专家系统就是让机器人当某个领域的专家,但这章专家系统不咋考,主要靠书上没有的机器学习。
一、专家系统的基本组成
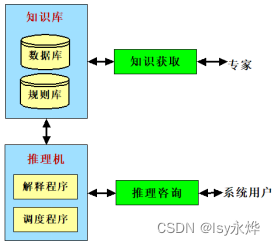

二、专家系统与传统程序的比较
(1)编程思想:
传统程序 = 数据结构 + 算法
专家系统 = 知识 + 推理
(2)知识存储位置:
传统程序:关于问题求解的知识隐含于程序中。
专家系统:知识单独组成知识库,与推理机分离。
(3)处理对象:
传统程序:数值计算和数据处理。
专家系统:符号处理。
(4)解释功能:
传统程序:不具有解释功能。
专家系统:具有解释功能。
(5)正确答案:
传统程序:产生正确的答案。
专家系统:通常产生正确的答案,有时产生错误的答案。
(6)系统的体系结构不同
三、知识获取的过程
抽取知识、知识的转换、知识的输入、知识的检测 。
四、7.4.2 知识获取的模式
非自动知识获取、自动知识获取、半自动知识获取。
五、机器学习
就是让机器不依靠外力,自己学习。
非显著式编程:让计算机自己总结规律的编程方法
举例说明,让机器人冲咖啡,人类规定机器人可以采取一系列行为,规定机器人在特定的环境下做这些行为所带来的收益称为 “ 收益函数 ” 。如:机器人自己摔倒,收益函数为负值;机器人自己摔倒,收益函数为负值;机器人自己取到咖啡,收益函数值为正值。
Tom Mitshell 对机器学习的定义:
一个计算机程序被称为可以学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。
人类在成长、生活过程中积累了很多的历史与经验。人类定期地对这些经验进行“归纳”,获得了生活的“规律”。当人类遇到未知的问题或者需要对未来进行“推测”的时候,人类使用这些“规律”,对未知问题与未来进行“推测”,从而指导自己的生活和工作 。而机器也可以。
机器学习工作流程总结:
1.获取数据
在数据集中一般,一行数据我们称为一个样本,一列数据我们成为一个特征。
所有的机器学习算法在应用场景、优势劣势、对数据要求、运行速度上都各有优劣,但有一点不变的是都是数据贪婪的,也就是说任何一个算法,都可以通过增加数据来达到更好的结果,因此第一步数据采集也是最基础,最重要的一步。
2.数据基本处理
即数据清洗,比如我们通过爬虫得来的数据很杂,甚至很多不是我们需要,然后我们对其进行筛选,这个就类似这个过程。
3.特征工程
把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征
注:业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
4.机器学习
一般认为包括 特征构建、特征提取、特征选择三个部分。
特征构建是指从原始数据中人工的找出一些具有物理意义的特征。
5.构建模型
① 建立训练数据集和测试数据集,通常80%为训练数据集。
② 选择机器学习算法
选择合适的算法对模型进行训练,其中就要求有好的泛化能力(举一反三的能力)。
一般是拟合的模型是好的,但是过拟合就不好,因为要是过拟合肯定是模型比需要的更复杂导致的,不需要这样,这样只会导致变慢,在预测新数据方面的表现也非常糟糕。
6.模型评估
对训练好的模型进行评估。
模型评估主要分为离线评估和在线评估两个阶段。
六、模型评估指标
a. 准确率
就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
(但是准确率只要没到百分百就肯定有问题,例如每次喝水都没事,但是有一次噎住了就g了,人的生命不能重来就是这个意思,老师加这句话我也不理解为什么)
(TP + TN) / (TP + FP +TN+FN)
b.精确率
这是针对预测结果而言的,它表示正确分类的正样本个数占分类器判定为正样本的样本个数的比例。把正类预测为正类(TP),另一种就是把负类预测为正类(FP)。
则 P = TP / ( TP + FP )
c.召回率
是指判定成功的正样本个数占真正的正样本数的比例。
把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
则:R = TP / ( TP + FN )
精确率也称为查准率p,召回率也称为查全率r,查准率和查全率是一对矛盾的度量。一般说查准率高时,查全率往往偏低,而查全率高时,查准率往往偏低。(因为计算能力终究是有极限的,你查的越准,那查的就不一定越全,但是未来肯定就不一样了)
计算:

true这列表示正例或者负例,hyp这列表示阈值0.5的情况下,概率是否大于0.5。
根据这个表格我们可以计算:TP=6(实际上有多少正类就是True),FN=0(相当于正类都预测对了,毕竟按0.5算,正类甚至到了8个之多),FP=2(有两个负类被预测成正类),TN=2(预测结果中有几个反例,这个用不到,我们应该一般不算准确率)。
所以
召回率recall = 6/(6+0)=1
精确率precison = 6/(6+2)=0.75
准确率 =(6+2)/(6+0+2+2)= 0.8
下面的在PR曲线里面用到:
那么得出PR曲线坐标(1,0.75)。
同理得到不同阈下的坐标,即可绘制出曲线。
七、PR曲线(本章重点)
(1)用于研究评估分类模型在不同阈值下的精确率(注意不是准确率)和召回率之间的权衡关系。
(2)在PR曲线中,横轴表示召回率,纵轴表示精确率。
(3)绘制PR曲线的方法
1.在测试集上使用分类模型进行预测,并得到相应的概率(或决策分数)。
2.使用不同的阈值将概率(或决策分数)将样本转化为正负例,例如将概率大于0.5的样本预测为正例,小于等于0.5的样本预测为负例。
3.根据阈值和模型预测结果,计算精确率和召回率。
4.使用不同的阈值重复步骤3和步骤4,记录不同阈值下的精确率和召回率。
5.绘制PR曲线时,可以使用线图或者散点图。将不同阈值下的精确率和召回率作为点绘制在图上,并将点按照阈值的大小进行连接,得到PR曲线。
6.可以通过计算PR曲线下的面积来评估模型在精确率和召回率之间的整体性能,面积越大,模型的性能越好。
需要注意的是,PR曲线适用于正负样本不平衡的分类问题,并且对于严重偏斜的数据集,PR曲线可能更能反映模型的性能。

优劣对比:
1:曲线越靠近右上方,性能越好。(例如上图黑色曲线)
2:根据曲线下方面积大小判断,面积更大的更优于面积小的。(例如橘蓝曲线,橘色优于蓝色)
3:平衡点F是查准率与查重率相等时的点。F计算公式为F =2*P*R /(P +R),F值越大,性能越好。
八、拟合
考试成绩差的同学,有这三种可能:
一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做;
二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了;
三、完全不做题,考试全靠瞎蒙。
机器学习中,第一类情况称作欠拟合,第二类情况称作过拟合,第三类情况称作不收敛。
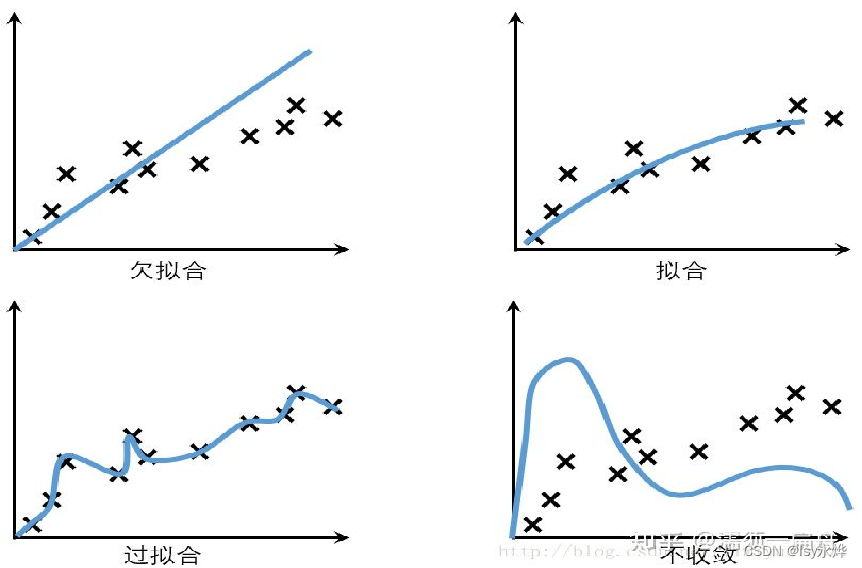
九、机器学习的分类
以下四个机器学习的任务,如何分类?
(1)教计算机下棋;
(2)垃圾邮件识别,教计算机自动识别某个邮件是否是垃圾邮件;
(3)人脸识别,教计算机通过人脸的图像识别这个人是谁;
(4)无人驾驶,教计算机自动驾驶汽车从一个指定地点到另一个指定地点。
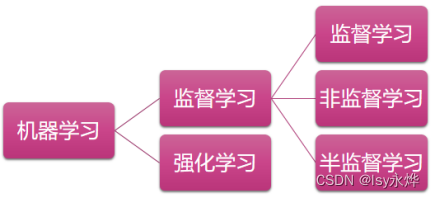
(2)、(3)中的经验E是完全由人搜集起来输入进计算机的,称为监督学习。
(1)、(4)中的经验E是由计算机与环境互动获得的,称为强化学习。
1.按学习方式分:
2.按照学习任务分:
有三种——分类,回归,聚类。
分类是预测一个标签 (是离散的),属于监督学习。
回归是预测一个数量 (是连续的),属于监督学习。
聚类属于无监督学习。
聚类是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息聚类的一种方法。聚类的目的是使得属于同类别的对象之间的差别尽可能的小,而不同类别上的对象的差别尽可能的大。
因此,聚类的意义就在于将观察到的内容组织成类分层结构,把类似的事物组织在一起。
3.分类和回归的区别
1)输出不同
分类问题输出的是物体所属的类别,回归问题输出的是物体的值。
例如,根据天气情况预测明天穿衣服的量以及是否携带雨具做判断。
阴天就是分类,多少度就是回归,但是都可以用来判断明天带不带伞。
(2)目的不同
分类的目的是为了寻找决策边界,即分类算法得到是一个决策面。
回归的目的是为了找到最优拟合,通过回归算法得到是一个最优拟合线,这个线条可以最好的接近数据集中的各个点。
(3)结果不同
分类的结果只有一个,判断属于什么类别。
回归是对真实值的一种逼近预测,值不确定,当预测值与真实值相近时,误差较小时,认为这是一个好的回归。
本质一样,都是要建立映射关系。