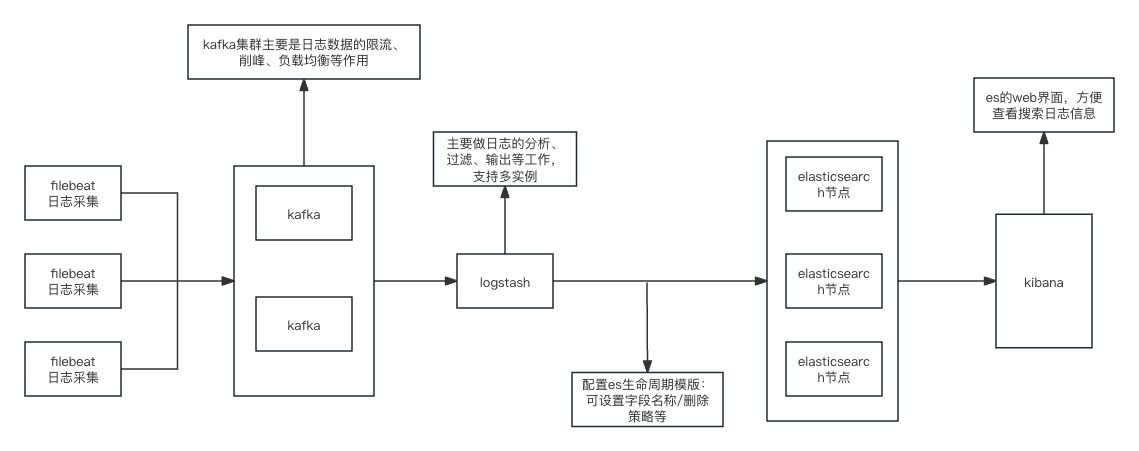
ELK+kafka
<es生命周期可视化配置界面>
一、创建索引模式
根据logstash中的日志规则 匹配对应系统日志

二、创建索引生命周期策略:可以控制生成索引的生命周期
共4个阶段:热阶段——温阶段——冷阶段——删除阶段
阶段1. hot: 索引被频繁写入和查询
阶段2. warm: 索引不再写入,但是仍在查询
阶段3. cold: 索引很久不被更新,同时很少被查询。但现在考虑删除数据还为时过早,仍然有需要这些数据的可能,但是可以接受较慢的查询响应。
阶段4. delete: 索引不再需要,可以删除。

温阶段和冷阶段可选择性增加;
示例:ES生命周期管理 - 知乎
三、创建索引模版:根据模版配置生成对应索引文件

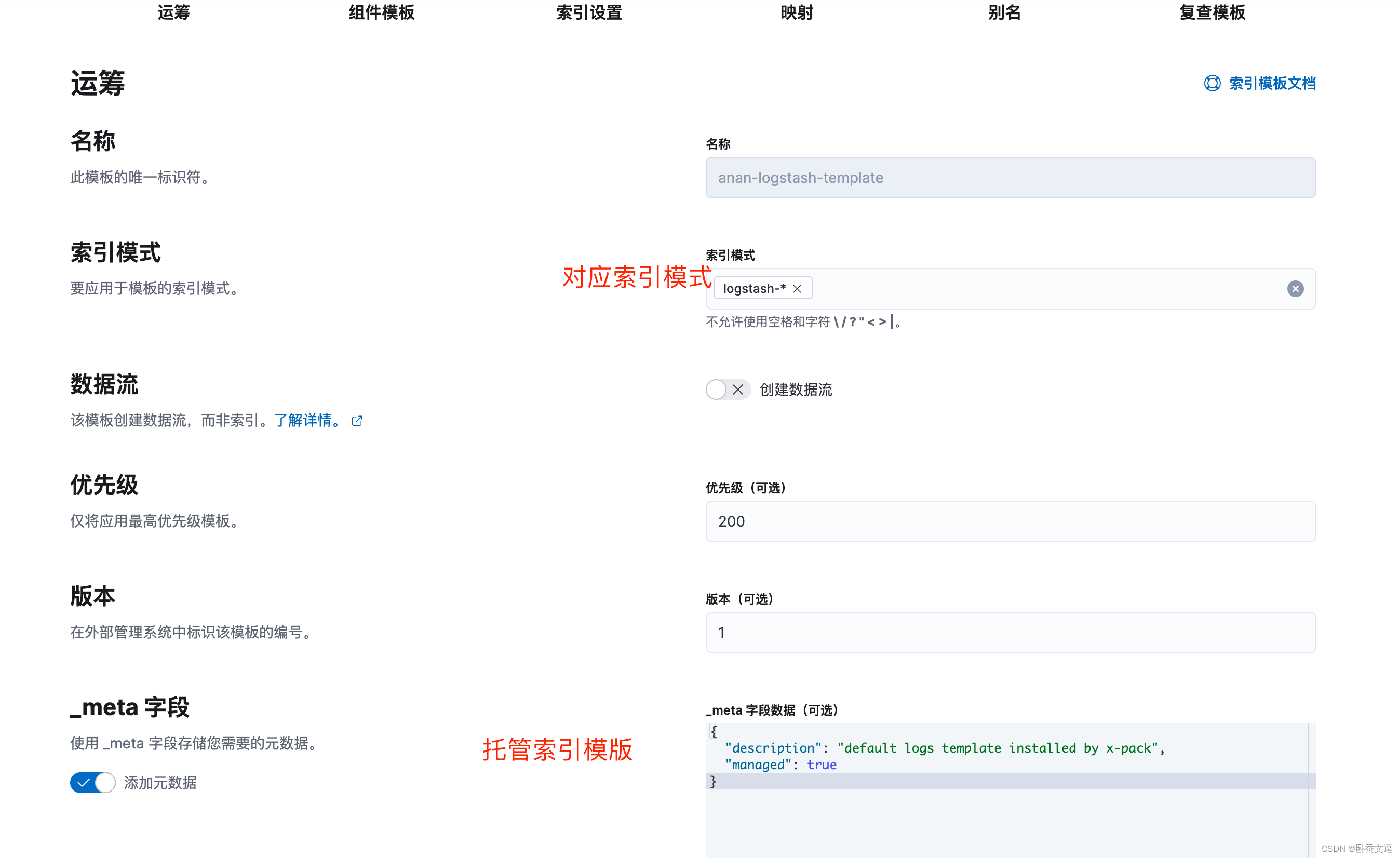
{"description": "default logs template installed by x-pack","managed": true
}
四、配置完成索引模版即可,logstash输出数据时,会检测日志文件名是否符合logstash-*,符合则根据配置的模版生成索引文件。
五、测试
1、按照上述流程配置,模拟生成对应索引,查看是否走对应模版;
# 生成索引
PUT logstash-2023.10.11
# 查询索引
GET logstash-2023.10.112、若不用可视化配置,也可通过脚本在控制台模拟
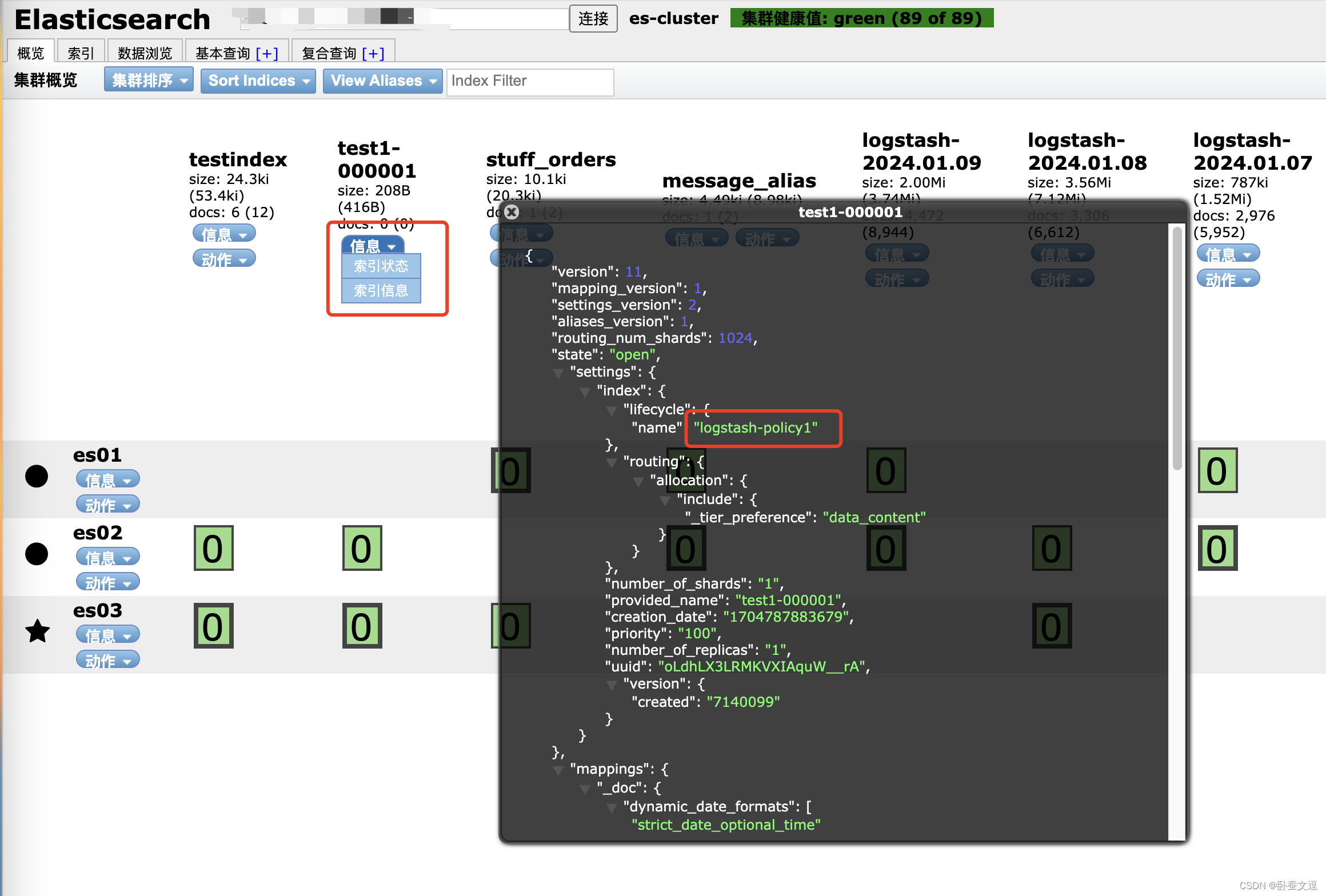
1)生成logstash-policy1 生命周期策略
PUT _ilm/policy/logstash-policy1
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"set_priority": {"priority": 100}}},"delete": {"min_age": "10s","actions": {"delete": {"delete_searchable_snapshot": true}}}}}
