前言
感谢关注,可以关注B站同名:语兴呀或公众号语数获取资料。
小文件是数仓侧长期头痛问题,它们会占用过多的存储空间,影响查询性能。因此,我们需要采取一些措施来对小文件进行治理,以保证Hive的高效性和稳定性。在本文中,我将介绍Hive中小文件治理的方法和技巧,希望对大家有所帮助。
背景
小文件是如何产生的:
-
日常任务及动态分区插入数据(使用的Spark2 MapReduce引擎),产生大量的小文件,从而导致Map数量剧增;
-
Reduce数量越多,小文件也越多(Reduce的个数和输出文件是对应的)
-
数据源本身就包含大量的小文件,Api、Kafka等;
-
实时数据落Hive也会产生大量小文件。
小文件问题的影响:
-
从Hive的角度看,小文件会开很多Map,一个Map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能;
-
在HDFS中,每个小文件对象约占150Byte,如果小文件过多会占用大量内存,会直接影响NameNode性能,相对的如果HDFS读写小文件也会更加耗时,因为每次都需要从NameNode获取元信息,并与对应的DataNode建立连接,如果NameNode在宕机中回复,也需要更多的时间从元数据文件中加载;
-
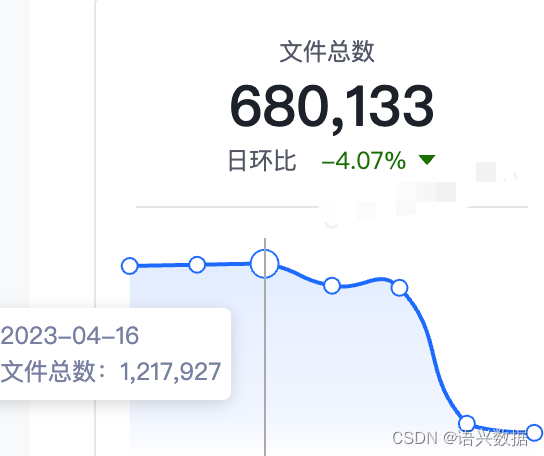
占据HDFS存储,从下图我们得知21号文件平均后存储为280K,合并后为249K。
小文件问题的解决方案
计算引擎使用spark3合并小文件
Spark能够通过AQE特性自动合并较小的分区,对于动态分区写入Spark3.2+引入了Rebalance操作,借助于AQE来平衡分区,进行校分区合并和倾斜分区拆分,避免分区数据过大或过小,能够很好处理小文件问题。
AQE解释:Spark 社区在 DAG Scheduler 中,新增了一个 API 在支持提交单个 Map 阶段,以及在运行时修改 shuffle 分区数等等,而这些就是 AQE,在 Spark 运行时,每当一个 Shuffle、Map 阶段进行完毕,AQE 就会统计这个阶段的信息,并且基于规则进行动态调整并修正还未执行的任务逻辑计算与物理计划(在条件运行的情况下),使得 Spark 程序在接下来的运行过程中得到优化。
减少reduce的数量
计算引擎为Hive,可以使用参数进行控制:
set mapred.reduce.tasks=100; 设置reduce数量, mapper数量:reduce数量 = 10:1)
set mapred.reduce.tasks=100;
insert overwrite table xxx.xxx partition(ds='${lst1date}')
Distribute By Rand()
