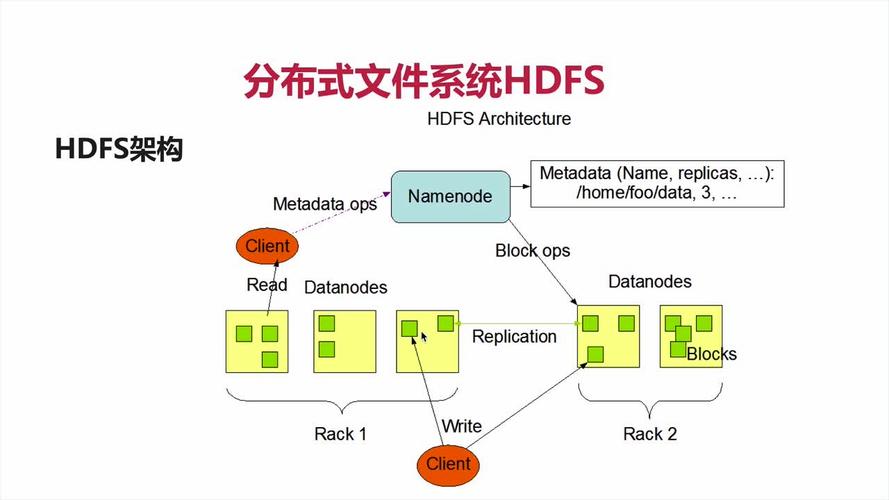
同学们发现没有,对比学习在我们的日常工作生活中已经很常见了,比如推荐系统任务,为用户推荐相似的商品或预测用户的购买行为;又比如图像检索,为用户找相似图片或识别不同物体。另外还有语音识别、人脸识别、NLP(文本分类、情感分析和机器翻译)等,都离不开对比学习技术。
更贴合科研er来讲,对比学习可以帮助我们更好地理解和利用数据集中的信息,提高模型的性能和表现。因此,为了更好地帮助相关领域的同学改模型发paper,今天我就梳理了2023-2024最新的对比学习相关的顶会论文,对应代码也一并整理好了。
论文原文和代码看文末
2024
Improving the Robustness of Knowledge-Grounded Dialogue via Contrastive Learning(AAAI’24)
通过对比学习提高基于知识的对话框的鲁棒性
「简述:」为了提高知识对话系统(KGD)的鲁棒性,作者提出了一种基于实体的对比学习框架。这个框架利用KGD样本中的实体信息来创建正样本和负样本。正样本包含语义无关的噪声,而负样本则包含语义相关的噪声。通过对比学习,该框架确保KGD模型能够识别和处理这两种类型的噪声,从而在现实应用中生成更有意义的回复。实验结果表明,该方法在基准数据集上取得了最佳性能,并且在有噪声和少样本的情况下也表现优异。

TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning(AAAI’24)
用于通用时间序列表示学习的自监督对比学习
「简述:」由于时间序列具有特殊的时序特征,仅仅依靠其他领域的经验指导可能无法有效处理时间序列,并且难以适应多个下游任务。因此,本文对自监督对比学习中的三个部分进行了研究,包括设计正样本的增强方法、构建(硬)负样本和设计自监督对比学习损失函数。为了解决这些问题,作者提出了一种新的自监督框架TimesURL,并引入了基于频率-时序的增强方法和双重统一体作为硬负样本来引导更好的对比学习。

MixCon3D: Synergizing Multi-View and Cross-Modal Contrastive Learning for Enhancing 3D Representation(ICLR’24)
协同多视角和跨模态对比学习以增强3D表示
「简述:」本文介绍了一种名为MixCon3D的方法,结合2D图像和3D点云的互补信息来增强对比学习。通过整合多视角2D图像,MixCon3D提供了更准确、更全面的现实世界3D对象描述,并支持文本对齐。该方法在基准测试上表现出色,比基线有显著改进,并在具有挑战性的1,156类别Objaverse-LVIS数据集上超过了先前最先进的性能5.7%。

