Zookeeper 数据写入与分布式锁
- 1.数据是怎么写入的
- 2.基于 Zookeeper 实现分布式锁
1.数据是怎么写入的
无论是 Zookeeper 自带的客户端 zkCli.sh,还是使用 Python(或者其它语言)实现的客户端,本质上都是连接至集群,然后往里面读写数据。那么问题来了,集群在收到来自客户端的写请求时,是怎么写入数据的呢?
另外客户端在访问集群的时候,本质上是访问集群内的某一个节点,而根据访问的节点是领导者还是追随者,写入数据的过程也会有所不同。
先来看看当 访问的节点是领导者 的情况:
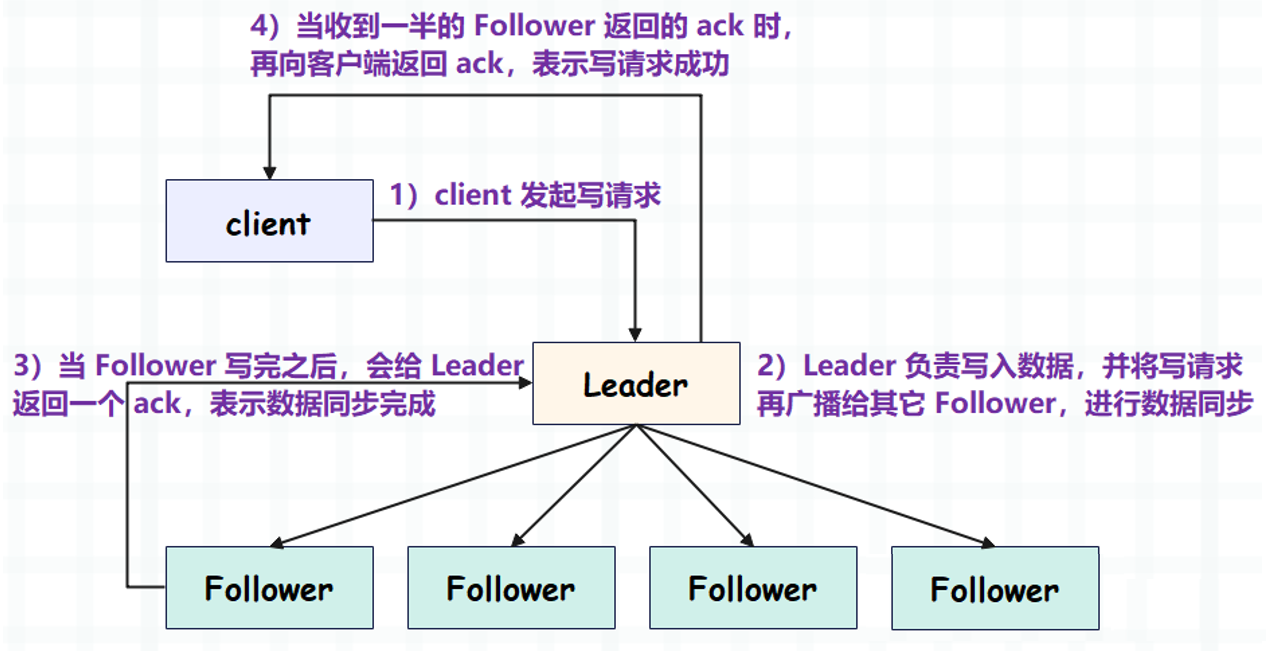
这里面有一个关键的地方,就是 Leader 不会等到所有的 Follower 都写完,只要有一半的 Follower 写完,就会告知客户端。还是半数机制,一半的 Follower 加上 Leader 正好刚过半数。而这么做的原因也很简单,就是为了快速响应。
再来看另一种情况,如果客户端 访问的节点是追随者,情况会怎么样呢?其实很简单,由于追随者没有写权限,那么会先将写请求转发给领导者,然后接下来的步骤和上面类似,只是最后一步不同。
当 Leader 发现有半数的 Follower 写完,就认为写数据成功,于是返回 ack。但这个 ack 不会返回给客户端,因为客户端访问的不是领导者,最终领导者会将 ack 返回给客户端访问的追随者,再由这个追随者将 ack 返回给客户端,告知写请求已执行完毕。
2.基于 Zookeeper 实现分布式锁
关于分布式锁,我之前介绍过如何基于 Redis 实现分布式锁,里面对分布式锁做了比较详细的解析。下面来聊一聊如何基于 Zookeeper 实现分布式锁。
先来说一下原理,当客户端需要操作共享资源时,需要先往 Zookeeper 集群中创建一个临时顺序节点。然后查看对应的编号,如果没有比它小的,说明最先创建,我们就认为客户端拿到了分布式锁。
如果客户端发现节点的编号不是最小的,说明已经有人先创建了,也就是锁已经被别的客户端拿走了。那么该客户端会对前一个节点进行监听,等待释放。
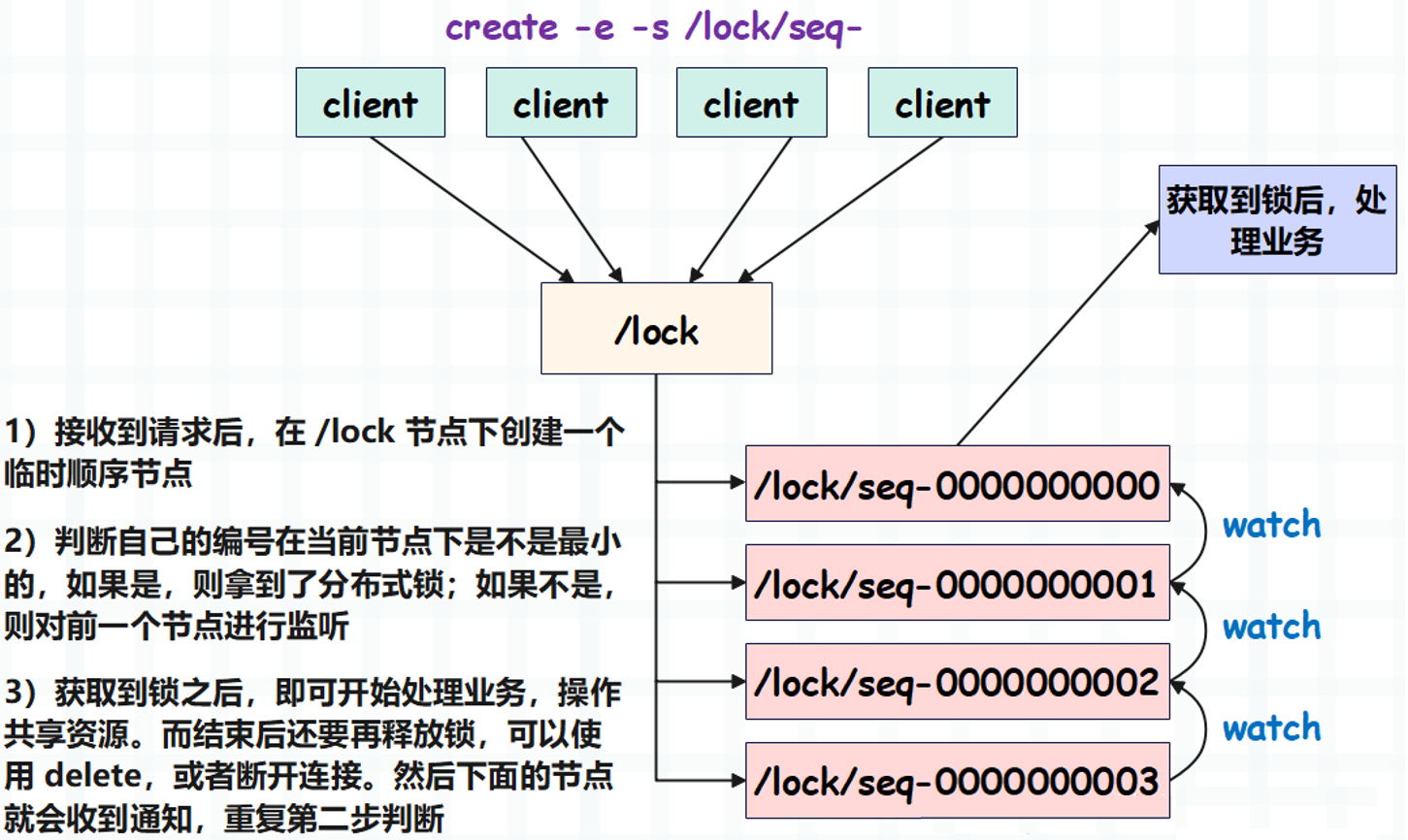
所以从概念上还是很好理解的,然后我们来编程实现一下。
from typing import List
import queue
from kazoo.client import KazooClientclass DistributedLock:def __init__(self, hosts: List[str]):""":param hosts: 'ip1:port1,...'"""self.client = KazooClient(",".join(hosts))self.client.start()# 要在 /lock 节点下面创建临时顺序节点# 所以先保证 /lock 节点存在if not