DANCE OF CHANNEL AND SEQUENCE:
AN EFFICIENT ATTENTION-BASED APPROACH FOR
MULTIVARIATE TIME SERIES FORECASTING
推荐阅读指数: ★★
大意了,没仔细看实验结果和模型图,精度了一篇有点不太行的文章,实验结果只有一张表,模型图又很简单,且机构也很一般。
文章目录
- 摘要
- 摘要要
- 详细摘要
- 贡献
- 模型介绍
- 过程
- 实验
- 评价
摘要
摘要要
通道独立性导致信息退化,文章提出CSformer来应对这一问题,CSformer中精心设计了两阶段的自注意力机制,该机制可以分别提取特定序列信息和通道信息,同时共享参数,还引入了序列适配器和通道适配器,实验结果领先
其创新点就是同时结合了序列和通道注意力,下图为对比
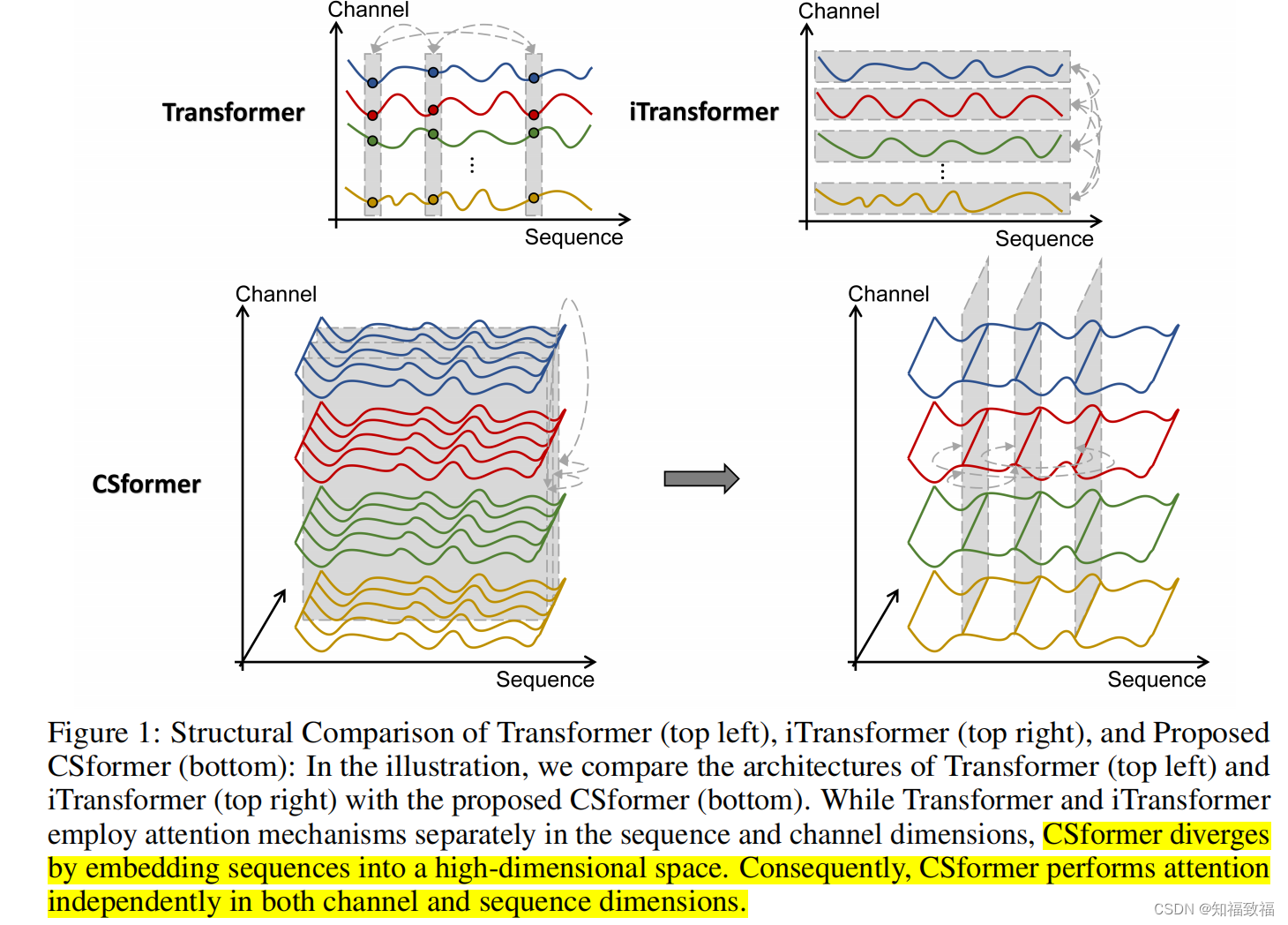
详细摘要
在最近的发展中,用于多变量时间序列分析的预测模型通过采用普遍的通道独立性原则展现出令人赞赏的性能。然而,必须承认通道之间的复杂相互作用根本上影响了多变量预测的结果。(针对通道独立性)
