文章目录
- 1.累加器实现原理
- 2.自定义累加器
- 3.广播变量
1.累加器实现原理
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
//建立与Spark框架的连接val wordCount = new SparkConf().setMaster("local").setAppName("WordCount") //配置文件val context = new SparkContext(wordCount) //读取配置文件val dataRdd: RDD[Int] = context.makeRDD(List(1, 2, 3, 4),2)var sum=0dataRdd.foreach(num=>sum+=num)println(sum)context.stop()
运行结果:
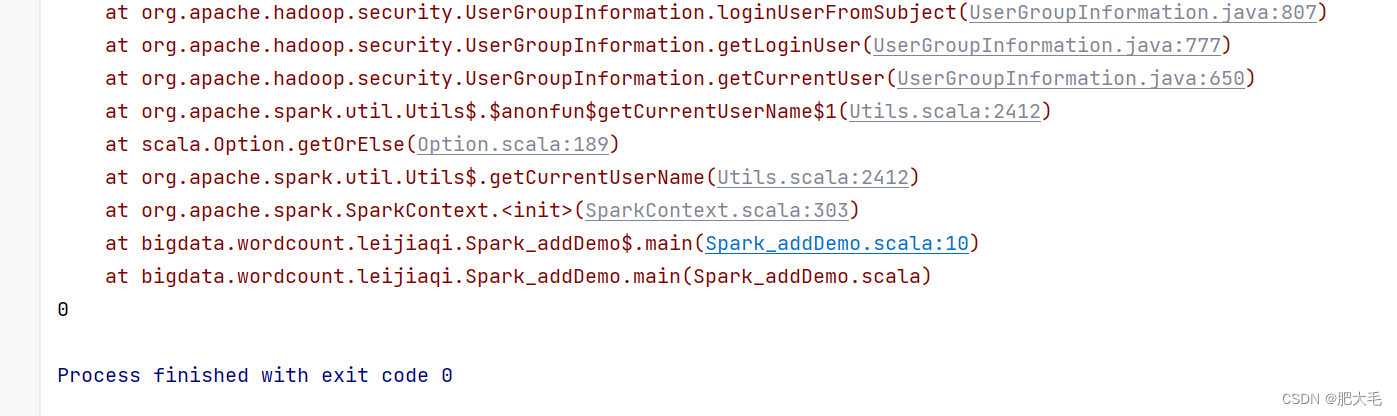
我们预期是想要实现数据的累加,开始数据从Driver被传输到了Executor中进行计算,但是每个分区在累加数据完成之后并没有将计算结果返回到Driver端,所以导致最后的结果与预期的不一致。
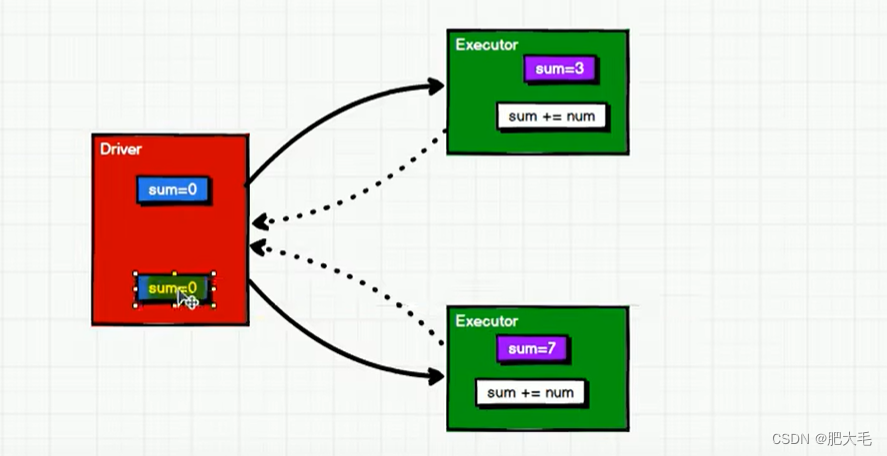
对上述代码使用累加器
val dataRdd: RDD[Int] = context.makeRDD(List(1, 2, 3, 4))val sum = context.longAccumulator("sum")dataRdd.foreach(num=>{//使用累加器sum.add(num)})//获取累加器的值println(sum.value)
运行结果:

由此可见,在使用了累加器之后,每个Executor在开始都会获得这个累加器变量,每个Executor在执行完成后,累加器会将每个Executor中累加器变量的值聚合到Driver端。
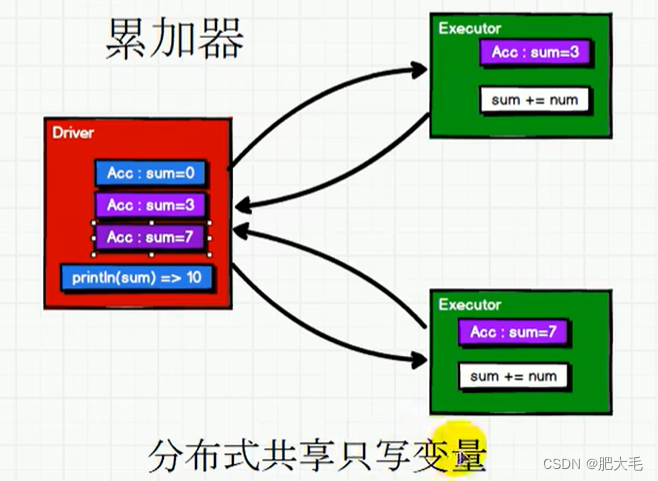
Spark提供了多种类型的累加器,以下是其中的一些:
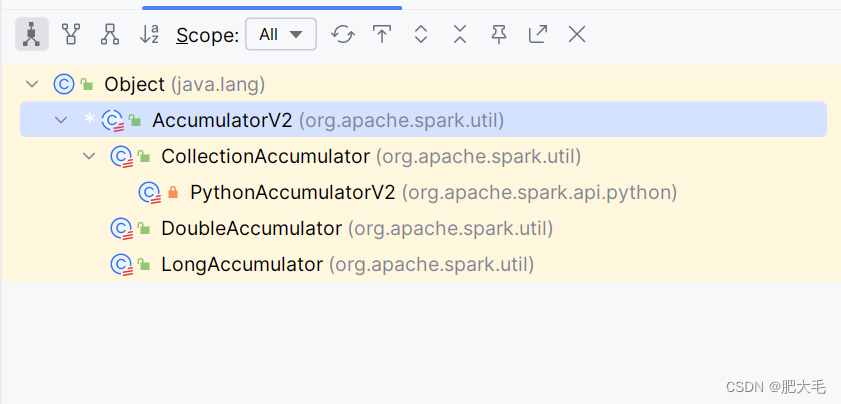
2.自定义累加器
用户可以通过继承AccumulatorV2来自定义累加器。需求:自定义累加器实现WordCount案例。
AccumulatorV2[IN,OUT]中:
IN:输入数据的类型
OUT:输出数据类型
WordCount案例实现完整代码:
package bigdata.wordcount.leijiaqiimport bigdata.wordcount.leijiaqi
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}import scala.collection.mutable/*** 使用累加器完成WordCount案例*/