}
- policy:这是索引生命周期管理策略的根对象。
- phases:这是一个包含不同阶段的对象。在索引生命周期管理策略中,阶段是指按照特定的时间间隔,例如每个小时或每天,执行特定操作的逻辑单元。
在给定的配置中,有两个阶段:
-
hot:这是索引的活跃阶段。在这个阶段,索引处于活动状态并接受新的数据。
- min_age:这是索引的生命周期开始的时间点。在这里,它设置为"0ms",意味着从创建索引的那一刻开始,该索引就会进入这个阶段。
- actions:这是在该阶段执行的操作列表。
- set_priority:这是一个设置索引优先级为100的操作。优先级是一个数值,用于在执行某些操作时确定哪些索引应该首先处理。较高的优先级意味着在处理相同操作的多个索引时,优先级较高的索引将首先被处理。
-
delete:这是删除索引的阶段。
- min_age:这是索引进入该阶段的时间点。在这里,它设置为"10s",意味着从创建索引开始,10秒后,该索引将进入这个阶段。
- actions:这是在该阶段执行的操作列表。
- delete:这是一个删除索引的操作。此外,还有
delete_searchable_snapshot属性,设置为true,这意味着在删除索引之前,也会删除与该索引关联的可搜索快照。
- delete:这是一个删除索引的操作。此外,还有
简而言之,这个配置定义了一个索引生命周期管理策略,其中新创建的索引首先会被设置为高优先级(100),并在10秒后被删除。
2)生成 logstash_template1 模版
PUT _template/logstash_template1
{"index_patterns": ["test1-*"],"settings": {"index": {"lifecycle": {"name": "logstash-policy1"}}},"mappings": {"dynamic": "true","dynamic_date_formats": ["strict_date_optional_time","yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"],"dynamic_templates": [],"date_detection": true,"numeric_detection": false,"properties": {"env": {"type": "text"},"index_name": {"type": "text"},"ip": {"type": "text"},"message": {"type": "text"}}},"aliases": {}
}-
PUT _template/logstash_template1:PUT是一个HTTP方法,用于创建或更新资源。_template/logstash_template1指定了要创建或更新的资源路径,即索引模板。
-
{: 开始定义JSON对象。 -
"index_patterns": ["test1-*"],:- 定义了该模板可以应用于哪些索引名称模式。在这里,它适用于所有以
test1-开头的索引名称。
- 定义了该模板可以应用于哪些索引名称模式。在这里,它适用于所有以
-
"settings": {: 开始定义设置部分,它定义了模板级别的设置。 -
"index": {: 开始定义索引级别的设置。 -
"lifecycle": {: 开始定义索引的生命周期策略。 -
"name": "logstash-policy1"},: 设置索引生命周期策略的名称为logstash-policy1。 -
},: 结束索引生命周期策略的定义。 -
},: 结束索引级别的设置。 -
},: 结束设置部分的定义。 -
"mappings": {: 开始定义索引的映射,即如何存储和检索数据。 -
"dynamic": "true",: 允许动态映射,即如果字段在文档中不存在,则会自动创建该字段。 -
"dynamic_date_formats": [: 定义动态日期格式。这些格式告诉Elasticsearch如何解析日期字段。 -
