用户创建与授权
-- 创建用户
create user 'test' identified by 'test';
-- 创建数据库
create database test_db;
-- 授权用户
grant all on test_db to test;
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name(column_definition1[, column_definition2, ...][, index_definition1[, index_definition12,]])[ENGINE = [olap|mysql|broker|hive]][key_desc][COMMENT "table comment"];[partition_desc][distribution_desc][rollup_index][PROPERTIES ("key"="value", ...)][BROKER PROPERTIES ("key"="value", ...)];
Doris建表是同步操作,执行完成之后会返回成功或失败。Doris既可以分区也可以分桶。
分区 Partition 用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
分桶 Distribution 用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布
Doris支持的数据类型
基本MySQL支持的数据类型都支持,拓展了一些类型如HLL JSON ARRAY等
doris中数据以表(table)进行存储,一张表包括了行row和列column
在默认的数据模型中,Column 只分为排序列和非排序列。
存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找
聚合模型中,Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
Partition和Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元
Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元
Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行
数据划分
分区与分桶
Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),支持 Hash 和 Random 的划分方式
Partition
- Partition 列可以指定一列或多列,分区列必须为 KEY 列。多列分区的使用方式在后面 多列分区 小结介绍。
- 不论分区列是什么类型,在写分区值时,都需要加双引号。
- 分区数量理论上没有上限。
- 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的 Partition。该 Partition 对用户不可见,并且不可删改。
- 创建分区时不可添加范围重叠的分区
Range 分区
- 分区列通常为时间列,以方便的管理新旧数据。
- Range 分区支持的列类型:[DATE,DATETIME,TINYINT,SMALLINT,INT,BIGINT,LARGEINT]
- Partition 支持通过
VALUES LESS THAN (...)仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。也支持通过VALUES [...)指定上下界,生成一个左闭右开的区间
Range分区示例
CREATE TABLE IF NOT EXISTS example_db.example_range_tbl
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=OLAP
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
("replication_num" = "3","storage_medium" = "SSD","storage_cooldown_time" = "2018-01-01 12:00:00"
);
PARTITION BY RANGE(
date)
(
PARTITIONp201701VALUES LESS THAN (“2017-02-01”),
PARTITIONp201702VALUES LESS THAN (“2017-03-01”),
PARTITIONp201703VALUES LESS THAN (“2017-04-01”)
)指明了分区的范围按date时间分成了3个分区
Range还可以指定上界和下届
上述分区当建表完成后,会自动生成如下3个分区
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)注意此时如果删除了分区会产生空洞,比如删除了p201702此时会导致日期在2017-02-01 ~ 2017-03-01的数据插入导入不进去
分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。通过
VALUES LESS THAN语句增加分区时,分区的下界紧接上一个分区的上界
Range还支持多列分区
List分区
List PartitionCREATE TABLE IF NOT EXISTS example_db.example_list_tbl
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",`city` VARCHAR(20) NOT NULL COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
("replication_num" = "3","storage_medium" = "SSD","storage_cooldown_time" = "2018-01-01 12:00:00"
);
使用 VALUES IN 执行List分区
List分区同样支持多列分区
动态分区
动态分区是0.12加入doris的功能,只支持Range分区,对表级别的分区实现生命周期管理(TTL),减少用户的使用负担
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
动态分区可以在创建时指定,也可以运行时修改。
-- 建表时指定
CREATE TABLE tbl1
(...)
PROPERTIES
("dynamic_partition.prop1" = "value1","dynamic_partition.prop2" = "value2",...
)
-- 运行时修改
ALTER TABLE tbl1 SET
("dynamic_partition.prop1" = "value1","dynamic_partition.prop2" = "value2",...
