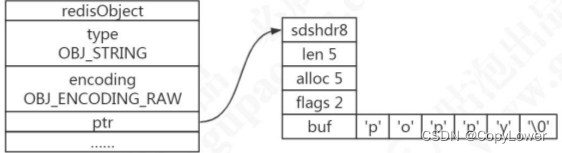
value 既不是直接作为字符串存储,也不是直接存储在 SDS 中,而是存储在redisObject 中。实际上五种常用的数据类型的任何一种,都是通过 redisObject 来存储的。
redisObject
redisObject 定义在 src/server.h 文件中。
typedef struct redisObject {unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */unsigned encoding:4; /* 具体的数据结构 */unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了*/void *ptr; /* 指向对象实际的数据结构 */
} robj;
可以使用 type 命令来查看对外的类型。
127.0.0.1:6379> type qs
string
127.0.0.1:6379> set number 1
OK
127.0.0.1:6379> set qs "is a good teacher in gupao, have crossed mountains and sea " OK
127.0.0.1:6379> set jack bighead
OK
127.0.0.1:6379> object encoding number “int” 127.0.0.1:6379> object encoding jack
“embstr” 127.0.0.1:6379> object encoding qs "raw
字符串类型的内部编码有三种:
1、int,存储 8 个字节的长整型(long,2^63-1)。
2、embstr, 代表 embstr 格式的 SDS(Simple Dynamic String 简单动态字符串),存储小于 44 个字节的字符串。
3、raw,存储大于 44 个字节的字符串(3.2 版本之前是 39 字节)。为什么是 39?
/* object.c */
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 4