信息存储
大多数计算机使用 8 位的块,或者字节(byte),作为最小的可寻址的内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存(virtual memory)。内存的每个字节都由一个唯一的数字来标识,称为它的地址(address),所有可能地址的集合就称为虚拟地址空间(virtual address space)。顾名思义,这个虚拟地址空间只是一个展现给机器级程序的概念性映像。
编译器和运行时系统将存储器空间划分为更可管理的单元,来存放不同的程序对象(program object),即程序数据、指令和控制信息可以用各种机制来分配和管理程序不同部分的存储。这种管理完全是在虚拟地址空间里完成的。
十六进制表示法
二进制表示法太冗长,而十进制表示法与位模式的互相转化很麻烦。替代的方法是,以16 为基数,或者叫做 十六进制(hexadecimal) 数,来表示位模式。十六进制(简写为“hex”)使用数字 ‘0’ ~ ‘9’ 以及字符’A’ ~ ‘F’来表示 16 个可能的值。

C,C++ 种以 0x 或 0X 开头的数字常量被认为是十六进制的值。 十六进制不区分大小写
字数据大小
每台计算机都有一个字长(word size),指明指针数据的标称大小(nominalsize)。
因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为 w w w 位的机器而言,虚拟地址的范围为 0 2 w − 1 0~2^w-1 0 2w−1,程序最多访问 2 w 2^w 2w 个字节。
32 位字长限制虚拟地址空间为 4 千兆字节(写作 4GB),刚刚超过 4 × 1 0 9 4 \times 10^9 4×109 字节。扩展到 64 位字长使得虚拟地址空间为 16EB,大约是 1.84 × 1 0 19 1.84 \times 10^{19} 1.84×1019 字节。
大多数 64 位机器也可以运行为 32 位机器编译的程序,这是一种向后兼容。
该程序就可以在32 位或64 位机器上正确运行
程序用下述伪指令编译:
linux> gcc -m32 xxx.c
linux> gcc -m64 xaxx.c
C 语言各种数据类型分配的字节数:
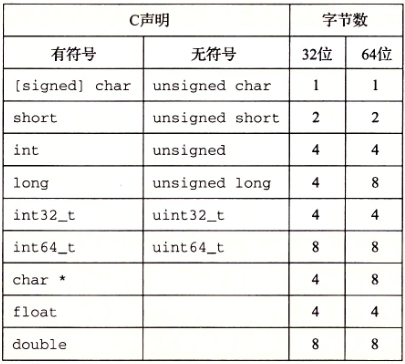
C/C++ 语言中,下列声明都是一个意思:
unsigned long
unsigned long int
long unsigned
long unsigned int
寻址和字节顺序
对于跨越多字节的程序对象,必须建立两个规则:这个对象的地址是什么,以及在内存中如何排列这些字节。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
排列表示一个对象的字节有两个通用的规则。考虑一个 w w w 位的整数,其位表示为 [ x w − 1 , z w − 2 , . . . , x 1 , x 0 ] [x_{w-1},z_{w-2},...,x_1,x_0] [xw−1,zw−2,...,x1,x0],其中 x w − 1 x_{w-1} xw−1 是最高有效位,而 0 是最低有效位。
假设 w w w 是8 的倍数,这些位就能被分组成为字节,其中最高有效字节包含位 [ x w − 1 , z w − 2 , . . . , x w − 8 ] [x_{w-1},z_{w-2},...,x_{w-8}] [xw−1,zw−2,...,xw−8],而最低有效字节包含位 [ x 7 , z 6 , . . . , x 0 ] [x_{7},z_{6},...,x_{0}] [x7,z6,...,x0],其他字节包含中间的位。
某些机器选择在内存中按照从最低有效字节到最高有效字节的顺序存储对象,而另一些机器则按照从最高有效字节到最低有效字节的顺序存储。前一种规则一一最低有效字节在最前面的方式,称为小端法(little endian),后一种规则——最高有效字节在最前面的方式,称为大端法(big endian)。
