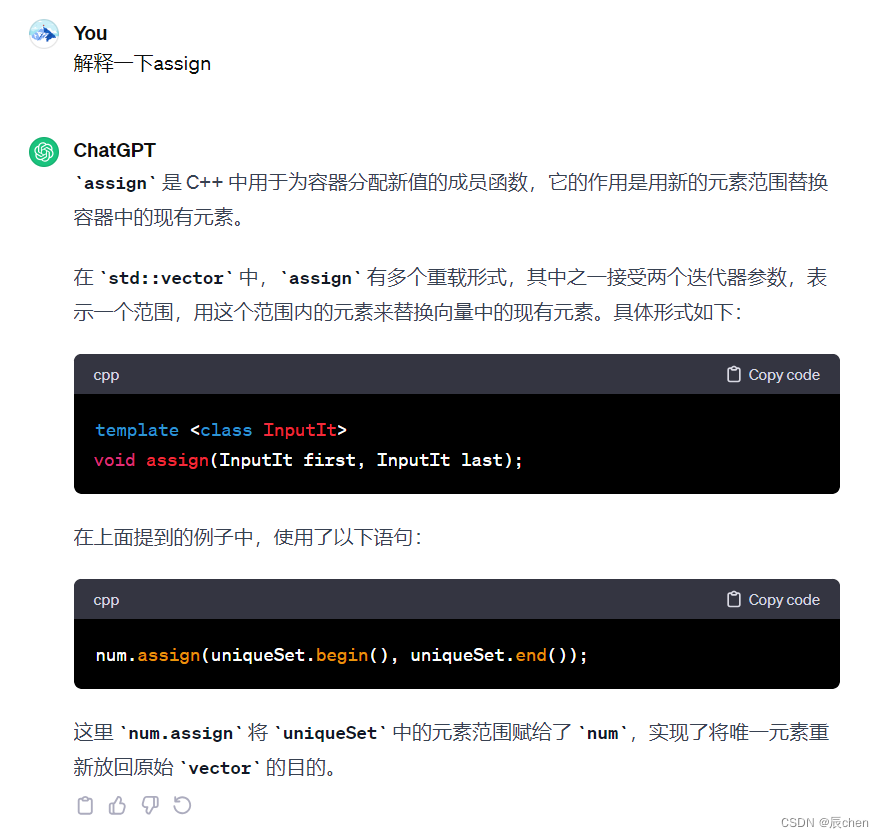
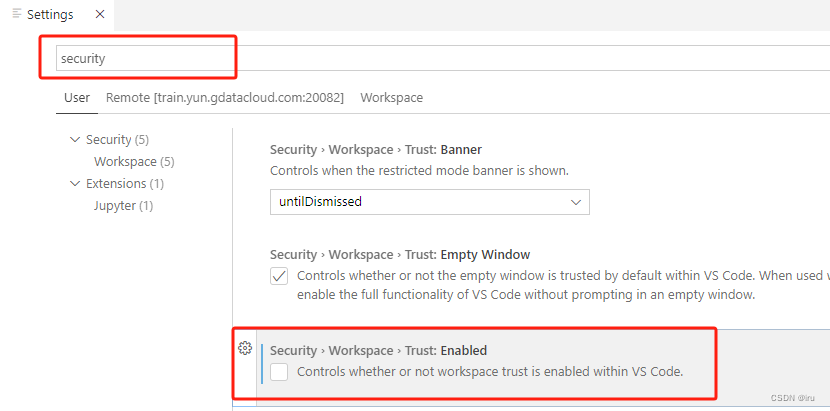
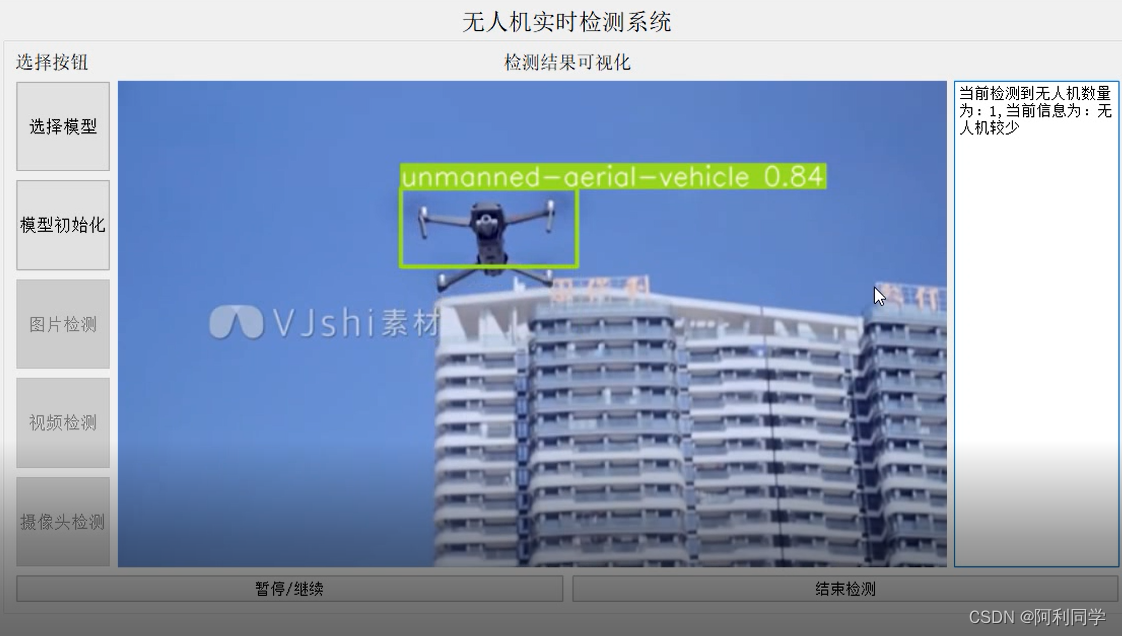
目录
- 前言
- 1 Masked 语言模型
- 2 跨语言模型
- 3 跨模态模型
- 4 GPT-3语言模型
- 5 T5: Text-to-Text 统一框架
- 6 Mixture of Experts (MoE)
- 结语
前言
近年来,预训练语言模型(PLM)领域取得了巨大的进展,开创了多个家庭成员,每个成员都在特定领域或任务上发挥着独特的作用。从双向信息预测到跨语言翻译,再到跨模态预训练,PLM家庭为自然语言处理(NLP)和相关任务提供了全新的思路。本文将深入研究PLM家庭的几个关键成员,包括masked语言模型、跨语言模型、跨模态模型等,并探讨它们的优点和缺陷。