)
动态分区涉及参数很多,如dynamic_partition.time_unit 分区单位,dynamic_partition.end 结束偏移 dynamic_partition.prefi分区名前缀等,详细参考官方文档
| 属性名 | 描述 |
|---|---|
| dynamic_partition.enable | 是否开启动态分区特性,可指定 true 或 false,默认为 true |
| dynamic_partition.time_unit | 动态分区调度的单位,可指定 HOUR、DAY、WEEK、MONTH。HOUR,后缀格式为 yyyyMMddHH,分区列数据类型不能为 |
| dynamic_partition.time_zone | 动态分区的时区,如果不填写,则默认为当前机器的系统的时区 |
| dynamic_partition.start | 动态分区的起始偏移,为负数。根据 time_unit 属性的不同,以当 |
| dynamic_partition.end | 动态分区的结束偏移,为正数。根据 time_unit 属性的不同,以当 |
| dynamic_partition.prefix | 动态创建的分区名前缀 |
| dynamic_partition.buckets | 动态创建的分区所对应分桶数量 |
| dynamic_partition.replication_num | 动态创建的分区所对应的副本数量,如果不填写,则默认为该表创建时指定的副本数量 |
| dynamic_partition.start_day_of_week | 当 time_unit 为 WEEK 时,该参数用于指定每周的起始点。取值为 1 到 7。其中 1 表示周一,7 表示周日。默认为 1,即表示每周以周一为起始点 |
| dynamic_partition.start_day_of_month | 当 time_unit 为 MONTH 时,该参数用于指定每月的起始日期。取值为 1 到 28。其中 1 表示每月 1 号,28 表示每月 28 号。默认为 1,即表示每月以 1 号位起始点。暂不支持以 29、30、31 号为起始日,以避免因闰年或闰月带来的歧义 |
ENGINE
本示例中,ENGINE 的类型是 olap,即默认的 ENGINE 类型。在 Doris 中,只有这个 ENGINE 类型是由 Doris 负责数据管理和存储的。其他 ENGINE 类型,如 mysql、broker、es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据
数据模型
Aggregate模型
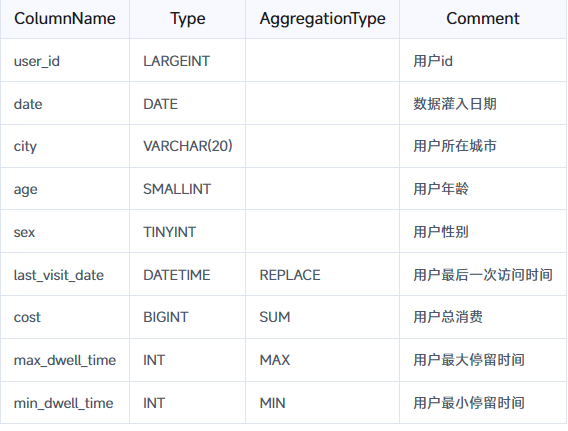
CREATE DATABASE IF NOT EXISTS example_db;CREATE TABLE IF NOT EXISTS example_db.example_tbl_agg1
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age … 等称为 Key,而设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。 AggregationType 目前有以下几种聚合方式和agg_state:
- SUM:求和,多行的 Value 进行累加。
- REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。
- MAX:保留最大值。
- MIN:保留最小值。
- REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于null值,不做替换。
- HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
- BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
-- 插入数据
insert into example_db.example_tbl_agg1 values
(10000,"2017-10-01","北京",20,0,"2017-10-01 06:00:00",20,10,10),
(10000,"2017-10-01","北京",20,0,"2017-10-01 07:00:00",15,2,2),
(10001,"2017-10-01","北京",30,1,"2017-10-01 17:05:45",2,22,22),
(10002,"2017-10-02","上海",20,1,"2017-10-02 12:59:12",200,5,5),
(10003,"2017-10-02","广州",32,0,"2017-10-02 11:20:00",30,11,11),
(10004,"2017-10-01","深圳",35,0,"2017-10-01 10:00:15",100,3,3),
(10004,"2017-10-03","深圳",35,0,"2017-10-03 10:20:22",11,6,6);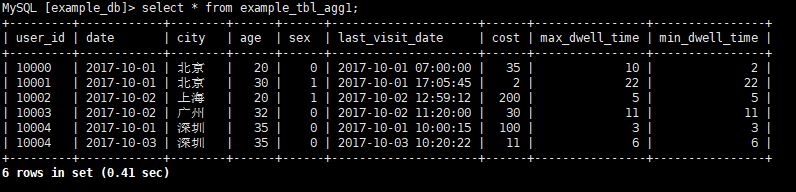
(10000,“2017-10-01”,“北京”,20,0,“2017-10-01 06:00:00”,20,10,10),
(10000,“2017-10-01”,“北京”,20,0,“2017-10-01 07:00:00”,15,2,2),AGGREGATE KEY(
user_id,date,city,age,sex)此时上述两条数据因为所有聚合Key值相同,所有聚合列进行聚合计算变成
10000 | 2017-10-01 | 北京 | 20 | 0 | 2017-10-01 07:00:00 | 35 | 10 | 2