Distribute by rand()控制分区中数据量,使得Spark SQL的执行计划中多一个Shuffle,用于代码结尾(Distribute by :用来控制Map输出结果的分发,即Map端如何拆分数据给Reduce端。 会根据Distribute by 后边定义的列,根据Reduce的个数进行数据分发,默认是采用hash算法。当 Distribute by 后边跟的列是Rand()时,即保证每个分区的数据量基本一致)
where t0.ds='${lst1date}'
and xxx=xxx
distribute by rand()
在数据传输任务后再做一个清洗任务
本质也是回刷分区合并小文件任务,去处理小文件保障从数据源开始小文件不向下游流去。
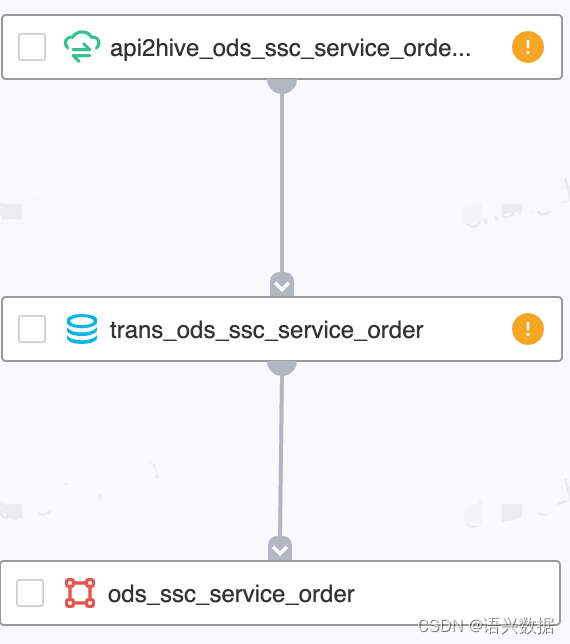
实时任务传输hive后采用每天调度任务来合并小文件
set hive.exec.dynamic.partition.mode=nonstrict;
set spark.sql.hive.convertInsertingPartitionedTable=false;
set spark.sql.optimizer.insertRepartitionBeforeWriteIfNoShuffle.enabled=true;
insert overwrite table xxx.ods_kafka_xxxx partition(ds)
select id,xxx_date,xxx_type,ds
from xxx.ods_kafka_xxxx
where ds='${lst1date}'—-t-1的参数
通过参数方式合并小文件
Hive:
set hive.merge.mapfiles=true; 默认值ture,在Map-only的任务结束时合并小文件。
set hive.merge.mapredfiles=true; 默认值false,在Map-Reduce的任务结束时合并小文件。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; 执行MAP前进行小文件合并
Spark2:
Set spark.sql.finalStage.adaptive.advisoryPartitionSizeInBytes=2048M;
已有的小文件处理
使用spark3进行动态分区刷新代码如下
set hive.exec.dynamic.partition.mode=nonstrict;
set spark.sql.hive.convertInsertingPartitionedTable=false;
set spark.sql.optimizer.insertRepartitionBeforeWriteIfNoShuffle.enabled=true;
