文章目录
- 1、数据准备
- 2、限制结果
- 3、完全限定名
- 4、排序检索
所谓数据检索,就是前面所讲的”增删改查“的”查“。
注:本文使用的“行”指数据表中的“记录”,“列”指数据表中的“字段”。
在第四节《表的增删改查》中已经介绍了 select 查询记录的几种使用方法:查询所有行的所有列、查询指定行的所有列、查询所有行的指定列和查询指定行的指定列。本文介绍一些数据检索的其他高级使用方法。
1、数据准备
首先准备文需要的数据,如下图所示:
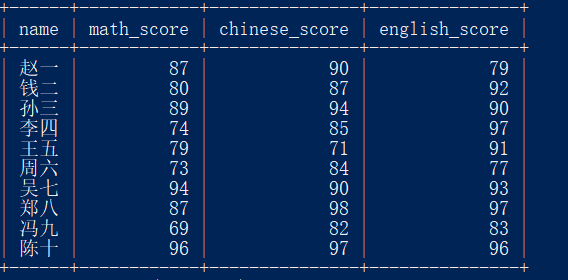
使用如下语句进行数据库的创建、表的创建及记录的插入:
mysql> create database scoredb;
Query OK, 1 row affected (0.08 sec)mysql> use scoredb;
Database changedmysql> CREATE TABLE score(-> name VARCHAR(4) NOT NULL DEFAULT '',-> math_score TINYINT NOT NULL DEFAULT 0,-> chinese_score TINYINT NOT NULL DEFAULT 0,-> english_score TINYINT NOT NULL DEFAULT 0-> )engine myisam charset utf8;
Query OK, 0 rows affected, 1 warning (0.08 sec)mysql> INSERT INTO score VALUES -> ('赵一', 87, 90, 79),-> ('钱二', 80, 87, 92),-> ('孙三', 89, 94, 90),-> ('李四', 74, 85, 97),-> ('王五', 79, 71, 91),-> ('周六', 73, 84, 77),-> ('吴七', 94, 90, 93),-> ('郑八', 87, 98, 97),-> ('冯九', 69, 82, 83),-> ('陈十', 96, 97, 96);
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
2、限制结果
SELECT 语句返回所有的匹配行,它们可能是指定表中的每个行。如果想要SELECT 语句返回指定的行数,可以使用LIMIT 子句。 LIMIT 接受一个或两个数字的参数,参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
LIMIT 三种语法,第二种和第三种语法完全等价:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows];
SELECT column1, column2, columnN
FROM table_name
LIMIT [row num] [no of rows];
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num];
注:
- 初始记录行的偏移量为 0 。
示例1,检索前3条记录:
mysql> SELECT name FROM score LIMIT 3;
+------+
| name |
+------+
| 赵一 |
| 钱二 |
| 孙三 |
+------+
3 rows in set (0.00 sec)
示例2,检索从偏移量为5的记录开始后3条记录:
mysql> SELECT name FROM score LIMIT 5, 3;
+------+
| name |
+------+
| 周六 |
| 吴七 |
| 郑八 |
+------+
3 rows in set (0.00 sec)
也可以使用下面这种语法:
mysql> SELECT name FROM score LIMIT 3 OFFSET 5;
+------+
| name |
+------+
| 周六 |
| 吴七 |
| 郑八 |
+------+
3 rows in set (0.00 sec)
在行数不够时,LIMIT 中指定要检索的行数为检索的最大行数。比如我们从第8条记录开始取5条记录,那么我们只能取到3条记录:
mysql> SELECT name FROM score LIMIT 5 OFFSET 7;
+------+
| name |
+------+
| 郑八 |
| 冯九 |
| 陈十 |
+------+
3 rows in set (0.01 sec)
3、完全限定名
假如两个表中有相同的字段,而我们恰好要查询其中一个表中的该字段,那么就会出现二义性:到底要取哪个表中的该字段?为了解决这一问题,可以使用完全限定的名字来引用列,完全限定字段的格式为table_name.column_name,例如:
mysql> SELECT score.name FROM score;
+------+
| name |
+------+
| 赵一 |
| 钱二 |
| 孙三 |
| 李四 |
| 王五 |
| 周六 |
| 吴七 |
| 郑八 |
| 冯九 |
| 陈十 |
+------+
10 rows in set (0.01 sec)
表名也是可以被限制的,其格式为database_name.table_name,例如:
mysql> SELECT score.name FROM scoredb.score;
+------+
| name |
+------+
| 赵一 |
| 钱二 |
| 孙三 |
| 李四 |
| 王五 |
| 周六 |
| 吴七 |
| 郑八 |
| 冯九 |
| 陈十 |
+------+
10 rows in set (0.00 sec)
4、排序检索
有时候数据并不是一定要按照数据库中的存储顺序进行显示,比如我们想要以商品价格进行排序或者以成绩排名进行显示。
如果我们需要对读取的数据进行排序,可以使用 MySQL 的 ORDER BY 子句来设定想按哪个字段哪种方式来进行排序,再返回搜索结果。其语法为:
SELECT field1, field2,...fieldN table_name1, table_name2...