1 Masked 语言模型
在PLM家庭中,masked语言模型是一个重要的成员,它通过预测目标token来进行训练。通过遮蔽输入序列中的一些token,模型被要求预测这些被遮蔽的token。这种方法能够使模型在理解上下文的基础上,更好地处理缺失的信息。然而,该方法在处理长距离依赖和全局一致性时可能面临一些挑战。

masked语言模型,特别是以BERT为代表的模型,为NLP领域的自然语言理解任务提供了强大的基础。然而,随着对长文本和全局信息理解需求的不断增加,对于这类任务的改进和优化仍然是未来研究的重要方向。
2 跨语言模型
在PLM家庭中,跨语言模型专注于实现不同语言之间的高效信息传递。通过采用语言翻译的方法,这类模型能够学得通用的语义表示,从而在多语言环境下展现出卓越的泛化能力。具体而言,通过使用双向信息预测目标token的技术,这些模型能够迅速适应多语境,实现出色的跨语言自然语言处理(NLP)任务性能。
这种跨语言模型的设计理念在于建立一个统一的语义空间,使得不同语言之间的信息可以更自然地传递和共享。通过对目标token进行双向信息预测,模型能够捕捉到语言间共享的语义特征,使得模型在不同语境下都能够理解和处理信息。
3 跨模态模型
PLM家庭的另一个令人振奋的发展方向是跨模态模型。这一类模型专注于在不同媒体之间建立紧密联系,最为典型的任务包括视频和文本之间的关联。通过训练模型同时考虑并整合不同模态的信息,这些跨模态模型能够实现更全面、深刻的理解,从而在多媒体处理任务中展现出独特的优势。
对于视频文本对和字幕生成等任务而言,跨模态模型的应用前景显得尤为重要。通过融合视觉和语言信息,模型可以更好地理解视频内容,捕捉关键事件,并生成准确、富有语境的字幕。这种方法不仅有望提高对多媒体数据的整体理解水平,还为实现更智能的多模态交互系统奠定了基础。
4 GPT-3语言模型
GPT-3,作为PLM家庭的一员,以其庞大的规模(175B参数)和卓越的性能引领了NLP的前沿。GPT-3引入了zero-shot和few-shot学习,在zero-shot学习中,模型能够通过利用其在训练中学到的泛化能力,处理以前未见过的类别或任务。零样本学习要求模型在没有先验信息的情况下完成任务。少样本学习是指模型在面对相对较少的训练样本时能够学到并执行任务的能力。在这种情况下,模型需要通过仅有的一小部分样本进行学习,并在推断或执行任务时表现出良好的泛化性能。少样本学习通常用于解决数据稀缺或新任务的情况。
5 T5: Text-to-Text 统一框架

T5(Text-to-Text)将NLP任务统一成了文本到文本的形式,使得各种任务都可以被视为生成问题或生成答案的问题。这种统一的框架使得T5模型具有很强的通用性,因为它不再需要为每个任务设计专门的结构,而是可以通过相同的生成问题和答案框架来处理各种不同类型的任务。这使得T5在处理多样化任务时更为灵活,能够轻松适应各种应用场景,包括文本分类、命名实体识别、语言生成等。
6 Mixture of Experts (MoE)
为了有效解决随着模型规模增加而带来的挑战,Mixture of Experts(MoE,专家混合)被引入,这一机制通过将整个模型参数分块,使得不同的专家(部分)可以独立地参与训练,从而形成了一个并行处理的结构。这一方法的引入不仅提高了模型的可训练性,还为进一步增加参数规模提供了可能性。

MoE的工作原理类似于将一个大型的神经网络模型拆分为多个专门处理不同任务或局部信息的子模型,这些子模型被称为专家。在训练时,每个专家负责处理特定的输入或场景,而全局控制器则决定各个专家的贡献程度。这种方式既克服了规模庞大的模型面临的训练难题,也提供了对更多参数的扩展性。
MoE的引入在处理大规模模型的同时,保持了模型的灵活性和可拓展性。这种机制的优势在于有效地利用了模型的参数,使得每个部分都可以独立地学到特定的表示,从而在整体上提高了模型的表达能力。随着MoE的不断发展和优化,它为PLM领域规模扩展提供了一种创新且高效的解决方案。
结语
PLM家庭的探索不仅为自然语言处理领域带来了新的思路,也在跨模态、跨语言等方面展示了卓越的性能。然而,这些模型依然面临一些挑战,如长距离依赖的处理和规模的不断增加。通过对新颖模型的引入和技术的不断改进,我们有望进一步解决这些问题,推动PLM家庭不断向前发展,为NLP领域带来更大的突破。