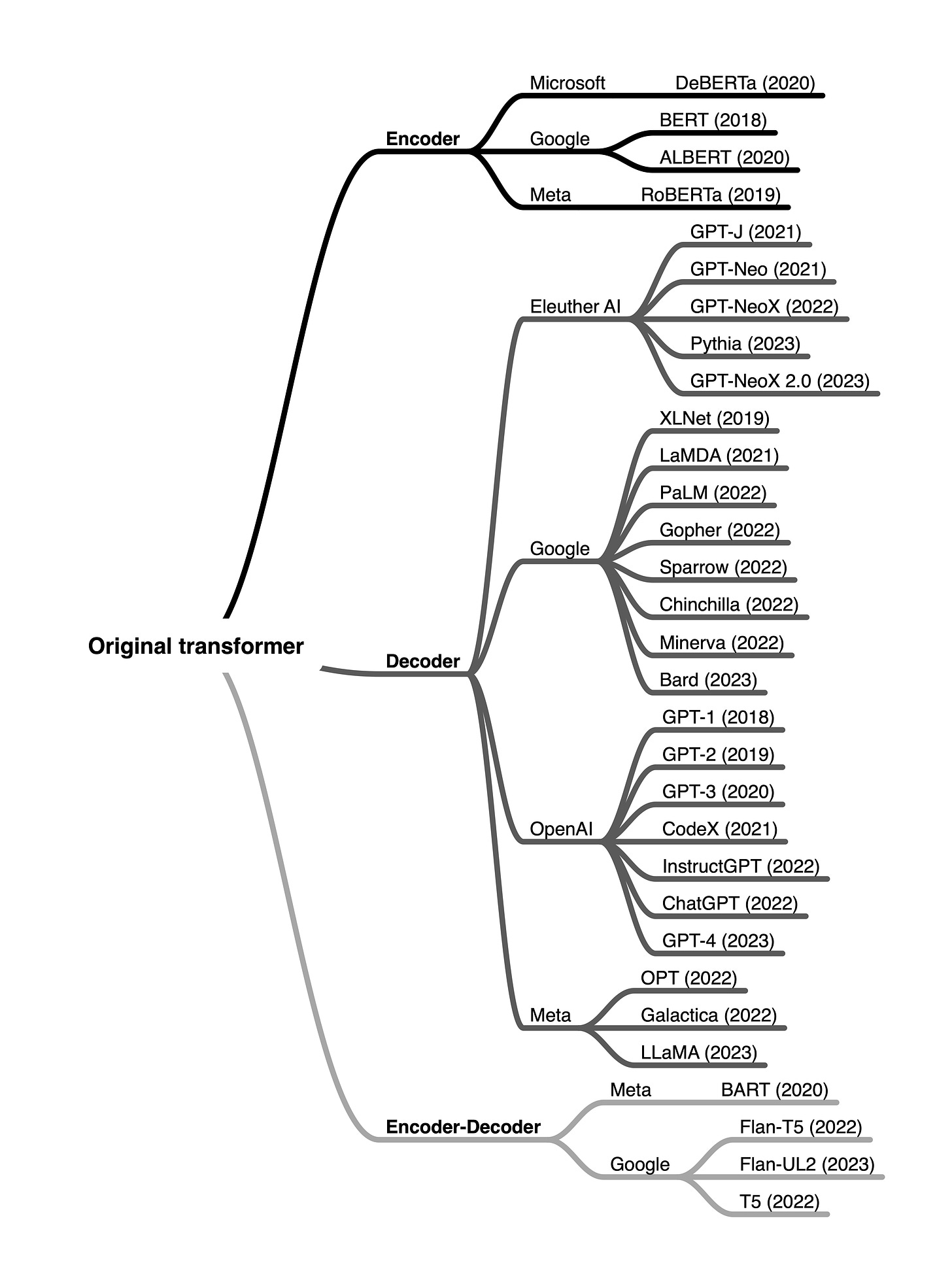
更多Python学习内容:ipengtao.com
shift() 是 Pandas 中一个常用的数据处理函数,它用于对数据进行移动或偏移操作,常用于时间序列数据或需要计算前后差值的情况。本文将详细介绍 shift() 函数的用法,包括语法、参数、示例以及常见应用场景。
什么是 shift() 函数?