许多比较新的微处理器是 双端法(bi-endian) ,也就是说可以把它们配置成作为大端或者小端的机器运行。然而,实际情况是:一旦选择了特定操作系统,那么字节顺序也就固定下来。
表示字符串
C 语言中字符串被编码为一个以 null (其值为 0) 字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是 ASCII 字符码。
在使用 ASCII码作为字符码的任何系统上都将得到相同的结果,与字节顺序和字大小规则无关。因而,文本数据比二进制数据具有更强的平台独立性。
ASCII 字符集适合于编码英语文档,但是在表达一些特殊字符方面并没有太多办法。
基本编码,称为 Unicode 的“统一字符集”,使用 32 位来表示字符。这好像要求文本串中每个字符要占用 4 个字节。不过,可以有一些替代编码,常见的字符只需要 1个或 2 个字节,而不太常用的字符需要多一些的字节数。
特别地,UTF-8 表示将每个字符编码为一个字节序列,这样标准 ASCII 字符还是使用和它们在 ASCII 中一样的单字节编码,这也就意味着所有的 ASCII 字节序列用 ASCII 码表示和用 UTF-8 表示是一样的。
表示代码
不同的机器类型使用不同的且不兼容的指令和编码方式。即使是完全一样的进程,运行在不同的操作系统上也会有不同的编码规则,因此二进制代码是不兼容的。
二进制代码很少能在不同机器和操作系统组合之间移植。
布尔代数简介
将逻辑值 TRUE(真)和FALSE(假)编码为二进制值 1和0。
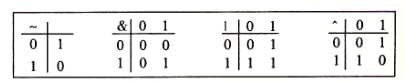
布尔代数的运算。二进制值 1 和 0 表示逻辑值TRUE或者 FALSE,而运算符~、&、| 和 ^ 分别表示逻辑运算 NOT 、AND、OR 和 EXCLUSIVE-OR。
C 语言中的位级运算
在布尔运算中使用的那些符号就是 C语言所使用的:| 就是 OR(或),& 就是 AND(与),~ 就是 NOT(取反),而 ^ 就是 EXCLUSIVE-OR(异或)。这些运算能运用到任何“整型”的数据类型上,

C 语言中的逻辑运算
C 语言提供了一组逻辑运算符||、&& 和 !,分别对应于命题逻辑中的 OR、AND和 NOT 运算。
逻辑运算很容易和位级运算相混淆,但是它们的功能是完全不同的。
逻辑运算认为所有非零的参数都表示 TRUE,而参数 0 表示 FALSE。它们返回 1 或者 0,分别表示结果为 TRUE 或者为 FALSE。
C 语言中的移位运算
C语言提供了一组移位运算,向左或者向右移动位模式。
对于一个位表示为 [ x w − 1 , x w − 2 , . . . , x 0 ] [x_{w-1},x_{w-2},...,x_0] [xw−1,xw−2,...,x0] 的操作数 x x x,C 表达式 x<<k 会生成一个值,其位表示为 [ x w − k − 1 , x w − k − 2 , . . . , x 0 , 0 , . . . , 0 ] [x_{w-k-1},x_{w-k-2},...,x_0,0,...,0] [xw−k−1,xw−k−2,...,x0,0,...,0]。也就是说, x x x 向左移动 k k k 位,丢弃最高的 k k k 位,并在右端补 k k k 个 0。移位量应该是一个 0 w − 1 0~ w-1 0 w−1之间的值。移位运算是从左至右可结合的,所以 x << j << k 等价于(x << j) << k。
有一个相应的右移运算 x>>k,
逻辑右移在左端补 k k k 个 0,得到的结果是 [ 0 , . . . , 0 , x w − 1 , x w − 2 , . . . , x k ] [0,...,0,x_{w-1},x_{w-2},...,x_k] [0,...,0,xw−1,xw−2,...,xk];
算术右移是在左端补个最高有效位的值,得到的结果是 [ x w − 1 , . . . , x w − 1 , x w − 1 , x w − 2 , . . . , x k ] [x_{w-1},...,x_{w-1},x_{w-1},x_{w-2},...,x_k] [xw−1,...,xw−1,xw−1,xw−2,...,xk]。