2023
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
基于单模态监督的多模态对比学习的多模态分类
「简述:」论文提出了一种新颖的多模态对比学习方法,用于在弱监督的单模态预测下探索更可靠的多模态表示。具体来说,作者首先从引入的单模态预测任务中捕获与任务相关的单模态表示和单模态预测。然后,通过设计的多模态对比方法,在单模态预测的监督下将单模态表示与更有效的一个对齐。在两个图像-文本分类基准测试UPMC-Food-101和N24News上使用融合特征进行的实验表明该学习方法优于当前最先进的多模态方法。

MA-GCL: Model Augmentation Tricks for Graph Contrastive Learning (AAAI’23)
用于图对比学习的模型增强技巧
「简述:」论文介绍了一种名为MA-GCL的方法,针对图对比学习中的难点提出了模型增强技巧。作者认为,在图上生成对比视图比在图像上更具挑战性,因为缺乏如何显著增强图形而不改变其标签的先验知识。作者提出了三种易于实现的模型增强技巧,即非对称、随机和洗牌,它们可以分别帮助减轻高频噪声、丰富训练实例和带来更安全的增强。实验结果表明,通过在简单基模型上应用这三种技巧,MA-GCL可以在节点分类基准测试中实现最先进的性能。

Disentangled Contrastive Collaborative Filtering (SIGIR’23)
解耦对比协同过滤
「简述:」作者认为现有的图对比学习算法忽略了用户-物品交互行为通常由多样的潜在意图因素驱动的事实,并且它们引入的非自适应增强技术容易受到噪声信息的影响。为了解决这些问题,作者提出了一个解耦对比协同过滤框架,通过学习具有全局上下文的解耦表示来实现意图解耦,并利用参数化交互掩码生成器引入跨视图对比学习任务以实现自适应增强。

Augmented Negative Sampling for Collaborative Filtering(Recsys’23)
用于协同过滤的增强负采样
「简述:」本文介绍了增强型负采样协同过滤,这是一种用于从大量未标记数据中构建负面信号以指导监督学习的隐式反馈方法。作者引入了增强型负样本来解决现有方法的限制,并提供了一个具体实例。该方法通过将负项目的困难和容易因素分开,仅增强容易因素生成新的候选负样本,并设计了一种先进的负采样策略来确定最终的增强型负样本。实验结果表明,该方法显著优于最先进的基线。

Exploring False Hard Negative Sample in Cross-Domain Recommendation(Recsys’23)
跨域推荐中虚假硬负样本的探索
「简述:」传统的负采样方法倾向于选择有信息的硬负样本(HNS),而不是默认的随机样本。然而,这些硬负采样方法通常会遇到假的硬负样本(FHNS)的问题,即当一个用户-物品交互未被观察到时被选为负样本,而用户实际上会在接触到该物品后与其进行交互。为了解决这个问题,本文提出了一种针对跨领域推荐的新型与模型无关的真实硬负采样框架,旨在通过通用和跨领域的真实硬负样本选择器发现所有HNS中的假的并提炼真实的。

Multi-Scale Subgraph Contrastive Learning
多尺度子图对比学习
「简述:」作者发现在图结构中进行数据增强后,增强后的图结构的语义信息可能与原始图结构不一致,并且两个增强的图是否为正例或反例与多尺度结构密切相关。基于这一发现,作者提出了一种多尺度子图对比学习方法,能够刻画细粒度的语义信息。该方法在不同尺度下基于子图采样生成全局和局部视图,并根据其语义关联构建多个对比关系,以提供更丰富的自监督信号。实验表明该方法有效。

uCTRL: Unbiased Contrastive Representation Learning via Alignment and Uniformity for Collaborative Filtering (SIGIR’23)
通过对齐性和均匀性学习的无偏对比学习表示
「简述:」本文提出了一种名为uCTRL的无偏对比表示学习方法,通过优化基于InfoNCE损失函数的对齐和均匀性函数来解决协同过滤模型中存在的流行度偏差问题。具体来说,该方法使用了一种新颖的未被偏见影响的对齐函数,并设计了一种新颖的IPW估计方法来消除用户和物品的偏见。在四个基准数据集上,uCTRL与现有的CF模型相结合,始终优于最先进的无偏推荐模型。

