目录
一、MongoDB
1.1、简介
a)MongoDB 是什么?为什么要使用 MongoDB?
b)应用场景
c)MongoDB 这么强大,是不是可以直接代替 MySQL ?
d)MongoDB 中的一些概念
e)Docker 下载
1.2、库操作
tips看前须知
a)查看所有库
b)创建并使用数据库
c)查看当前操作的数据库
d)删除数据库
1.3、集合操作
a)创建集合
b)查看库中所有集合
c)删除集合
1.4、文档操作
1.4.1、插入文档
1.4.2、删除文档
1.4.3、更新文档
1.4.4、查询文档
a)基本查询
b)类比 MySQL 的 where name = 'cyk'
c)类比 MySQL 的 where _id < 5
d)类比 MySQL 的 where _id <= 5
e)类比 MySQL 的 where _id > 5
f)类比 MySQL 的 where _id >= 5
g)类比 MySQL 的 where age != 5
h)AND 连接
i)OR 连接
j)AND 和 OR 联合
k)数组中查询
l)模糊查询
m)排序
n)分页
o)分页
p)去重
q)返回指定字段
1.5、$type
一、MongoDB
1.1、简介
a)MongoDB 是什么?为什么要使用 MongoDB?
MongoDB 是一个基于 分布式文件存储的数据库。由 C++ 编写,就是为 Web应用提供可拓展 + 高性能数据存储解决方案.
MongDB 是一个介于关系数据库和非关系数据库之间的产品. 他支持的数据结构非常松散,类似 json 的 bson 格式,因此可以存储比较复杂的数类型. Mongo 最大的特点就是他的查询非常强大,语法类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分的功能,并且还支持对数据建立索引.
b)应用场景
- 游戏应用:使用 MongoDB 来存储用户的 装备、积分等直接以内嵌文档的形式存储,方便查询和更新.
- 物流数据:订单状态会在运送过程中不断更新,因此使用 MongoDB 以数组形式来存储订单信息,一次查询就能将订单所有变更读取出来
- 社交应用:使用 MongoDB 来存储用户信息和朋友圈信息,通过地理位置所有实现附近的人、地点等功能。并且非常适合存储聊天记录,因为他提供了非常丰富的查询,再写入和读取方面都相对 MySQL 都更快.
- 视频直播:使用 MongoDB 存储用户信息、礼物信息等.
- 大数据应用:使用 MongoDB 作为大数据的云存储系统,随时进行数据提取和分析,掌握行业动态.
c)MongoDB 这么强大,是不是可以直接代替 MySQL ?
这个当然不可以的啊~
- MySQL 支持事务处理和ACID属性,可以保证数据的一致性和完整性。
- MongoDB的事务支持相对较弱,不能满足所有场景的需求,例如涉及到金钱的场景,这些都需要依赖于 MySQL 事务的强一致性来操作. MongoDB 更适合文档频繁变化的场景.
d)MongoDB 中的一些概念
- Database(库):类似于 MySQL 数据库的概念,用力啊隔离不同的应用数据,不同数据库存放在不同的文件中。默认的数据库为 test.
- Collection(集合):类似于 MySQL 中表的概念,一个库中可以创建多个集合,并且每个集合不像 MySQL 表有固定的结构,这也意味着对集合可以插入不同格式类型的数据. 但通常情况下我们插入集合的数据都有一定的关联性.
- Document(文档):类似于 MySQL 中表中的一条数据. 文档集合中的一条条记录,是一组 BSON 类型的键值对。MongoDB 文档最大的特点就是每个文档之间可以使用不同的字段和数据类型.