斜体的数字表示的是最右端(左移)或最左端(右移)填充的值。可以看到除了一个条目之外,其他的都包含填充 0。唯一的例外是算术右移[10010101]的情况。因为操作数的最高位是 1,填充的值就是 1。
C 语言标准并没有明确定义对于有符号数应该使用哪种类型的右移一一算术右移或者逻辑右移都可以。不幸地,这就意味着任何假设一种或者另一种右移形式的代码都可能会遇到可移植性问题。然而,实际上,几乎所有的编译器/机器组合都对有符号数使用算术右移,且许多程序员也都假设机器会使用这种右移。另一方面,对于无符号数,右移必须是逻辑的
整数表示
整数数据类型
C 语言支持多种整型数据类型一一表示有限范围的整数。
每种类型都能用关键字来指定大小,这些关键字包括 char、short、long,同时还可以指示被表示的数字是非负数(声明为 unsigned),或者可能是负数(默认)。为这些不同的大小分配的字节数根据程序编译为 32 位还是 64 位而有所不同。根据字节分配,不同的大小所能表示的值的范围是不同的。
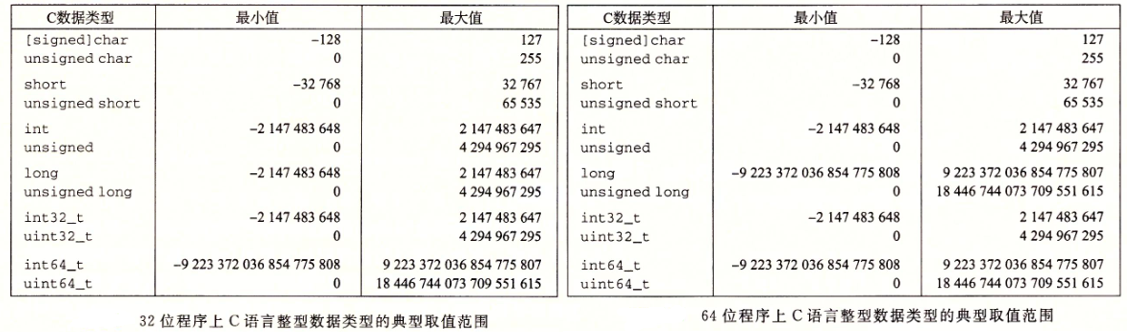 一个很值得注意的特点是取值范围不是对称的一一负数的范围比整数的范围大 1。当我们考虑如何表示负数的时候,会看到为什么会这样。
一个很值得注意的特点是取值范围不是对称的一一负数的范围比整数的范围大 1。当我们考虑如何表示负数的时候,会看到为什么会这样。
C 语言标准定义了每种数据类型必须能够表示的最小的取值范围。
C 语言的整型数据类型的保证的取值范围。C语言标准要求这些数据类型必须至少具有这样的取值范围。

无符号数的编码
假设有一个整数数据类型有 w w w 位。我们可以将位向量写成 x ⃗ \vec x x,表示整个向量,或者写 [ x w − 1 , x w − 2 , . . . , x 0 ] [x_{w-1},x_{w-2},...,x_0] [xw−1,xw−2,...,x0],表示向量中的每一位。把 x ⃗ \vec x x 看做一个二进制表示的数,就获得成 x ⃗ \vec x x 的无符号表示。
在这个编码中,每个位 x i x_i xi 都取值为 0 或 1,后一种取值意味着数值 2 i 2^i 2i 应为数字值的一部分。
用一个函数 B2U w \text{B2U}_w B2Uw(Binary to Unsigned 的缩写,长度为 w w w)来表示:
对向量 x ⃗ = [ x w − 1 , x w − 2 , . . . , x 0 ] \vec x =[x_{w-1},x_{w-2},...,x_0] x=[xw−1,xw−2,...,x0]: B2U w ( x ⃗ ) = ∑ i = 0 w − 1 x i 2 i \text{B2U}_w(\vec x) = \sum_{i=0}^{w-1} x_i 2^i B2Uw(x)=∑i=0w−1xi2i
函数 B2U w \text{B2U}_w B2Uw 将一个长度为 w w w 的 0 0 0、 1 1 1 串映射到非负整数。
例如,$ B2U 4 ( [ 1011 ] ) = 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 ] 8 + 0 + 2 + 1 = 11 \text{B2U}_4([1011])=1 \cdot 2^3 + 0 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 ] 8 + 0 +2 + 1 =11 B2U4([1011])=1⋅23+0⋅22+1⋅21+1⋅20]8+0+2+1=11
无符号数的二进制表示有一个很重要的属性,也就是每个介于 0 2 w − 1 0~2^w - 1 0 2w−1 之间的数都有唯一一个 w w w 位的值编码。例如,十进制值 11 作为无符号数,只有一个 4 位的表示,即[1011].
