目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、性能压测–常用指标
1)并发用户数
指同一时间点对系统进行操作的用户数。准确说为"同时向服务器发送服务请求,给服务器产生压力的用户数量"
并发用户数和注册用户数、在线用户数的概念不同:
注册用户数一般指的是数据库中存在的用户数,在线用户数只是 ”挂” 在系统上,不一定对服务器不产生压力,而并发用户数一定会对服务器产生压力的。
2)每秒事务数(TPS)/每秒查询率(QPS)
TPS(Transactions Per Second):每秒事务事,单位时间内处理的事务数量,它表示系统的处理能力,这个值越大,说明处理能力越强。
事务是一个或者多个操作的集合,可以一个接口、多个接口、一个业务、多个业务等等。
QPS(Queries Per Second):每秒查询率,是一台服务器每秒能够响应的查询次数(数据库中的每秒执行查询sql的次数)
区别:
TPS:Transactions Per Second,意思是每秒事务数,一个事务可以包含一个操作,也可以包含多个操作。具体事务的定义,可以一个接口、多个接口、一个业务或者多个业务(业务流程)等等。
QPS:Queries Per Second,意思是每秒查询率,是一台服务器每秒能够响应的查询次数(数据库中的每秒执行查询sql的次数),显然,这个不够全面,不能描述增删改,所以,不建议用qps来作为系统性能指标。
关系:
如果是对一个查询接口(单场景)压测,且这个接口内部不会再去请求其它接口,那么tps=qps,否则,tps≠qps
如果是容量场景,假设n个接口都是查询接口,且这个接口内部不会再去请求其它接口,qps=n*tps
建议:
QPS是Query Per Second,是数据库中的概念,每秒执行条数(查询),被引申到压测中来了,但是不包括插入、更新、删除操作,所以不建议用qps来描述系统整体的性能;
3)响应时间(RT)
指客户端发起服务请求到服务器处理完服务请求并返回结果给客户端的时间。
另: 吞吐量(Throughput)含义
指的是单位时间内处理的客户端请求数量。
从业务角度来看,吞吐量指每秒事务数。单位:“Requests/Second”
从网络角度来看,吞吐量指每秒字节数,用来衡量网络的流量。单位:“Bytes/Second”
2、性能压测–指标评估
1)背景
做性能测试之前,最好先定义清楚性能指标。这样我们才能评估测试结果是否满足预期。最理想的情况是,
开发、产品、项目经理已经提前定义好性能指标。但是理想和现实的差距非常大。
2)获取性能指标
如果用户有明确的性能指标,直接使用即可;如果没有,首先要进行需求分析,以获取满足要求的
性能指标,如通过业务调研、日志信息等获取系统最大在线用户数、业务分布、业务高峰时间段、业务高峰期业务量等
3)性能指标计算/统计方式
性能测试范围:通过业务分布来确定性能测试的范围
并发用户数评估:
经典公式
一般来说,利用以下经验公式进行估算系统的平均并发用户数和峰值数据
平均并发用户数的计算:C=n*L/T
并发用户数峰值计算:C^=C+3*根号C
n:平均每天访问用户数
L:用户平均每天的访问时长
T:被考察的时间长度,可以理解为一天内有多长时间有用户访问系统
举例:
假设系统A,该系统有5000个用户,平均每天大概600个用户要访问该系统(可以从系统日志从获得),对于一个典型用户来说,一天之内用户从登陆到退出的平均时间为0.2小时,而在一天之内,用户只有在8小时之内会使用该系统。
计算:
平均并发用户数为:C = 6000.2/8 = 15
并发用户数峰值为:C^ = 15 + 3根号15 = 27
通用公式
对绝大多数场景,我们用(用户总量/统计时间)*影响因子(一般为3)来进行估算并发量。
比如,以乘坐地铁为例子,每天乘坐人数为5万人次,每天早高峰是7到9点,晚高峰是6到7点,
根据二八法则,80%的乘客会在高峰期间乘坐地铁,则每秒到达地铁检票口的人数为:50000*80%/(3*60*60)=3.7
约4人/S,考虑到安检,入口关闭等因素,实际堆积在检票口的人数肯定比这个要大,假定每个人需要3秒才能进站,那实际并发应为4人/s*3s=12,当然影响因子可以根据实际情况增大!