ORDER BY field1, [field2...] [ASC [DESC]]
- 可以使用任何字段来作为排序的条件,从而返回排序后的查询结果。
- 可以设定多个字段来排序。
- 可以使用 ASC 或 DESC 关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。
- 可以添加 WHERE…LIKE 子句来设置条件。
以数学成绩升序方式检索,可以使用如下命令:
mysql> SELECT name, math_score FROM score ORDER BY math_score;
+------+------------+
| name | math_score |
+------+------------+
| 冯九 | 69 |
| 周六 | 73 |
| 李四 | 74 |
| 王五 | 79 |
| 钱二 | 80 |
| 赵一 | 87 |
| 郑八 | 87 |
| 孙三 | 89 |
| 吴七 | 94 |
| 陈十 | 96 |
+------+------------+
10 rows in set (0.00 sec)
以数学成绩降序方式检索,可以使用如下命令:
mysql> SELECT name, math_score FROM score ORDER BY math_score DESC;
+------+------------+
| name | math_score |
+------+------------+
| 陈十 | 96 |
| 吴七 | 94 |
| 孙三 | 89 |
| 赵一 | 87 |
| 郑八 | 87 |
| 钱二 | 80 |
| 王五 | 79 |
| 李四 | 74 |
| 周六 | 73 |
| 冯九 | 69 |
+------+------------+
10 rows in set (0.00 sec)
以数学成绩升序、语文成绩降序和英语成绩降序 3 个字段同时检索:
mysql> SELECT name, math_score, chinese_score, english_score FROM score ORDER BY-> math_score, chinese_score DESC, english_score DESC;
+------+------------+---------------+---------------+
| name | math_score | chinese_score | english_score |
+------+------------+---------------+---------------+
| 冯九 | 69 | 82 | 83 |
| 周六 | 73 | 84 | 77 |
| 李四 | 74 | 85 | 97 |
| 王五 | 79 | 71 | 91 |
| 钱二 | 80 | 87 | 92 |
| 郑八 | 87 | 98 | 97 |
| 赵一 | 87 | 90 | 79 |
| 孙三 | 89 | 94 | 90 |
| 吴七 | 94 | 90 | 93 |
| 陈十 | 96 | 97 | 96 |
+------+------------+---------------+---------------+
10 rows in set (0.00 sec)
利用排序检索与 LIMIT 组合,可以取出某字段的最低或最高记录。
mysql> SELECT name, english_score FROM score ORDER BY english_score LIMIT 1;
+------+---------------+
| name | english_score |
+------+---------------+
| 周六 | 77 |
+------+---------------+
1 row in set (0.00 sec)mysql> SELECT name, english_score FROM score ORDER BY english_score DESC LIMIT 1;
+------+---------------+
| name | english_score |
+------+---------------+
| 李四 | 97 |
+------+---------------+
1 row in set (0.00 sec)