函数 B2U w \text{B2U}_w B2Uw 是一个双射。
补码编码
对于许多应用,希望表示负数值。最常见的有符号数的计算机表示方式就是补码(two’s-complement)形式。在这个定义中,将字的最高有效位解释为负权(negativeweight)。
用函数 B2T w \text{B2T}_w B2Tw (Binary to Two’s-complement 的缩写,长度为 w w w 来表示:
对向量 x ⃗ = [ x w − 1 , x w − 2 , . . . , x 0 ] \vec x =[x_{w-1},x_{w-2},...,x_0] x=[xw−1,xw−2,...,x0]: B2T w = − x w − 1 2 w − 1 + ∑ i = 0 w − 2 x i 2 i \text{B2T}_w = -x_{w-1}2^{w-1}+\sum_{i=0}^{w-2}x_i 2^i B2Tw=−xw−12w−1+∑i=0w−2xi2i
最高有效位 x w − 1 x_{w-1} xw−1 也称为符号位,它的“权重”为 − 2 w − 1 -2^{w-1} −2w−1,是无符号表示中权重的负数。符号位被设置为 1 1 1 时,表示值为负,而当设置为 0 0 0 时,值为非负。
例如: B2T 4 ( [ 1011 ] = − 1 ⋅ 2 3 + 0 ⋅ 2 2 + 1 ⋅ 2 1 + 1 ⋅ 2 0 = − 8 + 0 + 2 + 1 = − 5 \text{B2T}_4([1011]=-1 \cdot 2^3+ 0 \cdot 2^2 + 1 \cdot 2^1 + 1 \cdot 2^0 =-8 + 0 + 2 + 1 = -5 B2T4([1011]=−1⋅23+0⋅22+1⋅21+1⋅20=−8+0+2+1=−5
B2T w \text{B2T}_w B2Tw 是一个从长度为 w w w 的位模式到 TMin w \text{TMin}_w TMinw 和 TMax w \text{TMax}_w TMaxw之间数字的映射,写作 B2T w : { 0 , 1 } → ( TMin w , . . . , TMax w \text {B2T}_w: \space \{0,1\} \to ( \text{TMin}_w,...,\text{TMax}_w B2Tw: {0,1}→(TMinw,...,TMaxw。同无符号表示一样,在可表示的取值范围内的每个数字都有一个唯一的 w w w 位的补码编码。
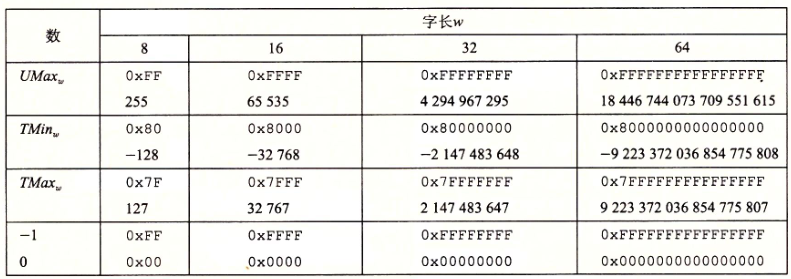 从图中可知:
从图中可知:
1.补码的范围是不对称的: ∣ TMin w ∣ = ∣ TMax w ∣ + 1 |\text{TMin}_w| = |\text{TMax}_w| +1 ∣TMinw∣=∣TMaxw∣+1,也就是说,TMin 没有与之对应的正数。是因为一半的位模式(符号位设置为 1的数)表示负数,而另一半(符号位设置为0的数)表示非负数。因为 0 是非负数,也就意味着能表示的整数比负数少一个。
2.最大的无符号数值刚好比补码的最大值的两倍大一点: UMax w = 2 TMax w 十 1 \text{UMax}_w=2 \text{TMax}_w 十1 UMaxw=2TMaxw十1。补码表示中所有表示负数的位模式在无符号表示中都变成了正数。注意-1和 UMax 有同样的位表示——一个全1的串。数值 0在两种表示方式中都是全 0 的串。
有符号数的其他表示方法
反码
除了最好有效位的权是 − ( w w − 1 − 1 ) -(w^{w-1}-1) −(ww−1−1) 而不是 − 2 w − 1 -2^{w-1} −2w−1,它和补码是一样的:
B2O w ( x ⃗ ) = − x w − 1 ( 2 w − 1 − 1 ) + ∑ i = 0 w − 2 x i 2 i \text{B2O}_w(\vec x) = -x_{w-1}(2^{w-1} -1)+\sum_{i=0}^{w-2}x_i 2^i B2Ow(x)=−xw−1(2w−1−1)+i=0∑w−2xi2i
原码
最高有效位是符号位,用来确定剩下的位应该取负权还是正权:
B2S w ( x ⃗ ) = ( − 1 ) x w − 1 ⋅ ( ∑ i = 0 w − 2 x i 2 i ) \text{B2S}_w(\vec x) = (-1)^{x_{w-1}} {\cdot (\sum_{i=0}^{w-2}x_i 2^i)} B2Sw(x)=(−1)xw−1⋅(i=0∑w−2xi2i)
有符号数与无符号数之间的转换
C 语言允许在各种不同的数字数据类型之间做强制类型转换。例如,假设变量 x 声明为int,u声明为 unsigned。表达式(unsigned)x 会将x的值转换成一个无符号数值,而(int)u将 u 的值转换成一个有符号整数。
考虑无符号与补码表示之间互相转换的结果。
对于在范围 0 < x < T M a x w 0<x<TMax_w 0<x<TMaxw之内的值而言,得到 T 2 U w ( x ) = x T2U_w(x)=x T2Uw(x)=x 和 U 2 T w ( x ) = x U2T_w(x)=x U2Tw(x)=x。也就是说,在这个范围内的数字有相同的无符号和补码表示。
对于这个范围以外的数值,转换需要加上或者减去 2 w 2^w 2w。
扩展一个数字的位表示
一个常见的运算是在不同字长的整数之间转换,同时又保持数值不变。当然,当目标数据类型太小以至于不能表示想要的值时,这根本就是不可能的。然而,从一个较小的数据类型转换到一个较大的类型,总是可能的。
要将一个无符号数转换为一个更大的数据类型,只要简单地在表示的开头添加0这种运算被称为零扩展(zero extension)。
要将一个补码数字转换为一个更大的数据类型,可以执行一个 符号扩展(sign extension) ,在表示中添加最高有效位的值。
截断数字
假设不用额外的位来扩展一个数值,而是减少表示一个数字的位数。
当将一个 w w w 位的数 x ⃗ = [ x w − 1 , x w − 2 , ⋅ ⋅ ⋅ , x 0 ] \vec x=[x_{w-1},x_{w-2},···,x_0] x=[xw−1,xw−2,⋅⋅⋅,x0] 截断为一个 k k k 位数字时,会丢弃高 w − k w-k w−k 位,得到一个位向量 x ⃗ = [ x k − 1 , x k − 2 , . . . , x 0 ] \vec x=[x_{k-1},x_{k-2},...,x_0] x=[xk−1,xk−2,...,x0]。截断一个数字可能会改变它的值——溢出的一种形式。对于一个无符号数,可以很容易得出其数值结果。
整数运算
无符号加法
说一个算术运算溢出,是指完整的整数结果不能放到数据类型的字长限制中去。
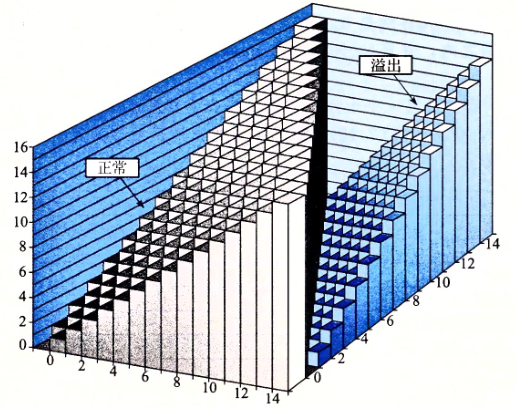
当两个运算数的和为 2 w 2^w 2w 或者更大时,就发生了溢出。上图展示了字长 w = 4 w=4 w=4 的无符号加法函数的坐标图。这个和是按模 2 4 = 16 2^4=16 24=16 计算的。当 x + y < 16 x+y<16 x+y<16 时,没有溢出,并且 x + u 4 y x+ _u^4y x+u4y 就是 x 十 y x十y x十y。这对应于图中标记为“正常”的斜面。当 x 十 y > 16 x十y>16 x十y>16 时,加法溢出,结果相当于从和中减去 16 16 16。这对应于图中标记为“溢出”的斜面。
