分页查询优化
主键排序

在实际的使用中,通过limit 10000,10 查询第10000记录到10010记录,mysql执行的时候是按照将前10010记录全部统计出来,然后剔除前10000条记录,选择后10条记录。这样来看的话,效率不高。

如果数据是有序的,那么可以直接使用上面这种方式,发现使用了索引,在于这种方式是通过id选择大于10000的数据。两种方式不同。但是如果数据有删除的可能,那么不推荐使用这种方式。并且这种方式需要主键连续才可以。
非主键排序

但是如果使用 order by name limit,发现没有走索引,具体原因就是mysql优化器发现走索引之后的成本还不如全表查询,放弃了索引。
如何优化呢?
关键点其实就是尽可能使用较少的字段排序。如下只使用主键id排序。指向效率大大高于上面这个。

Join关联查询优化
-- 示例表:
CREATE TABLE `t1` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;create table t2 like t1;
-- 插入一些示例数据
-- 往t1表插入1万行记录
drop procedure if exists insert_t1; delimiter ;;
create procedure insert_t1()
begindeclare i int;set i=1;while(i<=10000)doinsert into t1(a,b) values(i,i);set i=i+1;end while;end;;delimiter ;call insert_t1();
-- 往t2表插入100行记录
drop procedure if exists insert_t2; delimiter ;;
create procedure insert_t2()
begindeclare i int;set i=1;while(i<=100)doinsert into t2(a,b) values(i,i);set i=i+1;end while;
end;;
delimiter ;
call insert_t2();
上述的SQL 我们创建了两个结构一样的表T1和T2,T1插入1W行数据。T2插入100条记录。
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
那么针对上述的这个SQL,MySQL内部是怎么执行的?
有两种执行算法,决定选择哪个算法取决于关联字段是否有索引。
- Nested-Loop Join算法 (关联字段有索引)
- Block Nested-Loop Join算法 (关联字段没有索引)
嵌套循环连接 Nested-Loop Join(NLJ) 算法
嵌套循环执行其实就是每次驱动表拿出一条记录,在这样记录找到关联的字段,根据关联字段在另一张表(驱动表)取出满足条件的行。然后汇总结果。

从图中可以看出,以下信息
- 因为id相同,所以T2就是驱动表,T1是被驱动表,小表驱动大表。inner join前的表不一定就是驱动表,mysql会优化。
- 对于 left join来说,左表是驱动表,右表是被驱动表。right join相反。所以需要合理选择驱动表。
- 使用了NLJ算法,在join语句中,没有显示Using join buffer,表示使用的join算法是NLJ。
上述的整体流程其实就是
1.T2每次从表中取出一条记录。在和T1中符合条件的数据匹配,将结果存储起来。最后直到执行完毕所有的结果。T2扫描100行。T1扫描100行。一共是200行。
基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
本算法其实就是将驱动表T2全部数据拉到内存 join buffer中,然后扫描被驱动表,将被驱动表的每一行都取出来根join_buffer的数据进行对比。 图中显示的是using join buffer说明使用的是BNL算法。

上述的整体流程
其实就是将T2中的全部100行数据拉到join buffer中,然后把表T1中每一行数据都取出来,进行对比。我们来分析下扫描的行数。T2是100行,T1是1W行,在内存中执行需要 100 * 10000 = 100万次比较。
因为join_buffer_size是有限制的,默认是256K,如果超过这个范围,就是分段放。
思考
为什么对于没有索引的关联字段使用BNL算法,而不是Nested-Loop Join算法呢。
我们来分析,如果采用Nested-Loop Join算法,因为关联的b 字段没有索引,所以也就是T2和T1在次盘层面扫描100 * 10000 = 100W次。这个效率很慢的,相比于BNL算法在内存中比较100W次效率肯定更快。
好了,这里简单总结下,其实对于join的方式,不建议3张表以上的操作,并且对于关联字段要使用索引,选择NLJ算法,而不是BNL算法。小表驱动大表。straight_join 知道哪个是小表,可以使用straight_join进行指定。
EXPLAIN select * from t1 straight_join t2 on t1.a= t2.a;
straight_join 就制定了一个大表T1。
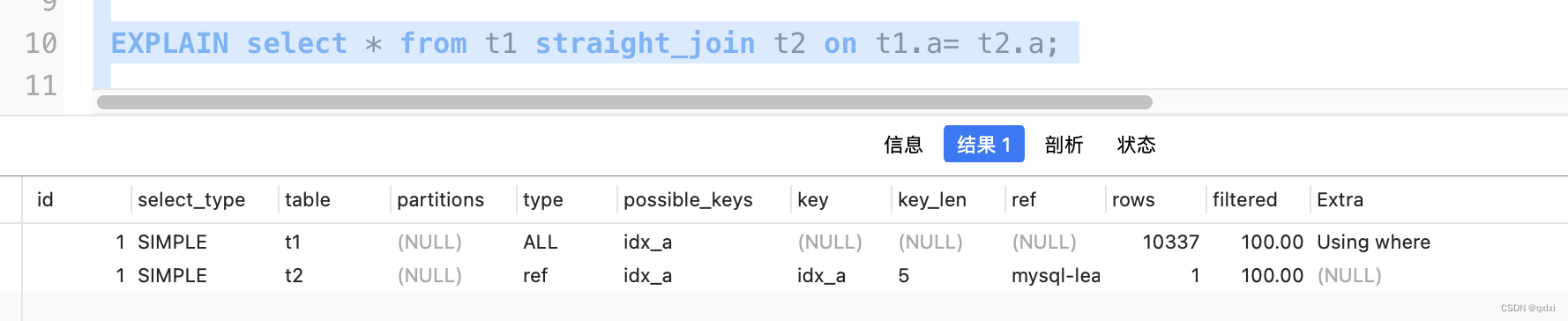
EXPLAIN select * from t2 straight_join t1 on t1.a= t2.a;
执行了T2,明显比上面的性能更好

- straight_join只适用于inner join,并不适用于left join,right join。(因为left join,right join已经代表指 定了表的执行顺序)
小表的定义
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
in和exsits优化
in : 表B的数据集小于A表的数据集时,in由于exists
select * from A where id in (select id from B)
#等价于:
for(select id from B){select * from A where A.id = B.id 5
}
exists:当A表的数据集小于B表的数据集时,exists优于in
select * from A where exists (select 1 from B where B.id = A.id) 2 #等价于:for(select * from A){select * from B where B.id = A.id
}#A表与B表的ID字段应建立索引
count(*) 查询优化
EXPLAIN SELECT count(1) FROM employees;EXPLAIN SELECT count(*) FROM employees;EXPLAIN SELECT count(name) FROM employees;EXPLAIN SELECT count(id) FROM employees;
字段有索引:count( * ) ≈ count(1) > count(字段) >count(主键 id) 字段有索引,count(字段)统计走二级索引,二 级索引存储数据比主键索引少,所以 count(字段)>count(主键 id)
字段无索引:count( * )≈count(1)>count(主键 id)>count(字段) //字段没有索引count(字段)统计走不了索引, count(主键 id)还可以走主键索引,所以count(主键 id)>count(字段)
count(1) : 其实就是把每一行的数据取出来,然后填充1 进行累加。
count(id) : 将每一行的主键id拿出来,累加。
count(*) : 不会将每一行的数据直接取出来,而是做了优化。累加。
coungt(字段):其实统计的是字段不为空的数据。
有什么统计总行数的解决方案?
1.如果存储引擎是MyISAM,会存储在磁盘可以直接获取。但是InnoDB中的MVCC机制,会导致记录的行数不准确,所以没有。
2.show table status
SHOW TABLE STATUS LIKE 'employees';
3.通过redis或者数据技术表进行统计
阿里MySQL规范
在MySQL中选择正确的数据类型,可以减少磁盘空间,以及对查询性能有一定的提高。
1.确定合适的大类型:数值、字符串、时间、二进制等
2.选择具体的类型:有无符号,取值范围,变长定长等。
尽量把字段定义为not null ,不要null
数值类型
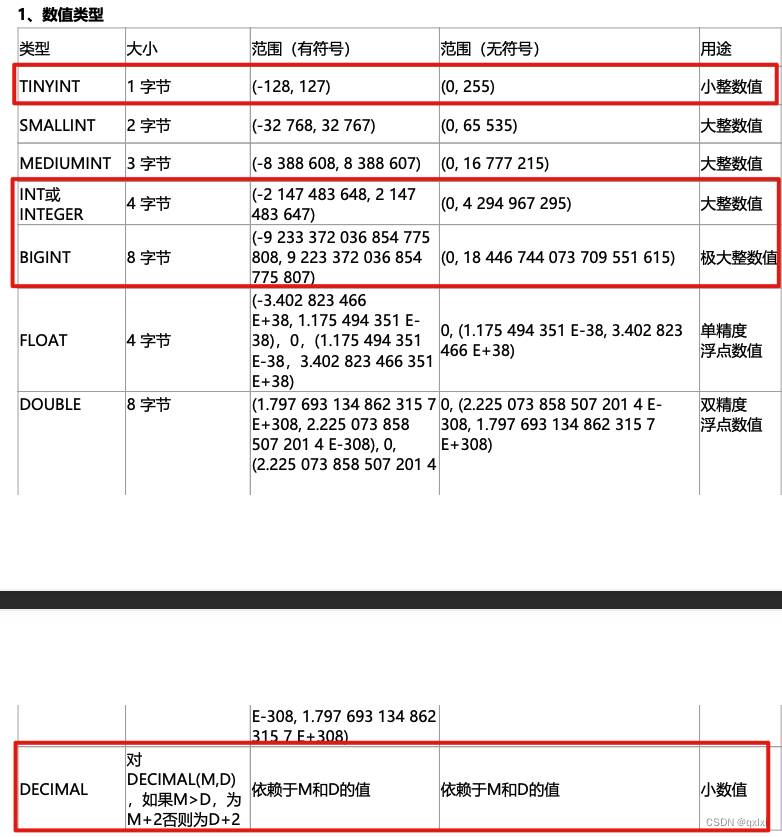
- 1.如果整形数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍。
- 2.DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。
时间类型

- 建议用DATE数据类型来保存日期。MySQL中默认的日期格式是yyyy-mm-dd。
- 当数据格式为TIMESTAMP和DATETIME时,可以用CURRENT_TIMESTAMP作为默认(MySQL5.6以后), MySQL会自动返回记录插入的确切时间
字符串类型
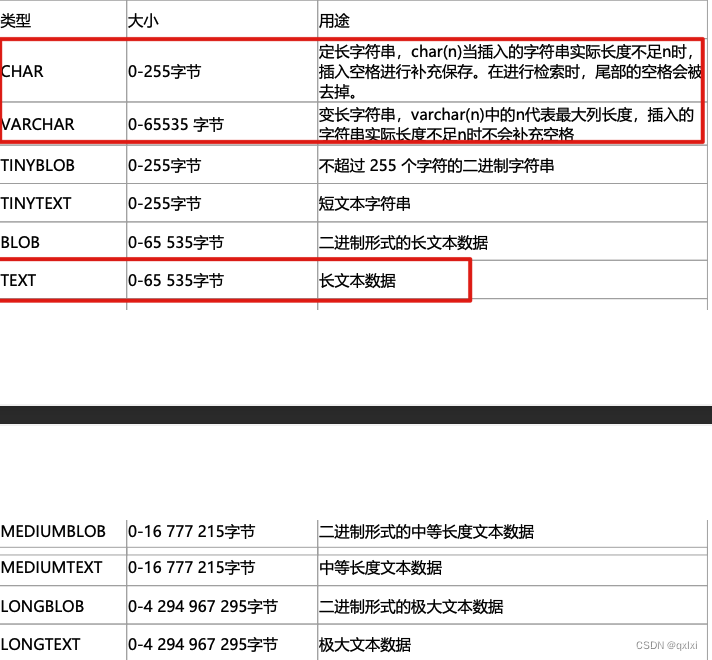
- char 定长字符串、varchar 非定长字符串,
- 如果存储的字符串长度几乎相等,使用char,比如存储 UUID这种,但是如果不是固定的,那么使用varchar。
小总结
本篇从limit、join 、count 、以及对应的数据类型 介绍了如何优化SQL。结合上一篇。
常见的索引SQL优化就介绍完毕了。