1、在yolov5/models下面新建一个A2Attention.py文件,在里面放入下面的代码
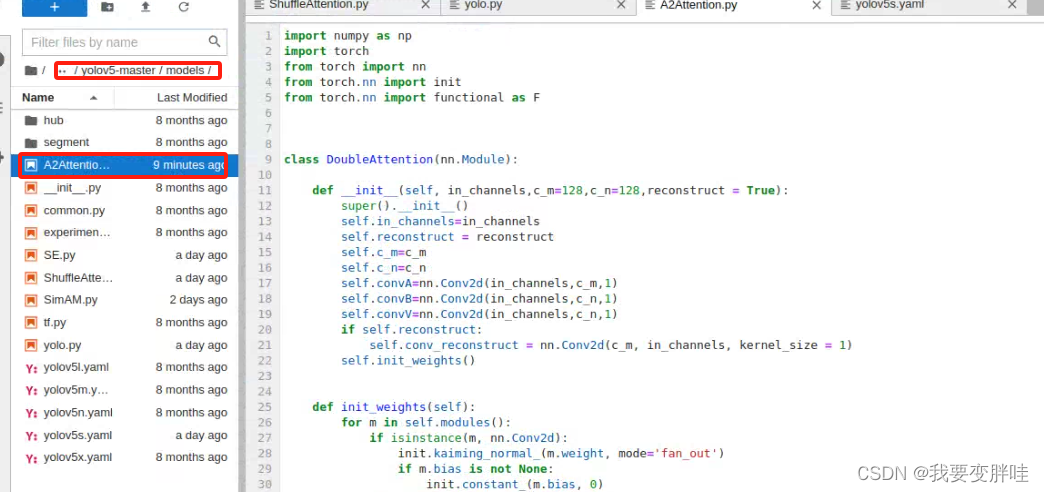
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as Fclass DoubleAttention(nn.Module):def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):super().__init__()self.in_channels=in_channelsself.reconstruct = reconstructself.c_m=c_mself.c_n=c_nself.convA=nn.Conv2d(in_channels,c_m,1)self.convB=nn.Conv2d(in_channels,c_n,1)self.convV=nn.Conv2d(in_channels,c_n,1)if self.reconstruct:self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)self.init_weights()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, h,w=x.shapeassert c==self.in_channelsA=self.convA(x) #b,c_m,h,wB=self.convB(x) #b,c_n,h,wV=self.convV(x) #b,c_n,h,wtmpA=A.view(b,self.c_m,-1)attention_maps=F.softmax(B.view(b,self.c_n,-1))attention_vectors=F.softmax(V.view(b,self.c_n,-1))# step 