self.client.exists("/lock"):self.client.create("/lock")# 要创建的临时顺序节点self.cur_node = None# 要监听的节点(也就是上一个节点)self.prev_node = None# 本地队列self.q = queue.Queue()def acquire(self):"""获取锁:return:"""self.cur_node = self.client.create("/lock/seq-",# 临时顺序节点ephemeral=True,sequence=True)# create 方法会返回创建的节点名称# 需要判断编号是不是最小的# 因此要拿到所有的节点nodes = self.client.get_children("/lock")# nodes: ["seq-000..0", "seq-000...1"]nodes.sort()if len(nodes) == 1:return Trueelif "/lock/" + nodes[0] == self.cur_node:# 如果 nodes 里面的最小值和 node 相等# 说明该客户端创建的节点的编号最小# 于是我们就认为它拿到了分布式锁return True# 否则说明不是最小,因此要找到它的上一个节点# 也就是要监听的节点index = nodes.index(self.cur_node.split("/")[-1])self.prev_node = "/lock/" + nodes[index - 1]# 对上一个节点进行监听self.client.get(self.prev_node, watch=self.watch)# 这一步不是阻塞的,但程序必须要拿到锁之后才可以执行# 所以我们要显式地让程序阻塞在这里self.q.get()return Truedef release(self):"""释放锁:return:"""self.client.delete(self.cur_node)def watch(self, event):"""监听函数,参数 event 是一个 namedtuplekazoo.protocol.states.WatchedEvent里面有三个字段:type、state、path监听节点的值被改变时,type 为 "CHANGED"监听节点被删除时,type 为 "DELETED"path 就是监听的节点本身state 表示客户端和服务端之间的连接状态建立连接时,状态为 LOST连接建立成功,状态为 CONNECTED如果在整个会话的生命周期里,伴随着网络闪断、服务端异常或者其他什么原因导致客户端和服务端连接断开,状态为 SUSPENDED与此同时,KazooClient 会不断尝试与服务端建立连接,直至超时如果连接建立成功了,那么状态会再次切换到 CONNECTED"""if event.type == "DELETED" and \self.prev_node == event.path:# 往队列里面扔一个元素# 让下一个节点解除阻塞self.q.put(None)# 测试函数