因此,尽管通道独立性的概念在一定程度上提供了实用性,但随着情况的发展,这变得越来越不切实际,导致信息的退化。为了应对这一紧迫问题,我们提出了CSformer,这是一个创新的框架,其特点是精心设计的两阶段自注意机制。
这个机制能够分别提取特定序列信息和特定通道信息,同时共享参数以促进序列和通道之间的协同和相互强化。同时,我们引入了序列适配器和通道适配器,确保模型能够识别跨各个维度的显著特征。这一增强显著提升了多变量时间序列数据特征提取的能力,促进了对可用信息的更全面利用。
我们在真实世界的多个数据集上进行了实验,证明了模型的鲁棒性和先进性,保持了基于transform的模型的领先地位。
贡献
propose CSformer
CSformer achieves state-of-the-art performance
conducted an extensive array of ablation experiments
(给人感觉水了吧唧的)
模型介绍
(这图有点lowlow的)
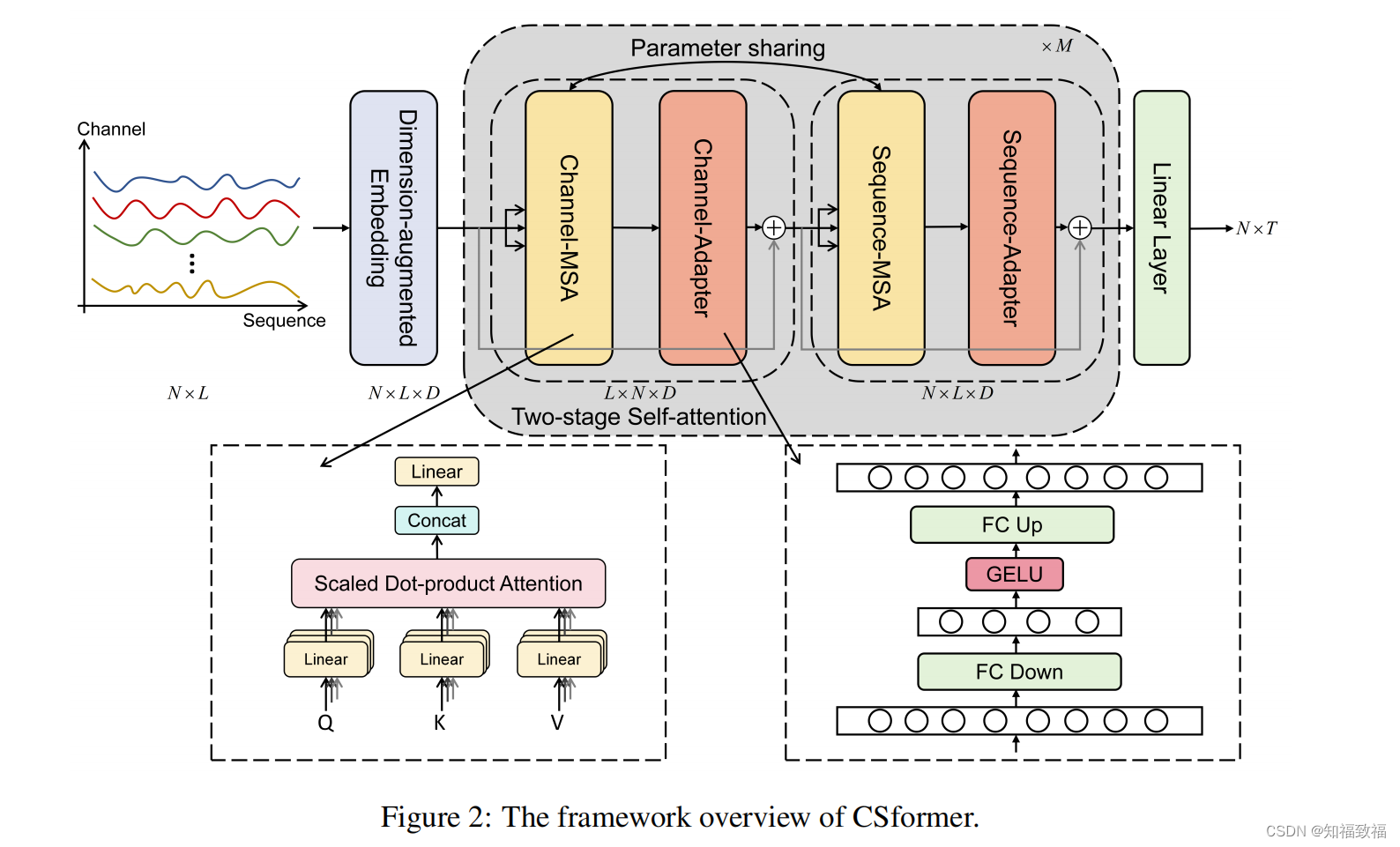
过程
-
可逆的归一化
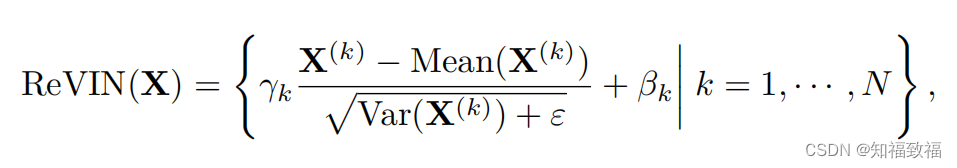
-