1: feature gatingglobal_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n# step 2: feature distributiontmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*wtmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,wif self.reconstruct:tmpZ=self.conv_reconstruct(tmpZ)return tmpZ 2、找到yolo.py文件,进行更改内容
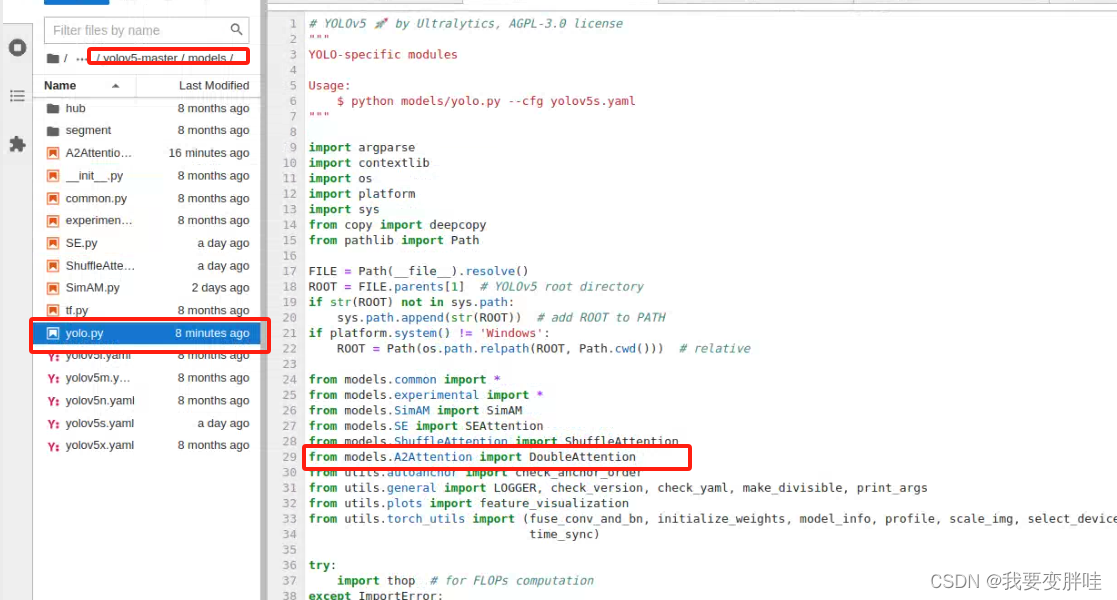
在29行加一个from models.A2Attention. import DoubleAttention, 保存即可
3、找到自己想要更改的yaml文件,我选择的yolov5s.yaml文件(你可以根据自己需求进行选择),将刚刚写好的模块DoubleAttention加入到yolov5s.yaml里面,并更改一些内容。更改如下
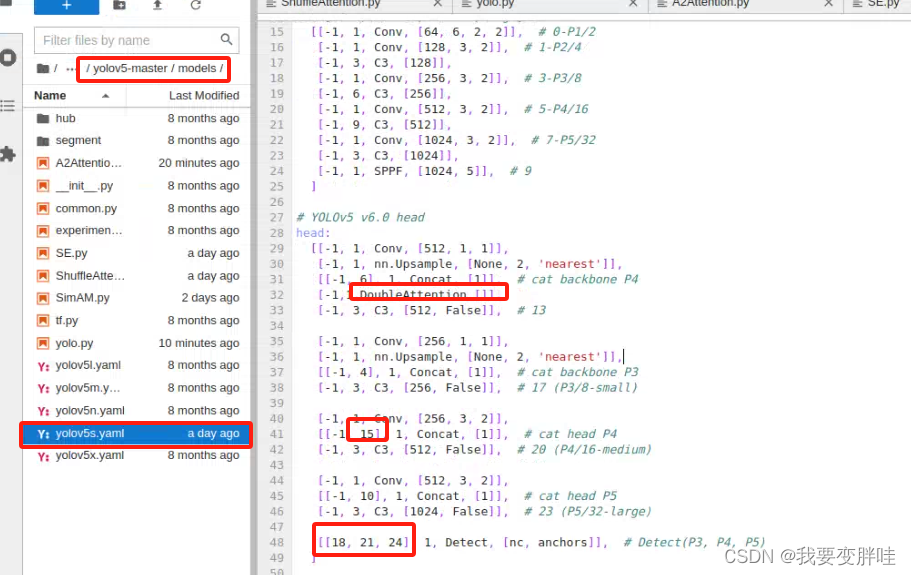
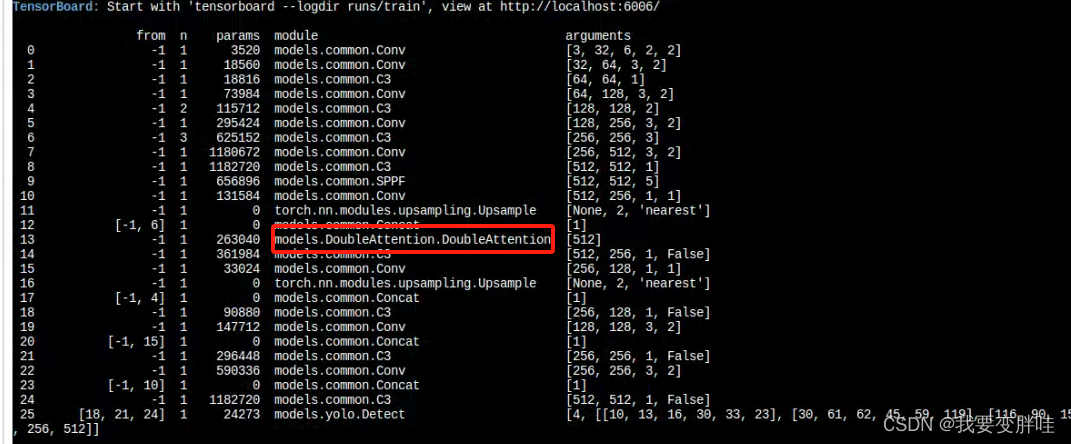
4、在yolo.py里面加入两行代码(335-337)
保存即可!

运行一下