数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。(可参阅聚合模型的局限性一节获得更多详情。)
Aggregate模型还有agg_state 聚合类型,他表示一种中间态,需要调用聚合参数查询才有意义,详细参考官网示例 https://doris.apache.org/zh-CN/docs/data-table/data-model
Unique模型
在某些多维分析场景下,为了保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。 引入了 Unique 数据模型。在1.2版本之前,该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。 由于聚合模型的实现方式是读时合并(merge on read),因此在一些聚合查询上性能不佳(参考后续章节聚合模型的局限性的描述),引入了Unique模型新的实现方式,写时合并(merge on write),通过在写入时做一些额外的工作,实现了最优的查询性能。 写时合并将在未来替换读时合并成为Unique模型的默认实现方式,两者将会短暂的共存一段时间。下面将对两种实现方式分别举例进行说明。
读时合并
此时合并类型为REPLACE

CREATE TABLE IF NOT EXISTS example_db.example_tbl_unique
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`phone` LARGEINT COMMENT "用户电话",`address` VARCHAR(500) COMMENT "用户地址",`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
-- 因为没有使用聚合列 完全等同于如下建表
CREATE TABLE IF NOT EXISTS example_db.example_tbl_agg3
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",`age` SMALLINT REPLACE COMMENT "用户年龄",`sex` TINYINT REPLACE COMMENT "用户性别",`phone` LARGEINT REPLACE COMMENT "用户电话",`address` VARCHAR(500) REPLACE COMMENT "用户地址",`register_time` DATETIME REPLACE COMMENT "用户注册时间"
)
AGGREGATE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);-- 插入数据
INSERT INTO example_db.example_tbl_unique VALUES (1,'jim','cq33',16,1,13522441231,'cqfl','2017-01-01 12:12:12')
-- 再插入一条 此时因为aggerateType为Replace 该SQL执行之后查询也只会有id=1 name=jim的一条数据
INSERT INTO example_db.example_tbl_unique VALUES (1,'jim','sh',23,1,1352334123144,'shshshsh','2020-01-01 12:12:12')写时合并
在 1.2.0 版本中,作为一个新的feature,写时合并默认关闭,用户可以通过添加下面的property来开启
“enable_unique_key_merge_on_write” = “true”
注意:
- 建议使用1.2.4及以上版本,该版本修复了一些bug和稳定性问题
- 在be.conf中添加配置项:disable_storage_page_cache=false。不添加该配置项可能会对数据导入性能产生较大影响
-- 语法与读时合并一致,只是多了一个properties
CREATE TABLE IF NOT EXISTS example_db.example_tbl_unique_merge_on_write
(`user_id` LARGEINT NOT NULL COMMENT "用户id",`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`phone` LARGEINT COMMENT "用户电话",`address` VARCHAR(500) COMMENT "用户地址",`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);-- 插入数据
INSERT INTO example_db.example_tbl_unique_merge_on_write VALUES (1,'jim','cq33',16,1,13522441231,'cqfl','2017-01-01 12:12:12')
-- 再插入数据 此时再次插入因为AggregationType为NONE 会发现数据没有任何变化
INSERT INTO example_db.example_tbl_unique VALUES (1,'jim','sh',23,1,1352334123144,'shshshsh','2020-01-01 12:12:12')
此时合并类型为NONE
在开启了写时合并选项的Unique表上,数据在导入阶段就会去将被覆盖和被更新的数据进行标记删除,同时将新的数据写入新的文件。在查询的时候, 所有被标记删除的数据都会在文件级别被过滤掉,读取出来的数据就都是最新的数据,消除掉了读时合并中的数据聚合过程,并且能够在很多情况下支持多种谓词的下推。因此在许多场景都能带来比较大的性能提升,尤其是在有聚合查询的情况下。