根据系统在线用户数计算:
并发用户数 = 实际系统最大在线用户数的8%到12%
在进行并发用户数评估的时候,不仅要满足当前的性能需求,还要满足未来2~3年不断增长的业务量和用户量的需求。所以评估时候要考虑未来几年的业务增长率。
4)根据TPS估计
公式为 C = TPS*( RT+Think time)
TPS(每秒事务数):通过某时间段业务量的峰值来确定TPS(峰值才能真实反映服务器的最大处理能力),
TPS=脚本运行期间总的事务数/脚本运行时长 如果使用集合点策略,在脚本执行前的等待时间过程中,服务器没有处理事务,那么这个时候的TPS和理想中的结果不一致,比理想中的小。
中间可能会用到二八法则:指80%的业务量在20%的时间里完成。
TPS预估方法:进行业务调研,统计出业务分布(业务占比)、每个业务的高峰期以及每个业务在高峰期的业务量。也可以统计出总的业务量,然后根据业务分布及占比得出每种业务的业务量。
注意:
业务量评估要考虑未来2 ~ 3年的业务增长,以满足未来的性能要求。之所以2~3年是因为我们不会几个月做一次性能测试,也不会做完性能测试之后就再也不做性能测试。
TPS计算,使用二八法则更准确。
例:以目前生产核心系统交易量峰值680万笔/天为基数,每年20%的业务增长,柜面业务占比25%,上收业务占比柜面业务的40%
计算前端系统三年后业务量为680万*(1+20%)(1+20%)(1+20%)*25%*40%=117.5万笔/天。