def test(lock, name):lock.acquire()print(f"{name}获得锁,其它人等着吧")print(f"{name}处理业务······")print(f"{name}处理完毕,释放锁")lock.release()if __name__ == '__main__':import threadinghosts = ["82.157.146.194:2181", "121.37.165.252:2181", "123.60.7.226:2181", ]# 创建三把锁lock1 = DistributedLock(hosts)lock2 = DistributedLock(hosts)lock3 = DistributedLock(hosts)threading.Thread(target=test, args=(lock1, "客户端1")).start()threading.Thread(target=test, args=(lock2, "客户端2")).start()threading.Thread(target=test, args=(lock3, "客户端3")).start()"""
客户端1获得锁,其它人等着吧
客户端1处理业务······
客户端1处理完毕,释放锁
客户端3获得锁,其它人等着吧
客户端3处理业务······
客户端3处理完毕,释放锁
客户端2获得锁,其它人等着吧
客户端2处理业务······
客户端2处理完毕,释放锁
"""
实现起来不是很难,并且使用 Zookeeper 的好处就是,我们不需要担心死锁的问题。因为客户端宕掉之后,临时节点会自动删除,但缺点是性能没有 Redis 高。
另外值得一提的是,kazoo 已经帮我们实现好了分布式锁,开箱即用,我们就不需要再手动实现了。
# 创建客户端
client = KazooClient(",".join(hosts))
client.start()
# 此时需要自己手动给一个唯一标识
lock = client.Lock("/lock", "unique-identifier")
# 获取锁
lock.acquire()
# 处理业务逻辑
...
# 释放锁
lock.release()
# 或者也可以使用上下文管理器
with lock:...
显然就优雅多了,借助于 kazoo 实现好的分布式锁,可以减轻我们的心智负担。此外 kazoo 还提供了 读锁 和 写锁:
client.ReadLockclient.WriteLock
我们一般使用 client.Lock 就行,可以自己测试一下。
关于 Zookeeper 的基础内容就介绍到这里,但伴随着 Zookeeper 还有一系列的协议,比如 Paxos 协议、ZAB 协议、CAP 定理 等等,这些可谓是分布式系统的重中之重。我们后续来逐一介绍。