shift() 函数是 Pandas 库中的一个数据处理函数,用于将数据按指定方向移动或偏移。它可以对时间序列数据或其他类型的数据进行操作,通常用于计算时间序列数据的差值、百分比变化等。该函数的主要作用是将数据移动到指定的行或列,留下空白或填充 NaN 值。
shift() 函数的语法
shift() 函数的基本语法如下:
DataFrame.shift(periods=1, freq=None, axis=0, fill_value=None)参数说明:
-
periods:指定移动的步数,可以为正数(向下移动)或负数(向上移动)。默认为 1。 -
freq:可选参数,用于指定时间序列数据的频率,通常用于时间序列数据的移动操作。 -
axis:指定移动的方向,可以为 0(默认,沿行移动)或 1(沿列移动)。 -
fill_value:可选参数,用于填充移动后留下的空白位置,通常为填充 NaN 值。
shift() 函数的示例
通过一些示例来演示 shift() 函数的用法。
示例 1:向下移动数据
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 向下移动一行数据
df_shifted = df.shift(periods=1)
print(df_shifted)输出结果:
A B
0 NaN NaN
1 1.0 10.0
2 2.0 20.0
3 3.0 30.0
4 4.0 40.0在这个示例中,创建了一个包含两列数据的 DataFrame,并使用 shift() 函数向下移动了一行数据。移动后,第一行的数据被填充为 NaN。
示例 2:向上移动数据
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 向上移动一行数据
df_shifted = df.shift(periods=-1)
print(df_shifted)输出结果:
A B
0 2.0 20.0
1 3.0 30.0
2 4.0 40.0
3 5.0 50.0
4 NaN NaN这个示例,使用负数的 periods 参数将数据向上移动了一行。最后一行的数据被填充为 NaN。
示例 3:向右移动列数据
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 向右移动一列数据
df_shifted = df.shift(periods=1, axis=1)
print(df_shifted)输出结果:
A B
0 NaN 1.0
1 NaN 2.0
2 NaN 3.0
3 NaN 4.0
4 NaN 5.0在这个示例中,使用 axis=1 参数将列数据向右移动了一列,左边填充为 NaN。
示例 4:指定填充值
import pandas as pddata = {'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 向下移动一行数据,填充空白处为 0
df_shifted = df.shift(periods=1, fill_value=0)
print(df_shifted)输出结果:
A B
0 0 0
1 1 10
2 2 20
3 3 30
4 4 40在这个示例中,使用 fill_value 参数指定了填充值为 0,因此移动后的空白位置被填充为 0。
常见应用场景
shift() 函数在处理时间序列数据、计算数据差值、计算百分比变化等方面非常有用。
1. 计算时间序列数据的差值
import pandas as pd# 创建一个包含时间序列数据的DataFrame
data = {'Date': pd.date_range(start='2023-01-01', periods=5, freq='D'),'Price': [100, 105, 110, 108, 112]}
df = pd.DataFrame(data)# 计算每日价格的差值
df['Price_Diff'] = df['Price'].diff()
print(df)输出结果:
Date Price Price_Diff
0 2023-01-01 100 NaN
1 2023-01-02 105 5.0
2 2023-01-03 110 5.0
3 2023-01-04 108 -2.0
4 2023-01-05 112 4.02. 计算数据的滞后值或前值
import pandas as pd# 创建一个包含数据的DataFrame
data = {'Value': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)# 计算数据的滞后值(前一行的值)
df['Lagged_Value'] = df['Value'].shift(1)
print(df)输出结果:
Value Lagged_Value
0 10 NaN
1 20 10.0
2 30 20.0
3 40 30.0
4 50 40.03. 计算数据的百分比变化
import pandas as pd# 创建一个包含数据的DataFrame
data = {'Sales': [1000, 1200, 1500, 1300, 1600]}
df = pd.DataFrame(data)# 计算数据的百分比变化
df['Percentage_Change'] = (df['Sales'] - df['Sales'].shift(1)) / df['Sales'].shift(1) * 100
print(df)输出结果:
Sales Percentage_Change
0 1000 NaN
1 1200 20.0
2 1500 25.0
3 1300 -13.3
4 1600 23.14. 创建滑动窗口统计信息
import pandas as pd# 创建一个包含数据的DataFrame
data = {'Value': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}
df = pd.DataFrame(data)# 计算数据的滑动平均值(窗口大小为3)
df['Moving_Average'] = df['Value'].rolling(window=3).mean()
print(df)输出结果:
Value Moving_Average
0 1 NaN
1 2 NaN
2 3 2.0
3 4 3.0
4 5 4.0
5 6 5.0
6 7 6.0
7 8 7.0
8 9 8.0
9 10 9.0总结
shift() 函数是 Pandas 中用于移动或偏移数据的重要工具。它可以处理时间序列数据、计算数据差值以及进行数据预处理。通过本文的介绍和示例,应该已经掌握了 shift() 函数的基本用法和常见应用场景。在实际数据分析和处理中,熟练使用这个函数将有助于提高工作效率和数据处理的精度。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容