创建RDD
程序入口 SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName(spark_context")
val sc: SparkContext = new SparkContext(conf)-
SparkContext 是 spark-core 的入口组件,是一个 Spark 程序的入口,在 Spark 0.x 版本就已经存在 SparkContext 了,是一个元老级的API
-
如果把一个 Spark 程序分为前后端,那么服务就是可以运行 Spark 程序的集群,而 Driver 就是 Spark 的前端,
在 Driver 中, SparkContext 是最主要的组件,也是 Driver 在运行时首先会创建的组件,是 Driver 的核心
-
SparkContext 从提供的 API 来看,主要作用是连接集群,创建 RDD , 累加器,广播变量等
简略的说,RDD 有三种创建方式
- RDD 可以通过本地集合创建RDD
- RDD 可以通过外部数据创建RDD
- RDD 可以通过其它的RDD衍生新的RDD
通过本地集合创建RDD
@Test
def rddCreationLocal(): Unit = {val seq = Seq("Hello1", "Hello2", "Hello3") // 里面数据是什么类型val rdd1:RDD[String] = sc.parallelize(seq, 2) // RDD的里面的泛型就是什么类型, 指定为2个分区数sc.parallelize(seq) // parallelize 可以不指定分区数val rdd2: RDD[String] = sc.makeRDD(seq,2)
}通过外部数据创建RDD
@Test
def rddCreationFiles(): Unit = {sc.textFile("hdfs:///.....")// 1. textFile中传入的是什么// * 传入的是一个路径,读取路径// * hdfs:// file:// /.../...(这种方式分为在集群中执行还是在本地中执行,如果在集群中,读的是hdfs,本地读的是文件系统)// 2. textFile是否支持分区?// * 假如传入的path是 hdfs://....// * 分区是由 HDFS 中文件的 block 决定的// 3. textFile支持什么平台// * 支持 aws 和 阿里云
}通过其它的RDD衍生新的RDD
@Test
def rddCreateFromRDD(): Unit = {val rdd1 = sc.parallelize(Seq(1, 2, 3))// 通过在 rdd 上执行算子操作,会生成新的 rdd// 原地计算// java中,str.substr 返回新的字符串,非原地计算// 通过rdd1.map 的操作 ,和字符串中的方式很像, 字符串可变吗?不可变// RDD 可变吗? 不可变val rdd2: RDD[Int] = rdd1.map(item => item)
}RDD的算子操作
-
map 算子
# spark-shell sc.parallelize(Seq(1, 2, 3)).map( num => num * 10).collect()# IDEA @Test def mapTest(): Unit = {// 1. 创建RDDval rdd1 = sc.parallelize(Seq(1, 2, 3))// 2. 执行 map 操作val rdd2 = rdd1.map(item => item * 10)// 3. 得到结果val result:Array[Int] = rdd2.collect()result.foreach(item => println(item))// 关闭scsc.stop() }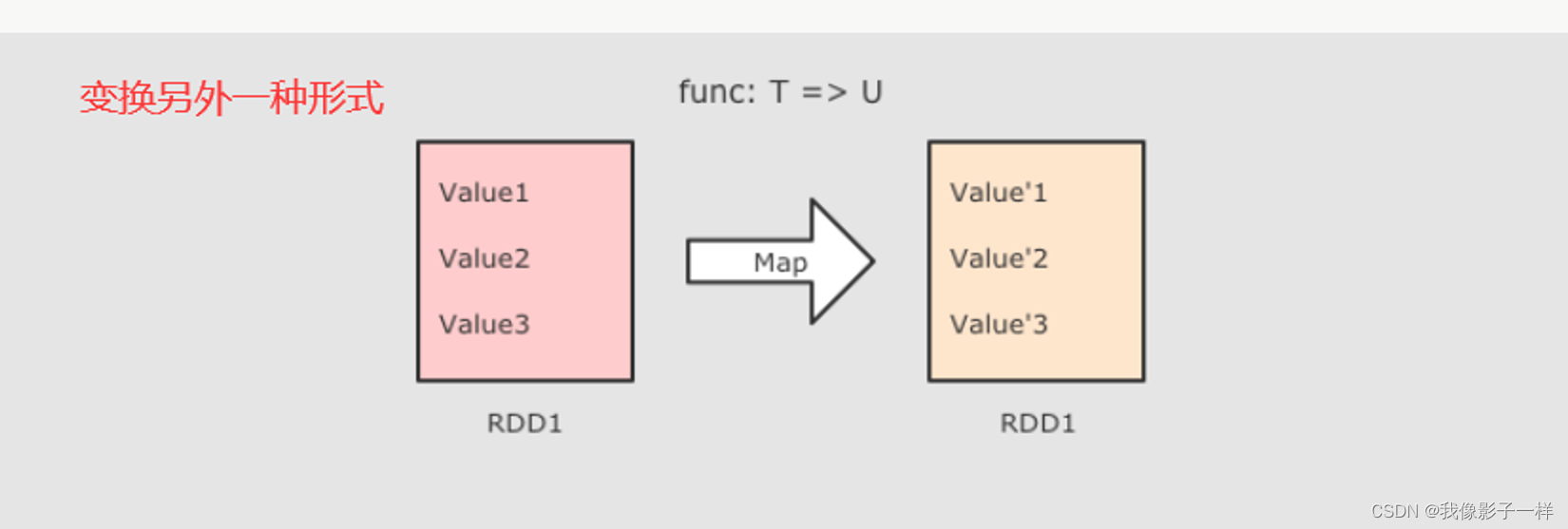