【注意】
- 新的Merge-on-write实现默认关闭,且只能在建表时通过指定property的方式打开。
- 旧的Merge-on-read的实现无法无缝升级到新版本的实现(数据组织方式完全不同),如果需要改为使用写时合并的实现版本,需要手动执行
insert into unique-mow-table select * from source table.- 在Unique模型上独有的delete sign 和 sequence col,在写时合并的新版实现中仍可以正常使用,用法没有变化。
Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求
CREATE TABLE IF NOT EXISTS example_db.example_tbl_duplicate
(`timestamp` DATETIME NOT NULL COMMENT "日志时间",`type` INT NOT NULL COMMENT "日志类型",`error_code` INT COMMENT "错误码",`error_msg` VARCHAR(1024) COMMENT "错误详细信息",`op_id` BIGINT COMMENT "负责人id",`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`, `error_code`)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
-- 此时DUPLICATE KEY作为排序列
这种数据模型区别于 Aggregate 和 Unique 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序
2.0之后doris支持无排序列的Duplicate模型
当创建表的时候没有指定Unique、Aggregate或Duplicate时,会默认创建一个Duplicate模型的表,并自动指定排序列
当用户并没有排序需求的时候,可以通过在表属性中配置 “enable_duplicate_without_keys_by_default” = “true” 然后再创建默认模型的时候,就会不再指定排序列,也不会给该表创建前缀索引,以此减少在导入和存储上额外的开销
CREATE TABLE IF NOT EXISTS example_db.example_tbl_duplicate_without_keys_by_default
(`timestamp` DATETIME NOT NULL COMMENT "日志时间",`type` INT NOT NULL COMMENT "日志类型",`error_code` INT COMMENT "错误码",`error_msg` VARCHAR(1024) COMMENT "错误详细信息",`op_id` BIGINT COMMENT "负责人id",`op_time` DATETIME COMMENT "处理时间"
)
DISTRIBUTED BY HASH(`type`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_duplicate_without_keys_by_default" = "true"
);
聚合模型的局限性
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性
Doris在使用如count(*)的时候,*Doris 必须扫描所有的 AGGREGATE KEY 列,并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count() 查询需要扫描大量的数据
因此,当业务上有频繁的 count查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count
则
select count(*) from table;的结果等价于select sum(count) from table;。 而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同地行。 否则,select sum(count) from table;只能表述原始导入的行数,而不是select count(*) from table;的语义
Unique模型写时合并写时合并为每次导入的rowset增加了对应的delete bitmap,count(*) 查询在Unique模型的写时合并实现上的性能,相比聚合模型有10倍以上的提升
Key列
Duplicate、Aggregate、Unique 模型,都会在建表指定 key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的key列, 可以认为只是 “排序列”,并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,key 列是兼顾 “排序列” 和 “唯一标识列”,是真正意义上的“ key 列
数据模型选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
- Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用自1.2版本加入的写时合并实现。
- Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
- 如果有部分列更新的需求,请查阅文档部分列更新获取相关使用建议