"strict_date_optional_time", "yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"],: 定义了两个日期格式,用于解析日期字段。 -
"dynamic_templates": [],: 定义动态模板,用于处理某些类型的字段。这里为空,表示不定义任何动态模板。 -
"date_detection": true,: 启用日期检测,使Elasticsearch能够自动检测日期字段。 -
"numeric_detection": false,: 不启用数字检测,这意味着如果字段是数字,它不会被自动转换为数字类型。 -
"properties": {: 开始定义字段的属性。 -
"env": { "type": "text" },: 定义一个名为env的字段,其类型为文本。 -
"index_name": { "type": "text" },: 定义一个名为index_name的字段,其类型为文本。 -
"ip": { "type": "text" },: 定义一个名为ip的字段,其类型为文本。 -
"message": { "type": "text" }: 定义一个名为message的字段,其类型为文本。 -
},: 结束字段属性的定义。 -
},: 结束映射部分的定义。 -
"aliases": {}: 定义索引别名,这里为空,表示没有别名。 -
}: 结束JSON对象。
3)创建符合模版条件的索引
# 创建索引
PUT test1-000001# 写入数据
PUT /test1-000001/_doc/1
{ "env": "develop", "index_name": "测试", "ip": "127.0.0.1","message": "一个测试","@timestamp" : "2024-01-08T00:03:06.432Z"
}# 查看索引
GET test1-000001# 查看索引内容
GET /test1-000001/_mapping?pretty
GET /test1-000001/_search# 删除索引
DELETE test1-000001可以在ES中查看索引是否走对应模版: