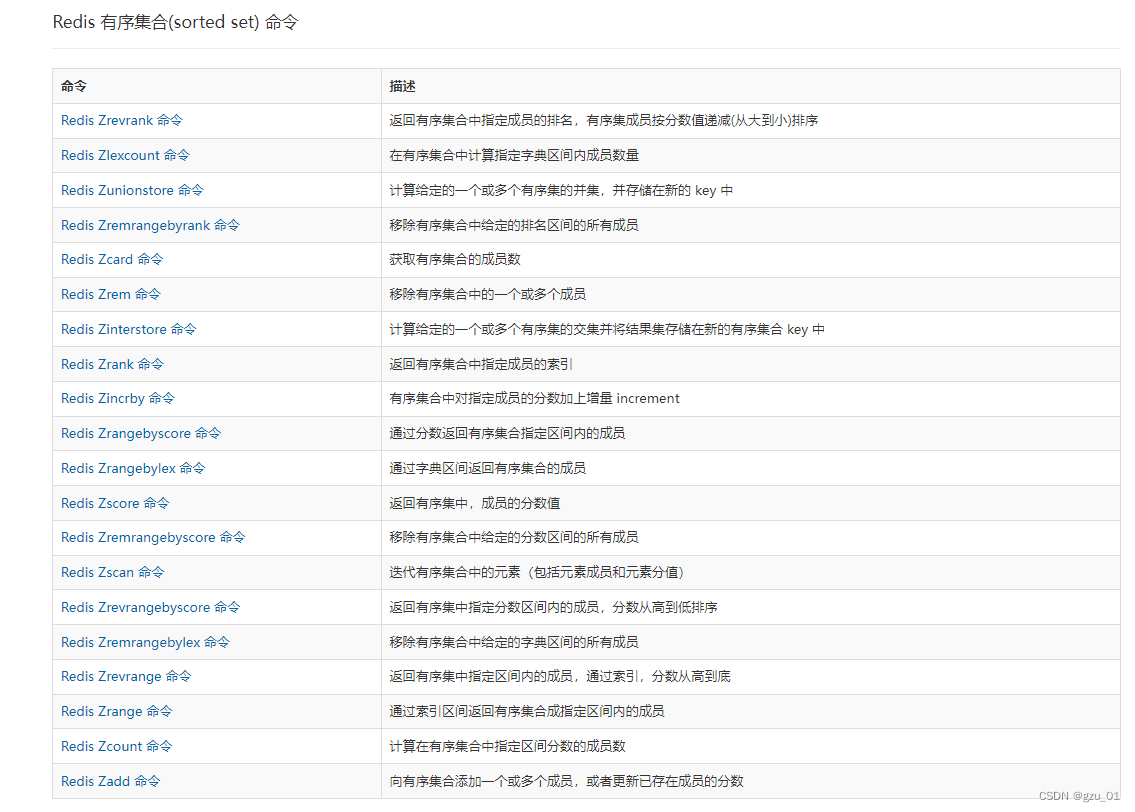
文章目录
- 1. 索引介绍
- 2. 创建索引 create index…on…
- 2.1 explain
- 2.2 创建索引create index … on…
- 2.3 删除索引 drop index … on 表名
- 3. 查看索引 show indexes in …
- 4. 前缀索引
- 4.1 确定最佳前缀长度:索引的选择性
- 5. 全文索引
- 5.1 创建全文索引 create fulltext index … on…
- 5.2 全文索引的优点
- 5.3 全文搜索的两种模式
- 5.3.1 自然语言模式
- 5.3.2 布尔模式 in boolean mode
- 6. 复合索引
- 6.1 创建复合索引
- 6.2 复合索引中列的顺序
- 6.2.1 基本规则
- 6.2.2 强制使用其他索引进行查询
- 7. 索引无效
- 7.1 重写查询以优化查询
- 7.2 将列单独提出
- 8. 使用索引排序
- 9. 覆盖索引
- 10. 维护索引
- 10.1 重复索引
- 10.2 多余索引
1. 索引介绍
- 索引本质上是数据库引擎用来快速查找数据的数据结构
- 索引能显著提高查询的性能
- 索引内部通常被存储为二进制树
- 在多数情况下,索引很小,足以放进内存,所以使用索引查找数据更快。因为从内存中读取数据总是比从磁盘中读取数据更快。
- 使用索引会带来的问题
- 索引会增加数据库的大小,因为索引必须永久存储在表旁。
- 每次添加、更新或删除记录时,MySQL必须更新对应的索引,这会影响正常操作的性能。
- 因此,应为性能关键的查询保留索引。
- 不应基于表来创建索引,而是基于查询创建索引。因为使用索引的目的是为了加快运行较慢的查询。
2. 创建索引 create index…on…
2.1 explain
-
查看MySQL是如何执行语句的:explain
- type类型:all,全表扫描,读取表中的每一条记录
- rows行数: 扫描的记录条数
use sql_store; explain select customer_id from customers where sql_store.customers.state = 'CA'
2.2 创建索引create index … on…
-
命名:idx_列名
create index idx_state on customers(state); -
创建索引后执行explain:

- type:ref,没有再做全表扫描;
- rows:行数从1010变为112;
- possible_keys:可能的键。表中可能会存在多个索引,MySQL为执行这个查询可能会考虑到的索引,MySQL最终挑选性能最佳的索引执行。
- key:实际使用的索引或键。
-
练习:查询积分大于1000的顾客
-
没有创建索引时:type为all,row为1010
explain select customer_id from customers where points > 1000;
-
为points列创建索引:type为range,rows为529
create index idx_points on customers(points);explain select customer_idfrom customerswhere points > 1000;
-
2.3 删除索引 drop index … on 表名
drop index idx_state on customers;
3. 查看索引 show indexes in …
show indexes in customers;

-
key_name:索引 / 键名
- 聚集索引:每张表最多有1个聚集索引。 在表中添加主键, MySQL会自动创建一个索引,可以快速查找记录。
- 二级索引:创建二级索引时,MySQL会自动将对应的id或主键也纳入二级索引中。例如,积分列上有一个二级索引,但在此索引中,每条记录里都有两个值,为每个顾客的积分和id。
-
collation:排序方式,A为升序,D为降序。
-
cardinality:基数。
-
表示索引中唯一值的估计数量。此数值是估量,不是真实值。
-
analyze table 表名:生成关于此表的统计信息;执行后再执行查看索引语句即可获取真实值。
analyze table customers;
-
-
index_type:索引类型
- btree:二进制树
-
为两张表创建一组关系时,MySQL会自动为外键创建索引,这样就可以快速连接表。
-
查看orders表的索引,发现外键都有二级索引。
show indexes in orders;
-
4. 前缀索引
-
使用前缀索引的原因:
- 为字符串列创建索引,如char、varchar、text、blob,索引会占用大量空间,无法达到较好的性能。索引越小越好,可以存在内存中使搜索更快。
- 索引字符串列时,不想在索引中包含整个列,只想包含列的前几个字符或列前缀,这样能使索引更小。
-
创建前缀索引:
- 在创建索引语句中的列名后的括号中输入数字以指定索引包含此列的字符数
create index idx_lastname on customers(last_name(20))- char、varchar可不指定括号中的数字;
- text、blob必须指定括号中的字符数
4.1 确定最佳前缀长度:索引的选择性
-
索引的选择性指不重复的索引值与数据总量的比值
select count(*) from customers; selectcount(distinct left(last_name, 1))/count(*) as selectivity1,count(distinct left(last_name, 5))/count(*) as selectivity5,count(distinct left(last_name, 10))/count(*)as selectivity10 from customers;
截取前5个字符时由95.6%的数据不同,可以选择前5个字符为前缀创建前缀索引。 -
索引的选择性在80%以上适合建立,否则不建议建立索引,例如性别等。
5. 全文索引
- 情景:搜索博客文章。
- 随着文章数量越来越多,查询会越来越慢。
- 用like查询,只会返回完全按照单词顺序排列的关键词的文章
use sql_blog; select * from posts where title like '%react redux%' orbody like '%react redux%'; - 全文索引
- 包括整个字符串列,而不只是存储前缀
- 会忽略任何停止词,如in、on、the等
5.1 创建全文索引 create fulltext index … on…
use sql_blog;
create fulltext index idx_title_body on posts(title, body);select *
from posts
where match(title, body) against('react redux');