以系统未来预期日交易量117.5万笔/天为测试目标,用常规性能测试TPS估算方法计算,峰值交易TPS为80%的交易量在20%的时间内产生,以系统交易时间12小时计算,测试目标TPS为:(117.5万0.8)/(120.2*3600秒) =109笔/秒。
结论:
限制TPS的原因:服务器本身性能、代码结构、客户端施加的压力以及网卡等。
利用并发用户数、期望响应时间,可以计算出TPS的期望值。TPS = 并发用户数/(RT+Think Time),实际TPS和响应时间都是单独计算出来的,两者不是互相计算出来的。虽然在宏观上是反比的关系,但是两者之间没有直接关系。
系统TPS会受到并发用户数的影响,刚开始会随着并发用户数的增加而逐渐增加,当系统进入繁忙期后,TPS会有所下降。利用TPS与并发用户数图,可以分析性能瓶颈。
举例说明:
当并发数增加到10的时候,响应时间始终都是1,TPS还在继续增加,说明并发不够,需要增加并发数以达到TPS的峰值。
如果继续增加并发用户数到20,而响应时间还是1,再增加并发用户数,响应时间小于1,说明TPS达到了峰值20。
继续增加并发用户数到100,则造成了线程等待,引起平均响应时间从1秒变成3秒,TPS也从20下降到9;
响应时间评估
用户感知正常响应时间的标准:
2-5-8原则:
如果响应时间在2s内,用户会觉得系统很快;
