项目简介
YAYI 2 是中科闻歌研发的新一代开源大语言模型,中文名:雅意,采用了超过 2 万亿 Tokens 的高质量、多语言语料进行预训练。

开源地址:https://github.com/wenge-research/YAYI2
YAYI2-30B是其模型规模,是基于 Transformer 的大语言模型。拥有300亿参数规模,基于国产化算力支持,数据语料安全可控,模型架构全自主研发。在媒体宣传、舆情感知、政务治理、金融分析等场景具有强大的应用能力。具有语种覆盖多、垂直领域深、开源开放的特点。
中科闻歌 此次开源计划是希望促进中文预训练大模型开源社区的发展,并积极为此做出贡献,共同构建雅意大模型生态。

预训练数据
雅意2.0 在预训练阶段,采用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。
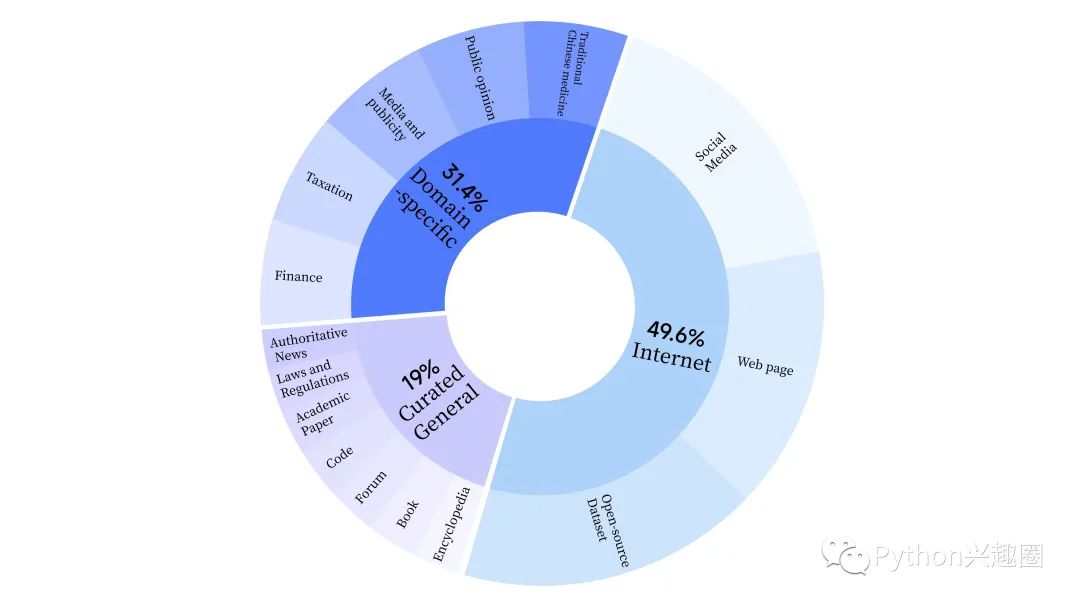
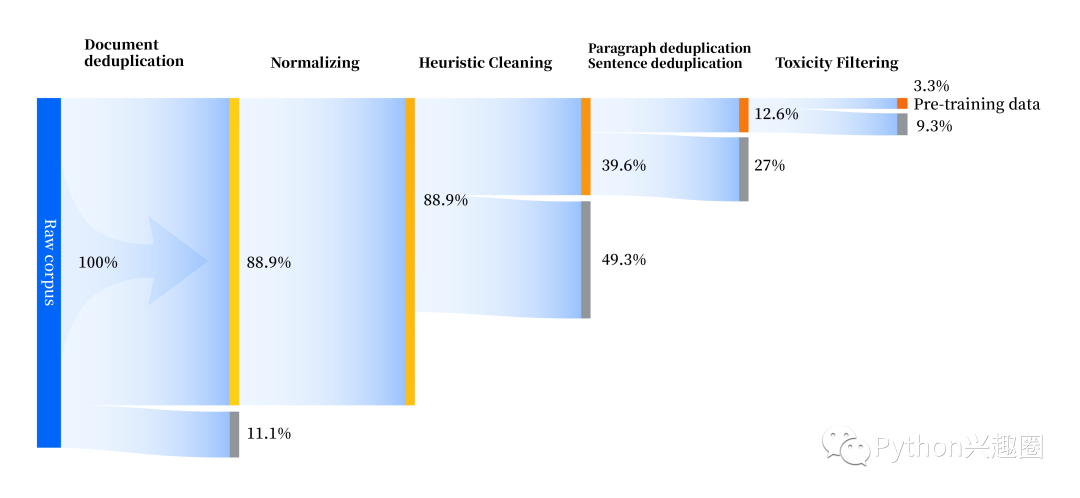
同时其还构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。共收集 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。
分词器
-
YAYI 2 采用 Byte-Pair Encoding(BPE)作为分词算法,使用 500GB 高质量多语种语料进行训练,包括汉语、英语、法语、俄语等十余种常用语言,词表大小为 81920。
-
对数字进行逐位拆分,以便进行数学相关推理;同时,在词表中手动添加了大量HTML标识符和常见标点符号,以提高分词的准确性。同时还预设了200个保留位,以便未来可能的应用。
-
采样了单条长度为 1万 Tokens 的数据形成评价数据集,涵盖中文、英文和一些常见小语种,并计算了模型的压缩比。

-
压缩比越低通常表示分词器具有更高效率的性能。
环境安装
1、克隆本仓库内容到本地环境
git clone https://github.com/wenge-research/YAYI2.git cd YAYI2
2、创建 conda 虚拟环境
conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_env
本项目需要 Python 3.8 或更高版本。
3、安装依赖
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
4、模型推理
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("wenge-research/yayi2-30b", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("wenge-research/yayi2-30b", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('The winter in Beijing is', return_tensors='pt')
>>> inputs = inputs.to('cuda')
>>> pred = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, do_sample=True,repetition_penalty=1.2,temperature=0.4, top_k=100, top_p=0.8)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
总结
雅意大模型 应用于多个垂直领域行业,如政务、舆情、财税、教育、中医药、金融等都有它的身影。同时也衍生出了一系列家族AI产品,比如企业级AI助手、数据标注平台、知识库AI助手、绘画创作平台、AI机器人等。


相信国产模型的生态开源开放,能对多语种、多领域、多行业的应用场景提供一大助力。