- 查询时,两个内置函数支持全文索引
- match()函数,要搜索的列
- against()函数,要搜索的关键词
5.2 全文索引的优点
- 相关性得分。MySQL会基于若干因素,为包含了要搜索的词的每一行计算相关性得分。
- 相关性得分:介于0到1的浮点数,0表示没有相关性。
- 计算相关性得分:在select中写上mathc…against…计算相关性得分。查询结果按照相关性得分降序排序。
select *,match(title, body) against('react redux') as score from posts where match(title, body) against('react redux');
5.3 全文搜索的两种模式
5.3.1 自然语言模式
-
默认情况的模式。只包含react、只包含redux、包含react和redux,以上三种情况。
select *,match(title, body) against('react redux') as score from posts where match(title, body) against('react redux');
5.3.2 布尔模式 in boolean mode
-
可以包括或排除某些单词
-
against(‘text1 -text2 -text3’ in boolean mode)
- 负号:-text1, 不包括text1
- 正号:+text1,必须包括text1
- 双引号:“xuwuuu is a student”,必须包括引号中的短语
-
例如:
-
负号:包括react,不包含redux的行
select * from posts where match(title, body) against('react -redux' in boolean mode);
-
正号:包括react,不包含redux,每一行必须有form
select * from posts where match(title, body) against('react -redux +form' in boolean mode);
-
6. 复合索引
-
场景:搜索位于加州且积分大于1000的顾客
use sql_store; show indexes in customers; explain select customer_id from customers where state = 'CA' and points > 1000;
- 先把搜索范围缩小到位于加州的顾客。按照state索引进行搜索,找到位于‘CA’的所有数据。
- 然后扫描所有位于加州的顾客,并查看积分。此时的查询需要表扫描,因为state索引中没有顾客的积分。但如果加州有1000万顾客,查询还是会很慢。
6.1 创建复合索引
-
允许对多列建立索引,可优化查询。
-
可以在state列和points列上创建复合索引,可以快速找到位于任何州、拥有任意积分的数据
use sql_store; create index idx_state_points on customers(state, points); explain select customer_id from customers where state = 'CA' and points > 1000;
此时的查询需要扫描58行,之前需要扫描112行。可能的键:有3个,state上、points上、state和points上的复合索引,复合索引在优化查询上更好,因此最后选择了复合索引进行查询
-
一个索引中最多可包含16列,一般在4-6列能达到很好的性能,但最终应根据实际查询和数据量进行确定。
6.2 复合索引中列的顺序
6.2.1 基本规则
- 应该对列进行排序,让更频繁使用的列排在最前面。
- 如有5个查询,大多数或全部的查询都按state查找顾客,把state放在最前面就很合理,这有助于缩小搜索范围
- 把基数更高的列排在最前面
- 基数表示索引中唯一值的数量
- 基数更高的列排在前面能把搜索范围缩小到更少的数量
- 只是基本规则,而不是硬性规则。还应充分考虑实际的查询和数据。
6.2.2 强制使用其他索引进行查询
-
在from和where中间使用use index(索引名称)
explain select customer_id from customers use index(idx_lastname_state) where state = 'NY' and last_name like 'A%';
7. 索引无效
有些情况下,即使有索引,但仍会遇到性能问题
-
用 or 进行条件查询:
- type类型为index,是全索引扫描。
- 全索引扫描比表扫描快,因为它不涉及从磁盘读取每个记录
- rows为1010。但还是需要扫描1010条记录。
explain select customer_id from customers where state = 'CA' or points > 1000;
7.1 重写查询以优化查询
- 优化上述查询:
-
重写查询,以尽可能最好的方式利用索引。把查询拆分成两段更小的查询。
-
选择所有位于加州的顾客,和另一个选择了超过1000积分的数据进行联合查询。
-
但第二段points查询,在idx_state_points索引上位于第二列,查询效率也不高。因此要在points列上创建单独的索引。
-
两端查询rows为112+529,比1010少了很多。
create index idx_points on customers(points); explainselect customer_id from customerswhere state = 'CA'unionselect customer_id from customerswhere points > 1000;
-
7.2 将列单独提出
-
想要利用索引,需要单独把列提出来
- 以下两段查询使用的索引不同
- 第一段使用的是index全索引扫描;第二段是range范围扫描。
explain select customer_id from customers where points - 10 > 2010;explain select customer_id from customers where points > 2000;

8. 使用索引排序
-
例子,按顾客所在的州对其进行排序
-- 按使用了索引的列进行排序 explain select customer_id from customers order by state;-- 按没有使用索引的列进行排序 explain select customer_id from customersorder by first_name;结果:第一个type是index,按照state在前的索引进行排序。第二个type为all,进行全表扫描,使用外部排序。


-
基本规则
- order by子句中的列的顺序,应该与索引中列的顺序相同
- 基于两列的复合索引,如A列和B列,可以按A排序、按A和B排序、按A降序和B降序排序。但不能改变顺序,也不能在A和B中间添加一列
9. 覆盖索引
- 覆盖索引:一个包含所有满足查询所需要的数据的索引。通过此索引,MySQL可以在不读取表的情况下就执行查询。
- 先查看where子句,看最常用的列,将其包含在索引中;
- 看order by子句中的列,看是否在索引中能包含这些列;
- 最后看select子句中使用的列,如果也包含了这些列,就会得到一个覆盖索引。
- 得到覆盖索引后,MySQL就可以用索引满足查询。
- 例子:当选择 * 时,使用的是全表扫描
- 在state_points上的复合索引包含了3列,id列、state列和points列。MySQL会自动把主键包括在二级索引中。
explain select * from customersorder by state;
10. 维护索引
- 在创建新索引之前检查现有索引,避免创建重复索引和多余索引。
- 确保删除重复索引、多余索引和未使用的索引。
10.1 重复索引
- 同一组的列且顺序一致的索引,如ABC和ABC
10.2 多余索引
- 在A和B两列上有一个复合索引,再在A上创建另外一个索引,这就会被判定为多余索引。因为原来的索引也可以优化包含列A的查询。
- 在A和B两列上有复合索引的情况下,创建B和A的复合索引或单独创建B的索引是可以的。