insert overwrite table xxx.xxx partition(ds)
select id,xxx_date,xxx_type,ds
from xxx.xxx
where ds<='2023-04-20'
and ds>='2022-04-20'
重建表
这里如果是无分区的表可以考虑直接将表删掉,再重建,使用Spark3跑数据
小文件治理问题点
遇到问题点1:
用spark3+动态分区合并小文件发现一个问题,如果我给分区固定日期 小文件原30个会合并1个,如果用动态分区的话刷完可能部分分区还是30个,后面问了数据平台大佬,大佬说没加spark.sql.optimizer.insertRepartitionBeforeWriteIfNoShuffle.enabled=true ,原理是把inset select from这种简单的没shffule的合并小文件关掉的,动态分区写入和静态分区写入时候创建文件的姿势确实是不一样的
遇到问题点2:
实时数据传入hive小文件居多也需要合并,这里我们可以把历史数据通过spark3+动态分区先回刷 后续建一个每日spark3的调度任务刷t-1的小文件即可
遇到问题点3:
使用Spark3刷小文件时候如果用到Impala同学记住一定要加这个参数,解决Spark3刷新数据后无法同步到Imapla
set spark.sql.hive.convertInsertingPartitionedTable=false;
小文件治理工具化
这里使用网易数帆EasyData中数据治理服务-小文件治理为大家讲解,平台图展示如下:
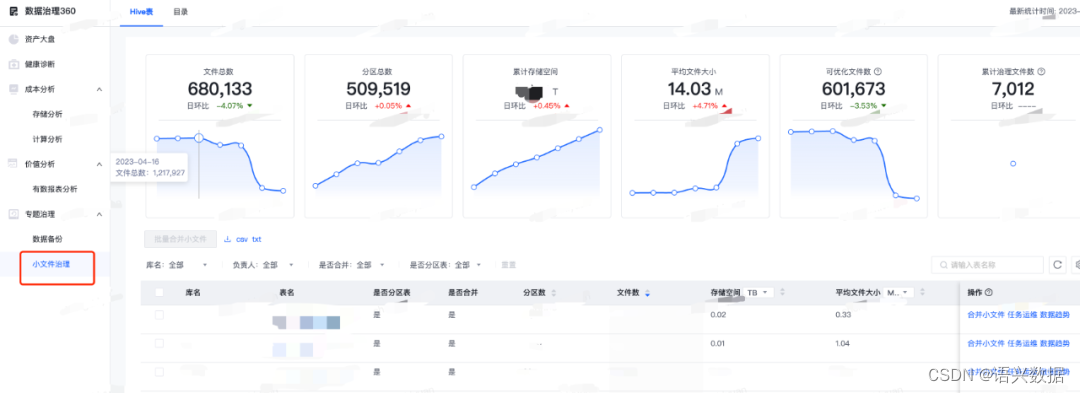
概览下来我们能通过小文件执行趋势和存储量分区量方向判断需要治理数据表有哪些,其次可通过右边操作完成小文件优化。
合并小文件功能
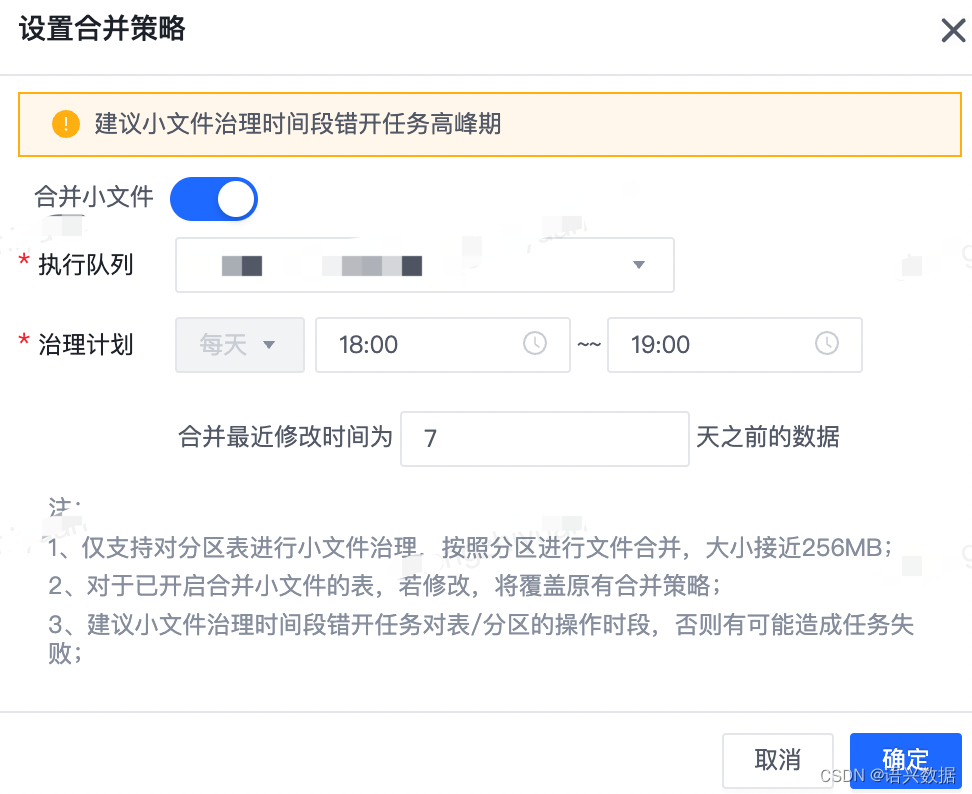
实际是通过用户配置自动化生成计算引擎-spark3调度任务,并每天会调度(这里实现了与凌晨线上任务错峰,避免争抢资源)将数据写入新创建临时表合,再对数据进行校验,如果校验失败则回滚,如校验成功则将数据写入线上数据表中(保障数据质量,避免Bug产生)
-
倒排小文件数后,找到对应的表;
-
通过上述方法在任务中治理;
-
点击操作-小文件,每日扫描去合并小文件(不适合分区多的表例如大于1年以上分区数的表,其次定时清理需要选择中午或晚上休息时间且为线上环境不可与线上任务争夺资源)。
任务运维
等同于日常的离线任务运维,可看合并小文件任务执行情况。
数据趋势
是指任务中文件总数优化趋势,不同于大盘优化趋势展示。
合并任务功能图:
小文件治理效果
优化及下线文件数较高的数据表x张,完成x个实时/离线同步任务小文件处理任务,小文件总数由1,217,927下降至680,133,优化率44.1%