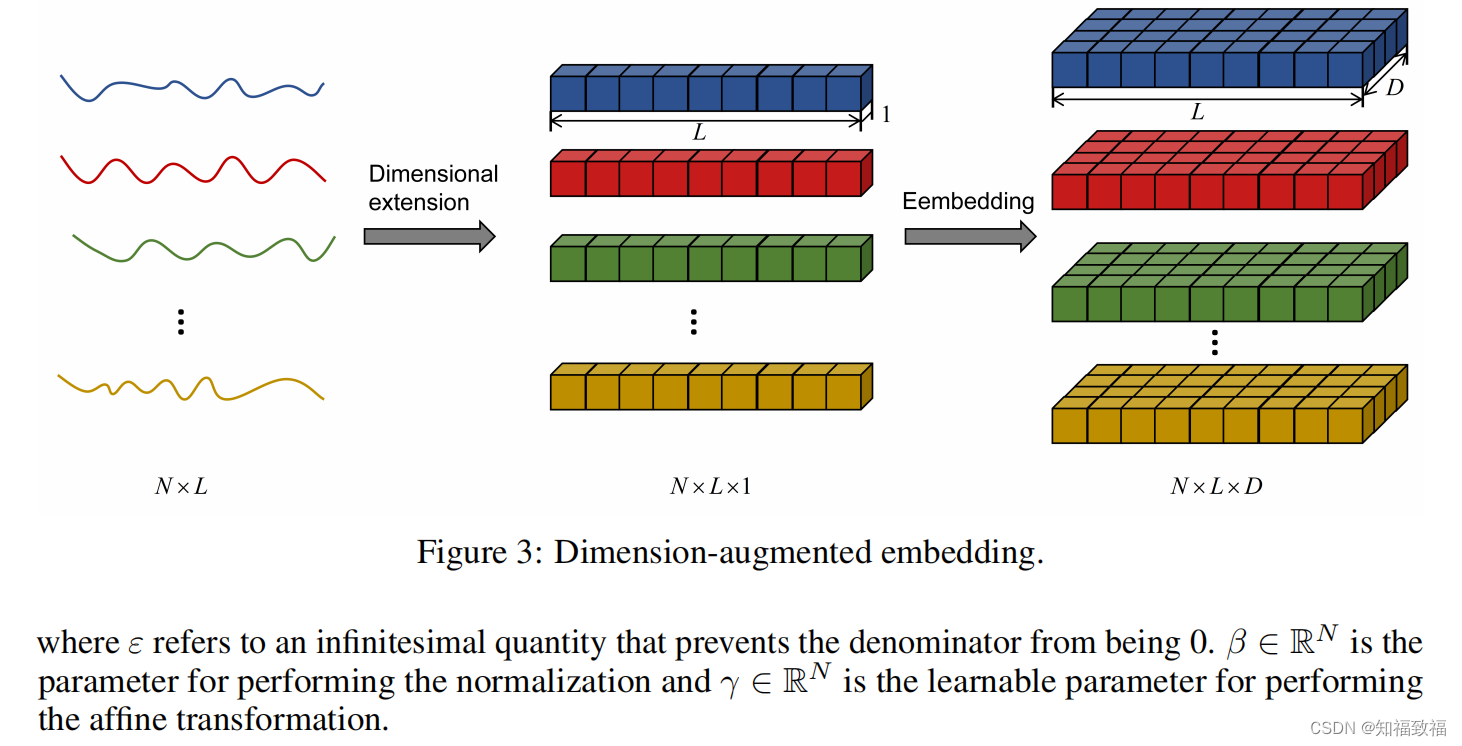
维度增广
-
两阶段多头注意力机制( two-stage Multi-head Self-Attention)
差别就是交换了N和L维度
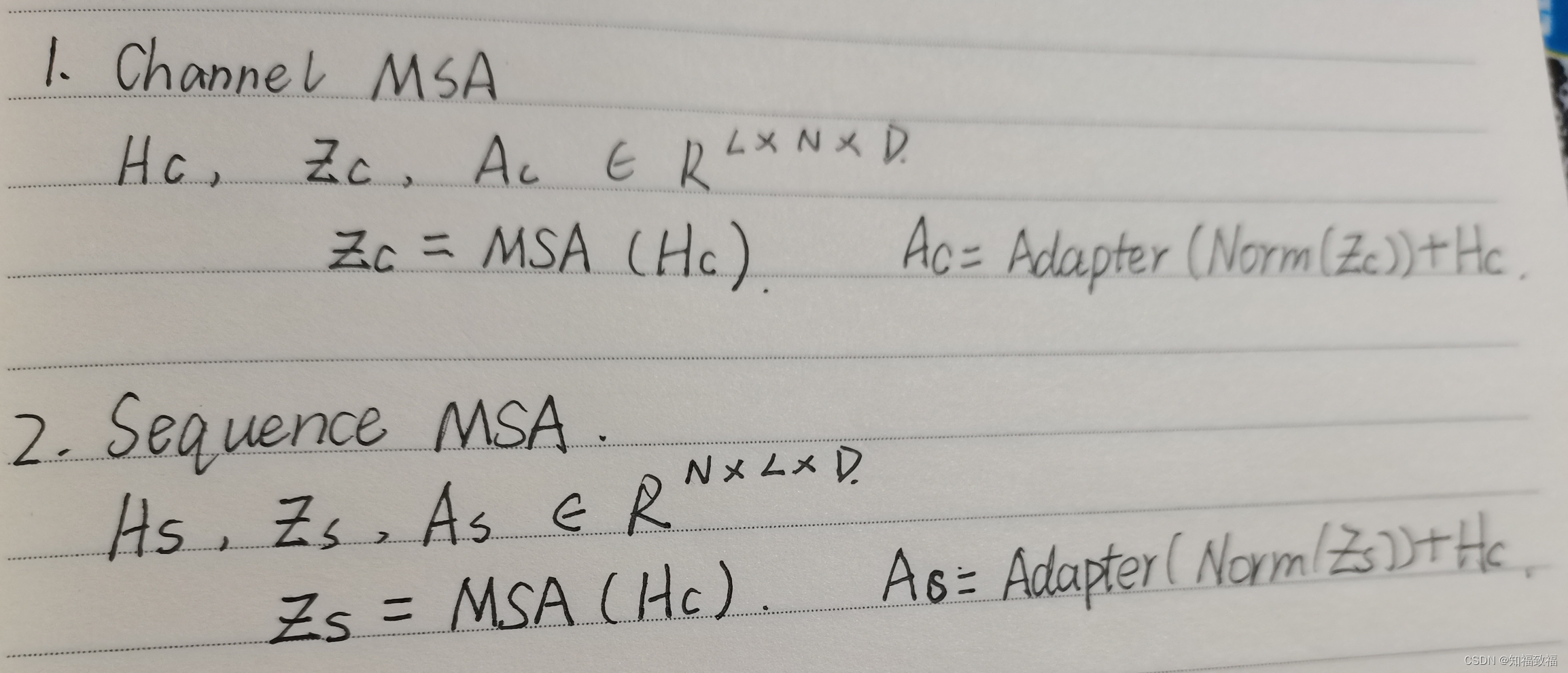
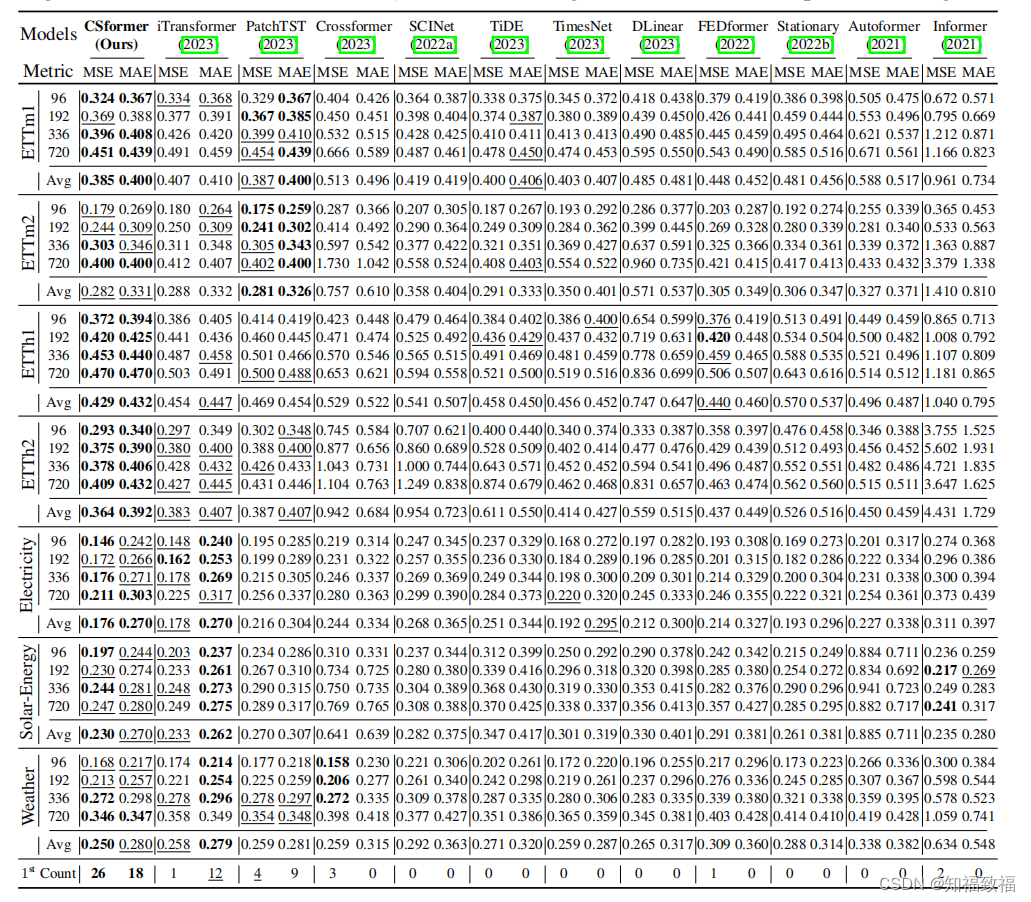
实验
只给出了对比实验的结果
包括iTransformer和CSformer
评价
这文章缺东西呀,提到的两阶段的参数共享机制没有讲,贡献里面提到的消融实验也没有讲,哈哈哈哈哈血亏