当执行 C 程序时,不会将溢出作为错误而发信号。不过有的时候,我们可能希望判定是否发生了溢出。
补码加法
对于补码加法,必须确定当结果太大(为正)或者太小(为负)时,应该做些什么。
首先,将两个加数的补码表示对齐,将它们的最高位对齐。然后,从最低位开始,一位一位地相加。
如果相加的结果超过了该位的表示范围(即进位),则将进位部分加到下一位的运算中。
最后,得到的结果就是两个加数的补码表示的和。

无符号乘法
范围在 0 ≤ x 0≤x 0≤x, y ≤ 2 w − 1 y≤2^w-1 y≤2w−1 内的整数 x x x 和 y y y 可以被表示为 w w w 位的无符号数,但是它们的乘积 x ⋅ y x· y x⋅y 的取值范围为 0 0 0 到 ( 2 w − 1 ) 2 = 2 2 w − 2 w + 1 + 1 (2^w - 1)^2 =2^{2w}-2^{w+1}+1 (2w−1)2=22w−2w+1+1 之间。这可能需要 2 w 2w 2w 位来表示。
不过,C语言中的无符号乘法被定义为产生 w w w 位的值,就是 2 w 2w 2w 位的整数乘积的低 w w w 位表示的值。我们将这个值表示为 α ∗ w u y α * _w^uy α∗wuy 。
乘以常数
设 x x x 为位模式 [ x w − 1 , x w − 2 , … , x 0 ] [x_{w-1},x_{w-2},…,x_0] [xw−1,xw−2,…,x0] 表示的无符号整数。那么,对于任何 k ≥ 0 k≥0 k≥0,都认为 [ x w − 1 , x w − 2 , … , x 0 , 0 , … , 0 ] [x_{w-1},x_{w-2},…,x_0,0,…,0] [xw−1,xw−2,…,x0,0,…,0] 给出了 x 2 k x2^k x2k 的 w + k w+k w+k 位的无符号表示,这里右边增加了 k k k 个 0。
因此,比如,当 w = 4 w=4 w=4 时, 11 11 11可以被表示为 [ 1011 ] [1011] [1011]。 k = 2 k=2 k=2 时将其左移得到 6 6 6 位向量 [ 101100 ] [101100] [101100],即可编码为无符号数 11 ⋅ 4 = 44 11·4=44 11⋅4=44。
可以看出左移一个数值等价于执行一个与 2 的幂相乘的无符号乘法。
除以 2 的幂
除以⒉的幂也可以用移位运算来实现,只不过我们用的是右移。
无符号和补码数分别使用逻辑移位和算术移位来达到目的。
设 x x x 为位模式 [ x w − 1 , x w − 2 , … , x 0 ] [x_{w-1},x_{w-2},…,x_0] [xw−1,xw−2,…,x0] 表示的无符号整数,而 k k k 的取值范围为 0 ≤ k < w 0≤k<w 0≤k<w。设 x ′ x^{'} x′为 w − k w-k w−k 位位表示 [ x w − 1 , x w − 2 , … , x k ] [x_{w-1},x_{w-2},…,x_k] [xw−1,xw−2,…,xk] 的无符号数,而 x " x^{"} x" 为 k k k 位位表示 [ x k − 1 , … , x 0 ] [x_{k-1},…,x_0] [xk−1,…,x0] 的无符号数。由此,我们可以看到 x = 2 k x ′ 十 x " x=2^kx^{'}十x^{"} x=2kx′十x",而 0 ≤ x " < 2 k 0≤x^{"}<2^k 0≤x"<2k。因此,可得 x / 2 k x/2^k x/2k 向上取整等于 x ′ x^{'} x′。