- 作用
- 把 RDD 中的数据 一对一的转换为另一种形式
- 调用
def map[U: ClassTag] (f: T ⇒ U) : RDD[U]
- 参数
- f → map 算子是 原 RDD → 新 RDD 的过程, 这个函数的参数是原 RDD 的数据, 返回值是经过函数转换的新 RDD 的数据
- 注意点
- map 是一对一, 如果函数是
String → Array[String]则新的 RDD 中每条数据就是一个数组
- map 是一对一, 如果函数是
- 作用
-
FlatMap算子
# spark-shell sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")).flatMap( line => line.split(" ")).collect()# IDEA @Test def flatMapTest(): Unit = {// 1. 创建RDDval rdd1 = sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim"))// 2. 执行 flatMap 操作val rdd2 = rdd1.flatMap( line => line.split(" "))// 3. 得到结果val result:Array[String] = rdd2.collect()result.foreach(line => (println(line)))// 关闭scsc.stop() }*

- 作用
- flatMap 算子和 map 算子类似, 但是 FlatMap 是一对多
- 调用
def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U]
- 参数
f→ 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD
- 注意点
- flatMap 其实是两个操作, 是
map + flatten, 也就是先转换, 后把转换而来的 List 展开 - flatMap 也是转换,他可以把数组和集合展开,并且flatMap中的函数一般也是集合或者数组
- flatMap 其实是两个操作, 是
- 作用
-
ReduceByKey算子
# spark-shell sc.parallelize(Seq(("a",1), ("a", 1), ("b", 1))).reduceByKey( ( cur, agg) => cur + agg).collect()# IDEA @Test def reduceByKeyTest(): Unit = {// 1. 创建RDDval rdd1 = sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim"))// 2. 处理数据val rdd2 = rdd1.flatMap( item => item.split(" ")).map(item => (item, 1)).reduceByKey( (cur, agg) => cur + agg)// 3. 得到结果val result:Array[(String, Int)] = rdd2.collect()result.foreach(item => (println(item)))// 4. 关闭scsc.stop() }

- 作用
- 首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
- 调用
def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)]
- 参数
- func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
- 注意点
- ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple
- ReduceByKey 是一个需要 Shuffled 的操作
- 和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
- reduceByKey第一步是按照Key进行分组,然后对每一组进行聚合得到结果
- 作用