如果响应时间在2~5秒之间,用户会觉得系统的响应速度还可以;
如果响应时间在2~8秒之间,用户会觉得系统的响应速度很慢,但还可以勉强接受;
而当超过8秒后仍无法得到响应时,用户会觉得系统糟糕透了,或认为系统已经失去响应;
用户感知特殊响应时间的标准:
普通业务操作响应时间:5秒内;
万级数据量查询响应时间:8秒内;
百万级数据量查询响应时间:10秒内;
千万级别数据量查询响应时间:20秒内;
事务成功率
单位时间内系统可以成功完成多少个定义的事务,在一定程度上反应了系统的处理能力,一般事务成功率要求100%或大于99%
系统资源使用率
CPU使用率:指用户进程与系统进程消耗的CPU百分比,长时间情况下,一般不超过80%;
内存利用率:内存利用率=(1-空闲内存/总内存大小)*100%,内存使用率一般不超过80%;
磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写
IO操作,取数据的时候对应的是是读IO操作,一般使用磁盘用于读写操作所占用的时间百分比度量磁盘
读写性能;如:Linux命令:iostat -d -x # -d 显示磁盘使用情况,-x 显示详细信息
%util: 一秒中有百分之多少的时间用于 I/O
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷
网络带宽:一般使用计数器Bytes Total/sec来度量,其表示为发送和接收字节的速率,包括帧字符在内;判断网络连
接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较;
3、性能测试通过标准(参考)
性能测试通过标准包括服务端性能、前端性能和用户体验性能,常规通过标准如表所示:
1)通用互联网服务端性能
TPS(每秒事务数)大于期望值;
响应时间小于期望值;
错误率小于0.5%(事务成功率大于99.5%);
CPU使用率小于75%;
JVM内存使用率小于80%;
2)用户感知正常响应时间的标准
2-5-8原则:
如果响应时间在2s内,用户会觉得系统很快;
如果响应时间在2~5秒之间,用户会觉得系统的响应速度还可以;
如果响应时间在5~8秒之间,用户会觉得系统的响应速度很慢,但还可以勉强接受;
而当超过8秒后仍无法得到响应时,用户会觉得系统糟糕透了,或认为系统已经失去响应;
3)用户感知特殊响应时间的标准
普通业务操作响应时间:5秒内;
万级数据量查询响应时间:8秒内;
百万级数据量查询响应时间:10秒内;
千万级别数据量查询响应时间:20秒内;
4)中间件的一些标准
当前正在运行的线程数不能超过设定的最大值;
当前运行的JDBC连接数不能超过设定的最大值;
GC频率不能频繁,特别是FULL GC更不能频繁,FullGC频率大于半小时每次。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