对位向量 [ x w − 1 , x w − 2 , … , x 0 ] [x_{w-1},x_{w-2},…,x_0] [xw−1,xw−2,…,x0] 逻辑右移 k k k 位会得到位向量 [ 0 , … , 0 , x w − 1 , x w − 2 , … , x k ] [0,…,0,x_{w-1},x_{w-2},…,x_k] [0,…,0,xw−1,xw−2,…,xk],这个位向量有数值 x ′ x^{'} x′,可以看到,该数值可通过计算 x>>k 得到。
浮点数
二进制小数
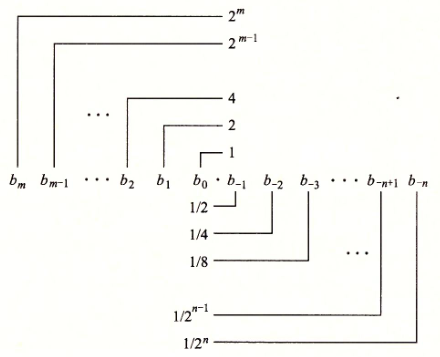
十进制表示法使用如下形式的表示:
d m d m − 1 . . . d 1 d 0 d − 1 d − 2 . . . d − n d_{m}d_{m-1}...d_{1}d_{0}d_{-1}d_{-2}...d_{-n} dmdm−1...d1d0d−1d−2...d−n
其中每个十进制数 d i d_i di 的取值范围是 0 9 0~9 0 9。这个表达描述的数值 d d d 定义为:
d = ∑ i = − n n 1 0 i × d i d=\sum_{i=-n}^{n}10^{i} \times d_i d=i=−n∑n10i×di
数字权的定义与十进制小数点符号(“ . . .’)相关,这意味着小数点左边的数字的权是 10 的正幂,得到整数值,而小数点右边的数字的权是 10 的负幂,得到小数值。
二进制数字表述为:
b = ∑ i = − n m 2 i × b i b=\sum_{i=-n}^{m}2^{i}\times b_{i} b=i=−n∑m2i×bi
符号.现在变为了二进制的点,点左边的位的权是 2 的正幂,点右边的位的权是 2 的负幂。
IEEE 浮点表示
IEEE 浮点标准用 V = ( − 1 ) s × M × 2 E V=(-1)^{s}\times M \times 2^{E} V=(−1)s×M×2E 的形式来表示一个数:
符号(sign) s 决定这数是负数(s=1)还是正数(s=0),而对于数值 0 的符号位解释作为特殊情况处理。
尾数(significand) M 是一个二进制小数,它的范围是 1~2,或者是 0~1。
阶码(exponent) E 的作用是对浮点数加权,这个权重是 2的 E次幂(可能是负数)。将浮点数的位表示划分为三个字段,分别对这些值进行编码:
一个单独的符号位 s 直接编码符号 s;
k 位的阶码字段 e x p = e k − 1 ⋅ ⋅ ⋅ e 1 e 0 exp=e_{k-1}···e_1e_0 exp=ek−1⋅⋅⋅e1e0 编码阶码 E;
n 位小数字段 f r a c = f 1 f 0 frac=f_1f_0 frac=f1f0 编码尾数 M,但是编码出来的值也依赖于阶码字段的值是否等于 0。
浮点运算
IEEE 标准指定了一个简单的规则,来确定诸如加法和乘法这样的算术运算的结果把浮点值z 和y 看成实数,而某个运算 ⊙ \odot ⊙定义在实数上,计算将产生 R o u n d ( x ⊙ y ) Round(x\odot y) Round(x⊙y) ,这是对实际运算的精确结果进行舍入后的结果。在实际中,浮点单元的设计者使用一些聪明的小技巧来避免执行这种精确的计算,因为计算只要精确到能够保证得到一个正确的舍人结果就可以了。当参数中有一个是特殊值(如-0、 − ∞ -\infty −∞或 NaN)时,IEEE 标准定义了一些使之更合理的规则。例如,定义 1/一0将产生 − ∞ -\infty −∞,而定义 1 / + 0 1/+0 1/+0 会产生 + ∞ +\infty +∞。
IEEE 标准中指定浮点运算行为方法的一个优势在于,它可以独立于任何具体的硬件或者软件实现。因此,我们可以检查它的抽象数学属性,而不必考虑它实际上是如何实现的。
…
深入理解计算机系统(第三版)学习笔记