object Spark_addDemo {def main(args: Array[String]): Unit = {//建立与Spark框架的连接val wordCount = new SparkConf().setMaster("local").setAppName("WordCount") //配置文件val context = new SparkContext(wordCount) //读取配置文件val dataRDD: RDD[String] = context.textFile("D:\\learnSoftWare\\IdeaProject\\Spark_Demo\\Spark_Core\\src\\main\\com.mao\\datas\\1.txt")//创建累加器对象val wordCountAccumulator = new WordCountAccumulator//向Spark中进行注册context.register(wordCountAccumulator,"wordCountAccumulator")//实现累加dataRDD.foreach(word => {wordCountAccumulator.add(word)})//获取累加结果,打印在控制台上println(wordCountAccumulator.value)//关闭链接context.stop()}}class WordCountAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]
{//定义一个map用于存储累加后的结果var map: mutable.Map[String, Long] =mutable.Map[String,Long]()//累加器是否为初始状态override def isZero: Boolean = {map.isEmpty}//复制累加器override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {new WordCountAccumulator()}//重置累加器override def reset(): Unit = {map.clear()}//向累加器添加数据INoverride def add(word: String): Unit = {// 查询 map 中是否存在相同的单词// 如果有相同的单词,那么单词的数量加 1// 如果没有相同的单词,那么在 map 中增加这个单词val newValue = map.getOrElse(word, 0L) + 1map.update(word,newValue)}//合并累加器override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {var map1=this.mapvar map2=other.value//合并两个mapmap2.foreach({case (word,count)=>{val newValue = map1.getOrElse(word,0L)+countmap1.update(word,newValue)}})}//返回累加器的结果(OUT)override def value: mutable.Map[String, Long] = this.map
}
}运行结果:

3.广播变量
在Apache Spark中,广播变量(Broadcast Variables)是一种特殊类型的变量,用于优化数据共享。当Spark应用程序在集群中的多个节点上运行时,每个节点都需要访问相同的数据集。如果数据集很大,那么将这些数据发送到每个节点可能会非常耗时和低效。 广播变量提供了一种方法,可以在集群中的所有节点上共享数据集的一个只读副本 ,从而避免了在每个节点上重复发送数据。
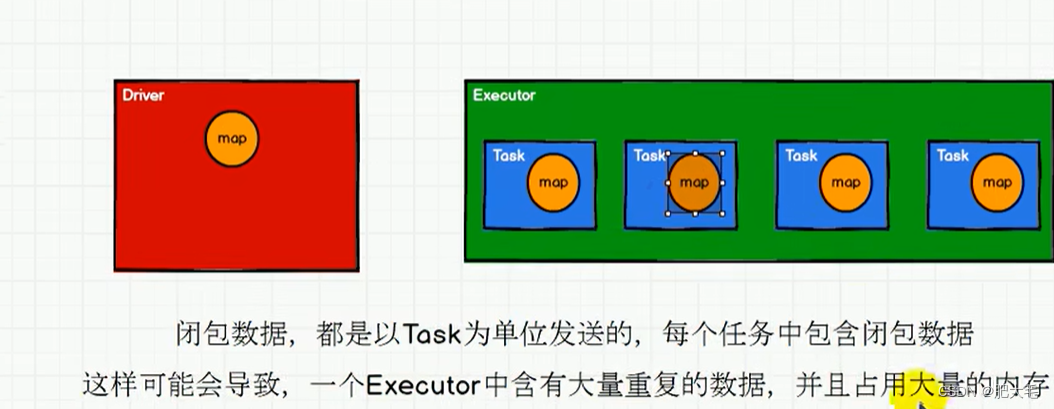
广播变量也叫分布式只读变量,它可以将闭包数据发送到每个Executor的内存中来达到共享的目的,Executor其实就相当于一个JVM,在启动的时候会自动分配内存。
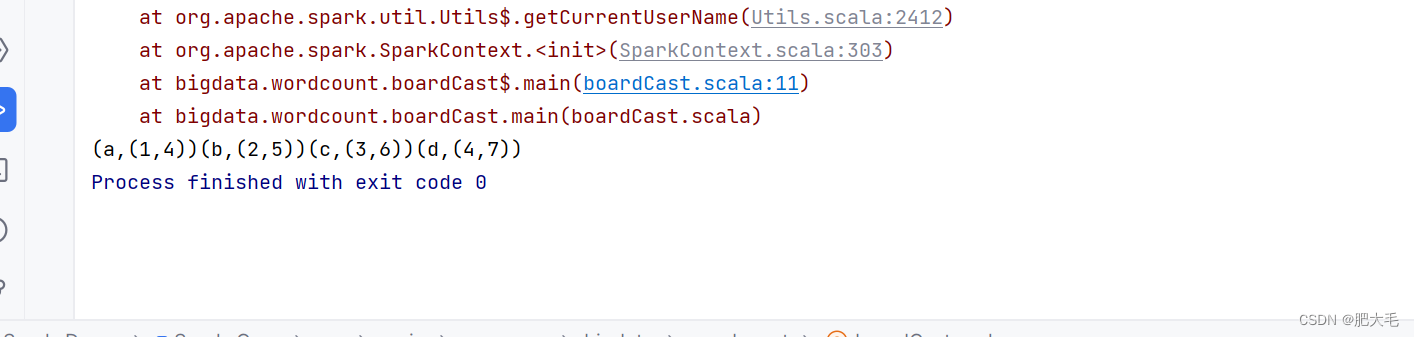
//建立与Spark框架的连接val wordCount = new SparkConf().setMaster("local").setAppName("WordCount") //配置文件val context = new SparkContext(wordCount) //读取配置文件val rdd1 = context.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("d", 4)), 4)val list = List(("a", 4), ("b", 5), ("c", 6), ("d", 7))// 声明广播变量val broadcast: Broadcast[List[(String, Int)]] = context.broadcast(list)val resultRDD: RDD[(String, (Int, Int))] = rdd1.map {case (key, num) => {var num2 = 0// 使用广播变量for ((k, v) <- broadcast.value) {if (k == key) {num2 = v}}(key, (num, num2))}}resultRDD.collect().foreach(print)context.stop()