Contrastive Learning for Conversion Rate Prediction(SIGIR’23)
用于转化率预测的对比学习
「简述:」论文提出了一种名为CL4CVR的对比学习框架,用于转化率预测。它利用未标记数据来学习更好的数据表示,并提高转化率预测性能。作者还提出了一些新的组件,如嵌入遮罩、假阴性消除和监督正包含,以解决数据稀疏性问题,充分利用稀缺的用户转化事件。实验结果表明,该方法在两个实际世界数据集上表现优越。

Meta-optimized Contrastive Learning for Sequential Recommendation (SIGIR’23)
序列推荐中的元优化对比学习
「简述:」论文提出了一种元优化对比学习框架MCLRec,用于序列推荐。该模型通过应用数据增强和可学习的模型增强操作来创新标准的CL框架,以自适应地捕捉隐藏在随机数据增强中的有信息的特征。此外,MCLRec利用元学习方式指导模型增强器的更新,以提高对比对的质量,而无需增加输入数据的数量。最后,作者引入了一个对比正则化项,以鼓励增强模型生成更具信息量的增强视图,并避免在元更新中出现过于相似的对比对。在常用的数据集上的实验结果表明,MCLRec是有效的。

Generative-Contrastive Graph Learning for Recommendation (SIGIR’23)
用于推荐的生成式对比图学习
「简述:」本文提出了一种变分图生成式对比学习(VGCL)框架,用于推荐系统。该模型将用户-物品图视为一个整体,并利用变分图重建来估计每个节点的高斯分布。然后,通过从估计的分布中进行多次采样来生成多个对比视图,从而在生成式和对比式学习之间建立联系。此外,为每个节点调整估计方差,以调节优化过程中每个节点的对比损失的规模。考虑到估计分布之间的相似性,作者还提出了一种集群感知的双重对比学习,即节点级别和集群级别,以鼓励节点和集群中的节点之间的一致性。最后,在三个公共数据集上的大量实验结果清楚地证明了所提出模型的有效性。

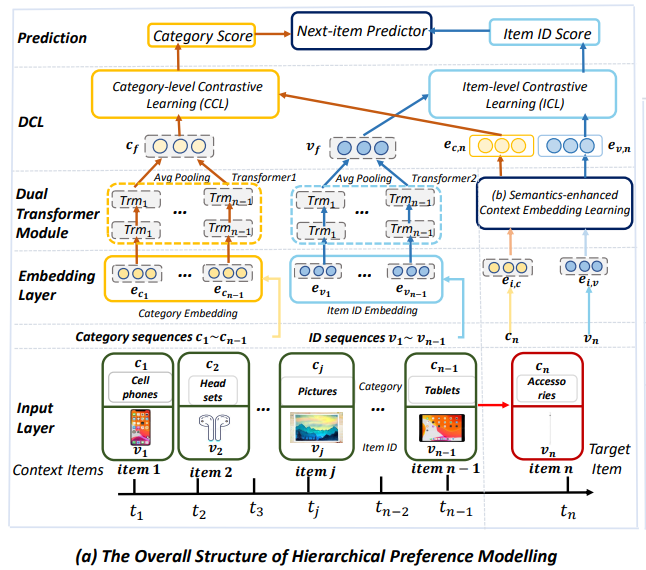
Dual Contrastive Transformer for Hierarchical Preference Modeling in Sequential Recommendation (SIGIR’23)
用于序列推荐中层次化偏好建模的双对比Transformer
「简述:」本文提出了一种新的层次化偏好建模框架,用于准确地进行序列推荐。该框架设计了一个新颖的双重转换器模块和双重对比学习方案,以区分性地学习用户的低层次和高层次偏好,并有效地增强低层次和高层次偏好的学习。此外,还设计了一种新的语义增强上下文嵌入模块,以生成更丰富的上下文嵌入,进一步提高推荐性能。在六个真实数据集上的大量实验表明,该方法优于现有方法,并且设计合理。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“24对比”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