论文:DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation
代码:https://sstzal.github.io/DiffTalk/
出处:CVPR2023
特点:需要音频+对应人物的视频来合成新的说话头视频,嘴部抖动严重
一、背景
talking head 合成任务相关的工作最近都集中于提升合成视频的质量或者提升模型的泛化性,很少有工作聚焦于同时提升这两个方面,而这对实际的使用很重要
所以,本文作者引入扩散模型来实现 audio-driven talking head,同时使用的声音信号、面部、关键点来作为驱动信号,可以在不同的的说话人上进行泛化
当前的研究现状:
- 2D:主要是基于 GAN 来实现 audio-to-lip 的驱动,也就是主要是声音到嘴型的驱动,不同的模特都可以被驱动,能泛化于不同的模特之间(因为主要是驱动的嘴巴,其他部分还是保持视频原状即可)。但 GAN 训练容易坍塌,且生成的视频分辨率不高,看着比较模糊
- 3D:如 NeRF,能够生成看起来质量较高的视频,但很难泛化,一般一个模型只能支持一个模特的渲染,泛化性较差
因此,作者选择了更好训练的扩散模型,将 audio-driven talking head 的合成看做一个 audio-driven 的连续时序的去噪过程
如图 1 所示,输入一个语音序列,DiffTalk 可以根据一个人物的一段视频来生成这个人物的新的说话视频

二、方法
DiffTalk 的整体结构如图 2 所示
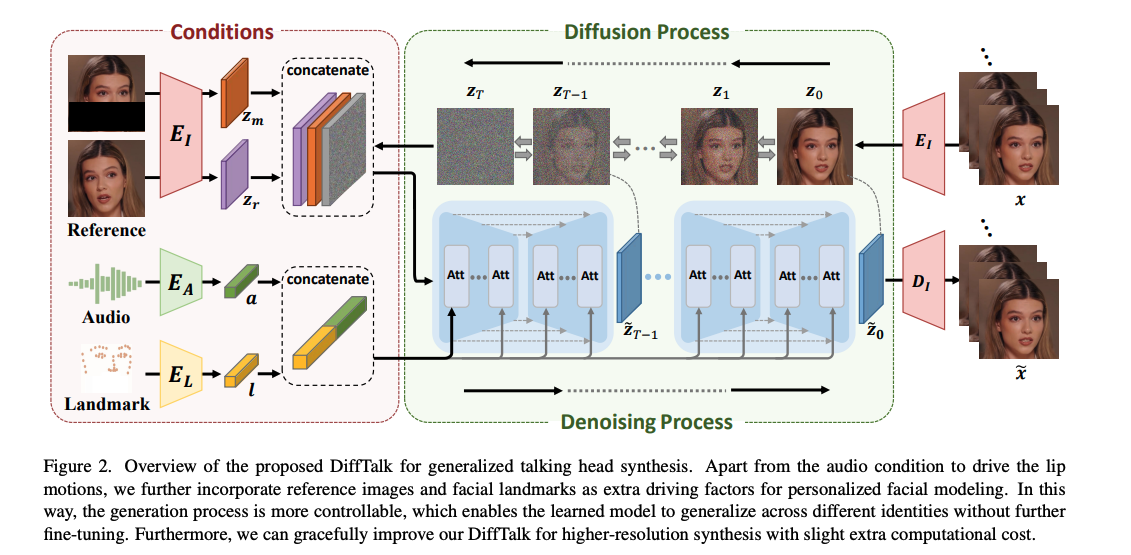
2.1 针对 Talking head 的条件扩散模型
现在潜在扩散模型 LDM 应用很广泛,所以这里作者使用的也是 LDM
作者使用了一对儿训练好的 image encoder E I E_I EI 和 decoder D I D_I DI,在后续训练的时候固定权重不做训练
基于此,输入的人脸图片就会被编码到隐空间 z 0 = E I ( x ) ∈ R h × w × 3 z_0=E_I(x) \in R ^{h \times w \times 3} z0=EI(x)∈Rh×w×3,h 和 w 是原图大小 H 和 W 经过压缩后的大小,压缩倍数是下采样参数
一般的 LDM 都是一个时间序列的 UNet 去噪网络 M M M,学习的是反向去噪过程:

但在本文中,给定一个人物的 source identity 和 driven audio,本文的目标是训练一个模型能够生成和语音匹配的说话头视频,且要保留原始 identity 信息
所以,语音信号是一个基础条件来控制如何去噪
2.2 Identity-Preserving Model Generalization
在学习音频到唇部翻译的同时,另一个重要任务是在保留源图像中完整身份信息的同时实现模型的泛化。泛化的身份信息包括面部外观、头部姿态和图像背景。
为此,作者设计了一个参考机制,使模型能够泛化到训练中未见过的新个体
如图 2 所示,选择一个随机的源身份面部图像 xr 作为参考,其中包含外观和背景信息。为了防止训练中的捷径,会限制选择的 xr 与目标图像相距 60 帧以上。然而,由于真实的面部图像与 xr 的姿态完全不同,模型预期在没有任何先验信息的情况下将 xr 的姿态转移到目标面部上。
因此,作者将掩蔽的真实图像 xm 作为另一个参考条件来提供目标头部姿态的指导。xm 的嘴部区域被完全掩盖,以确保网络看不到真实的唇部动作。这样,参考 xr 专注于提供嘴部外观信息,这也降低了训练的难度。
同时,还使用 MLP encoder E L E_L EL 对面部关键点(除过嘴部)进行了编码,也作为条件
所以整个输入条件就变成了:
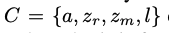
整个优化目标就是:
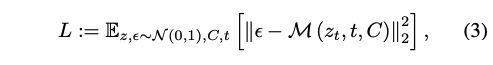
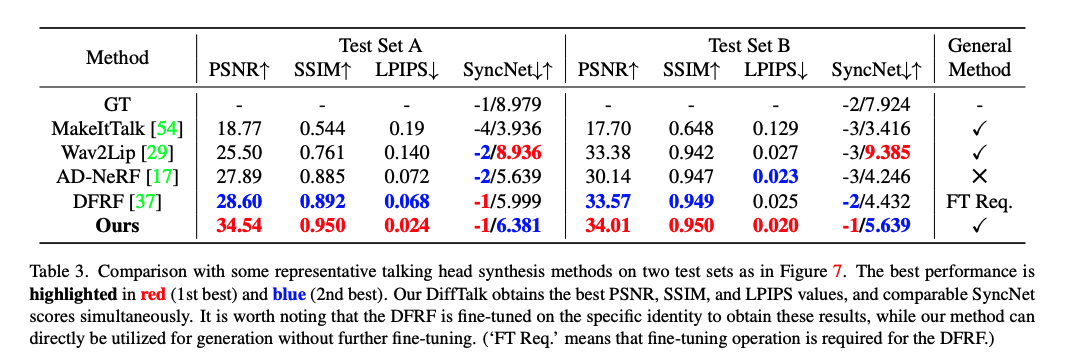
三、效果
数据:
- HDTF 数据集,包括 16 小时视频,分辨率为 720P 或 1080P 的,超过 300 个人物
- 作者随机选择了 100 个视频,抽取了约 100 min 时长的视频作为训练
- resize 输入数据到 256x256,隐空间编码大小为 64x64x3,如果要训练大分辨率模型,输入是 512x512,隐空间编码大小同样为 64x64x3