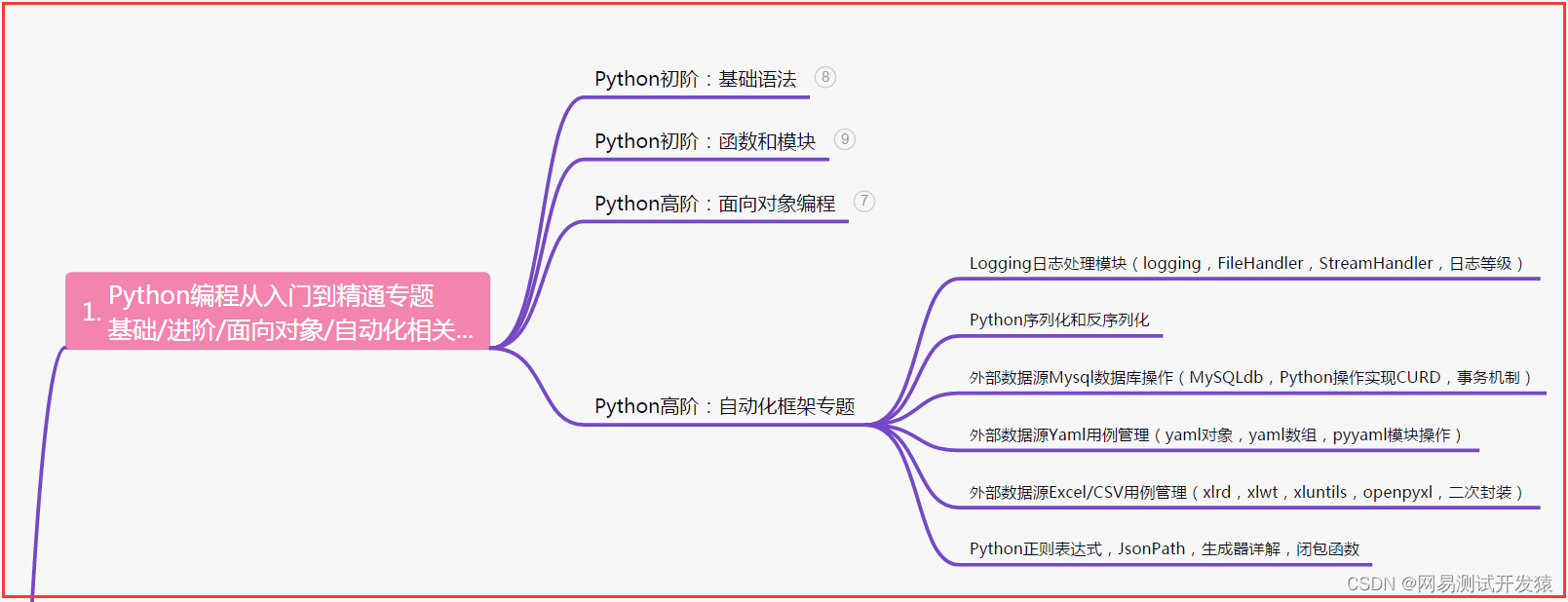
一、Python编程入门到精通
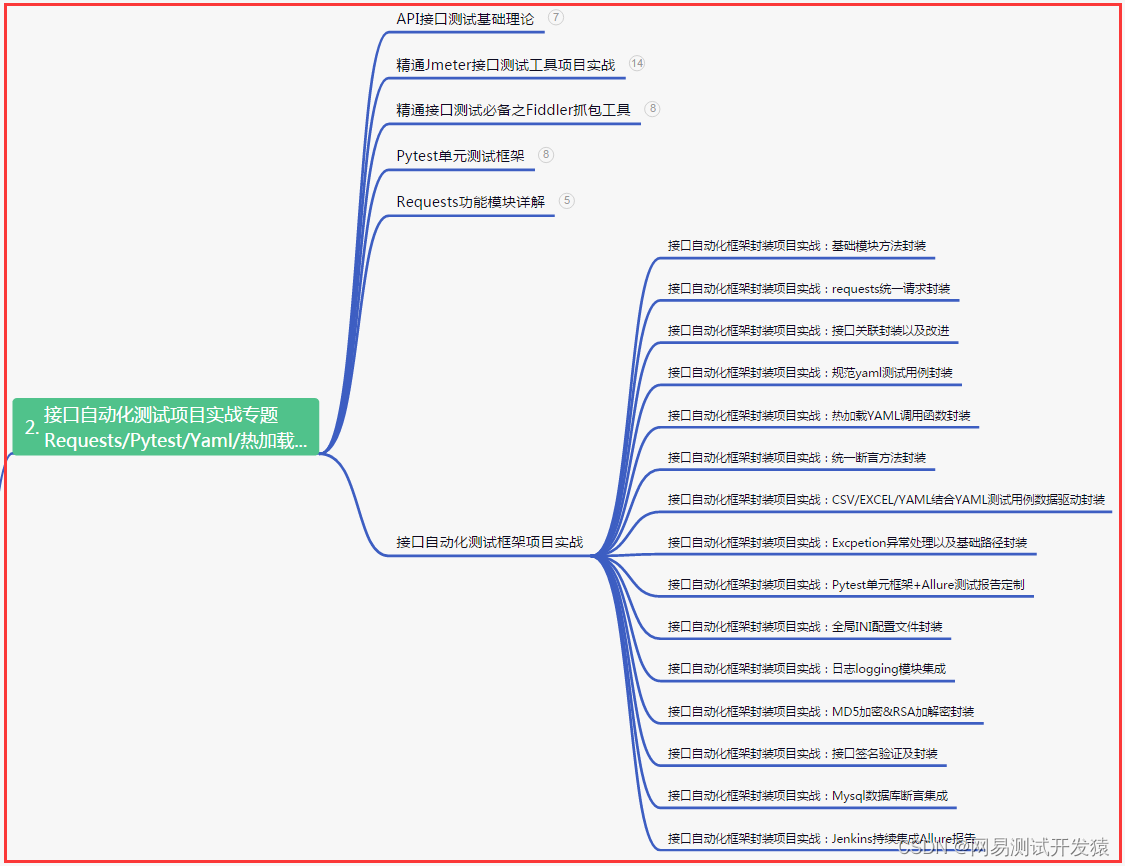
二、接口自动化项目实战
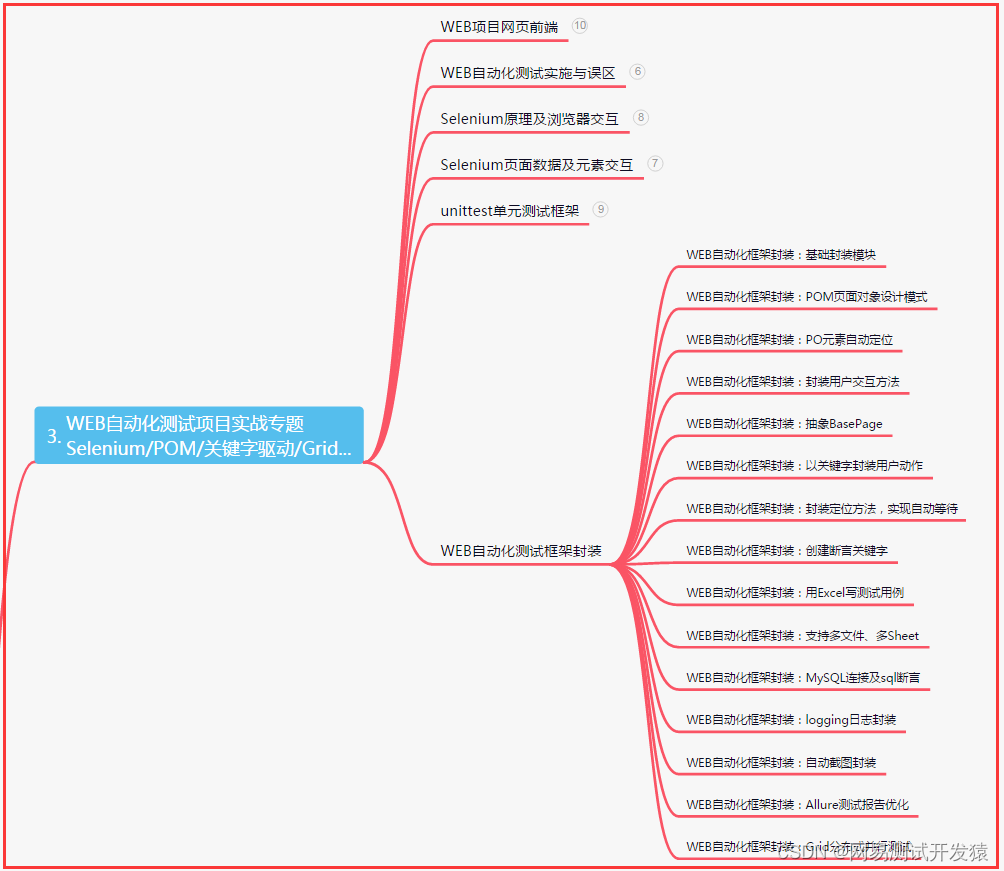
三、Web自动化项目实战
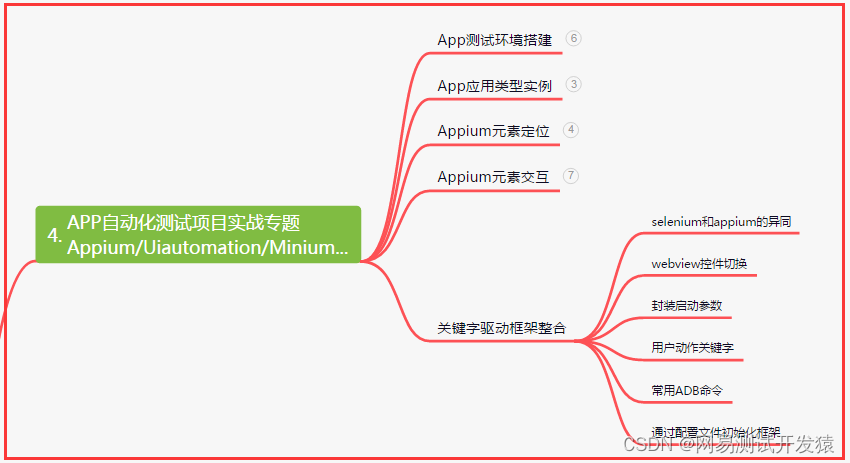
四、App自动化项目实战
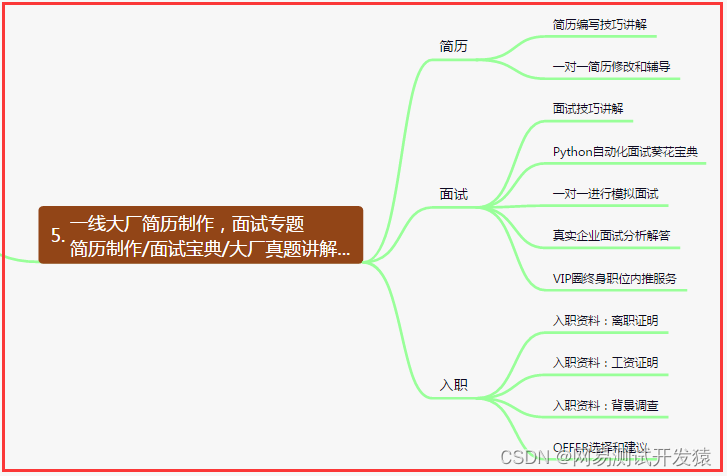
五、一线大厂简历
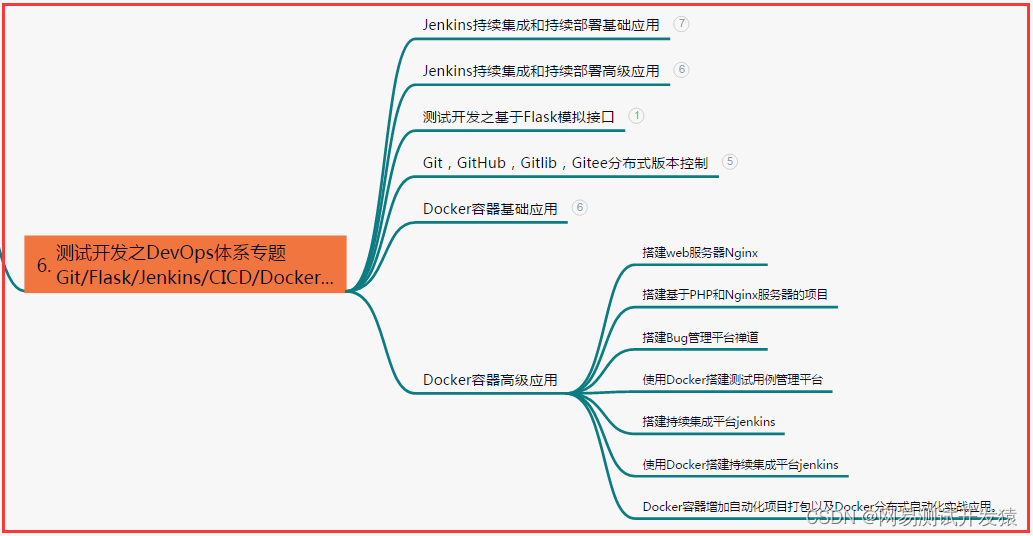
六、测试开发DevOps体系
七、常用自动化测试工具

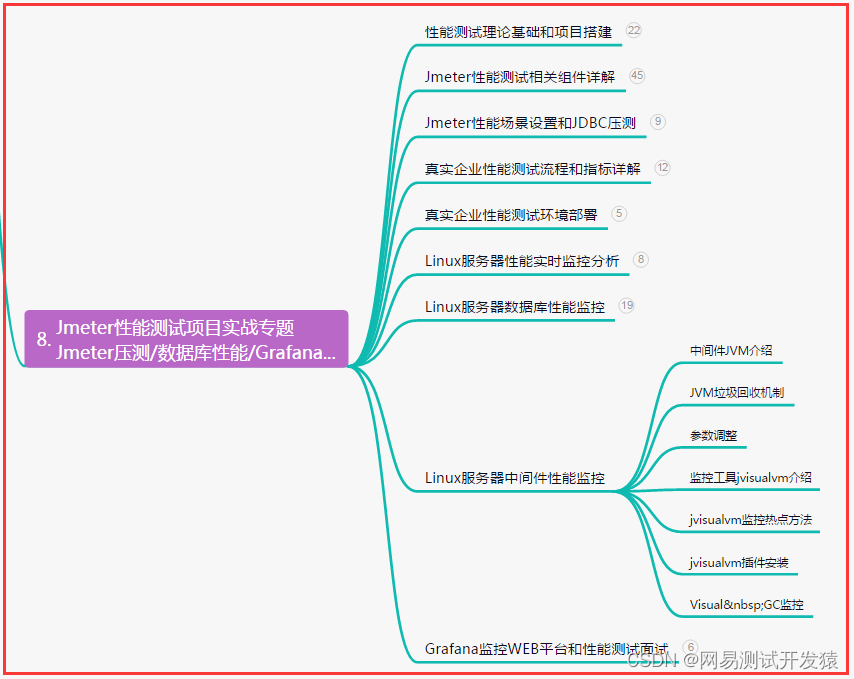
八、JMeter性能测试
九、总结(尾部小惊喜)
不管前路多么曲折,只要心怀梦想,努力奋斗,就能超越自我,迎接属于自己的辉煌时刻。相信自己,勇往直前,你将成就不可思议的壮丽旅程!
在梦想的舞台上,不要畏惧失败与批评,坚持追求卓越。用汗水浇灌希望的种子,用努力编织成功的篇章,你将绽放出绚烂的人生华彩!
勇敢地面对困境与挑战,不放弃,不停歇。奋斗的旅程中或许会有苦涩,但只要坚持努力,你终将品尝到成功的甘甜,迎接辉煌的未来!