例如文档:{"name": "cyk", "age": 20}
e)Docker 下载
1. 拉取 mongo 镜像
docker pull mongo:5.0.52. 运行 mongo
docker run -d --name mongo -p 27017:27017 mongo:5.0.53. 进入 mongo 容器

1.2、库操作
tips看前须知
- cls 用来清屏
- 如果指令过长,可以通过 tab 自动写出.
a)查看所有库
show databases; | show dbs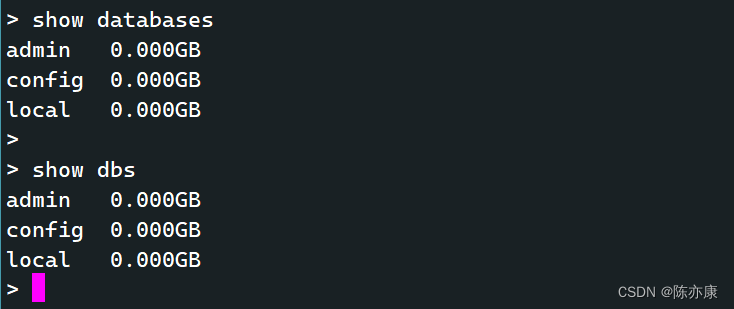
默认数据库说明:
- admin:"root" 数据库,将一个用户添加到这个库中,这个用户自动继承所有数据库的权限. 另外,一些特定的服务器命令也能从这个库中运行,比如列出所有数据库或关闭数据库.
- local:这个数据库的数据永远只有一份,不会被主从复制.
- config:当 Mongo 用于分片设置时,config 数据库再内部使用,用于保存分片的相关信息.
b)创建并使用数据库
use 库名
Ps:use 表示创建并使用,当前库中没有数据时默认不显示这个库
c)查看当前操作的数据库
db
Ps:默认连接的库是 test,但是由于 test 中没有数据,因此不会展示
d)删除数据库
默认删除当前选中的数据库.
db.dropDatabase()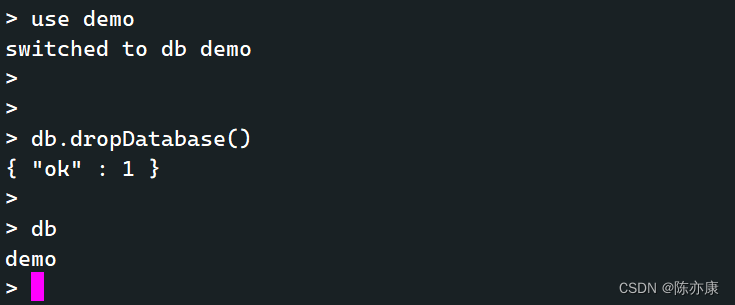
Ps:删除以后用 db 命令还是会显示当前库,只是没有了数据而已
1.3、集合操作
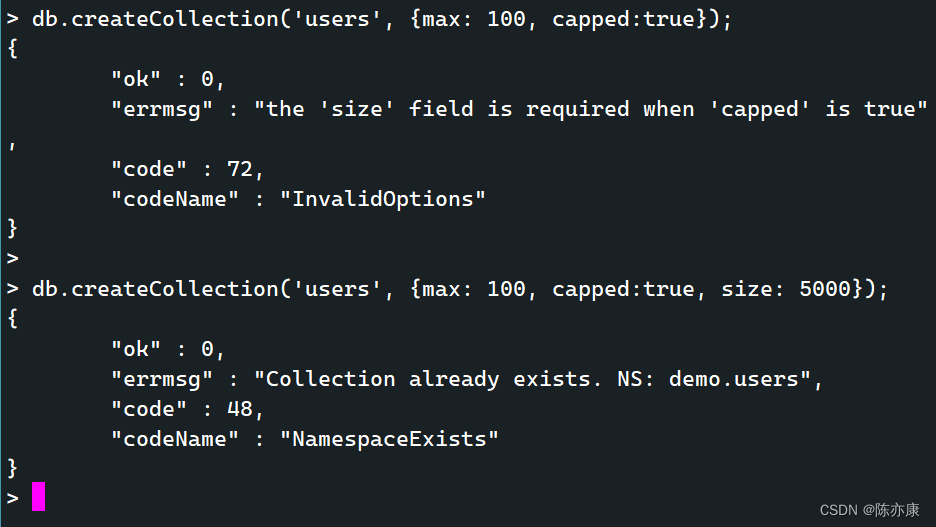
a)创建集合
db.createCollection('集合名', [options])
options 可以是可选参数,如下:
capped:布尔类型. 如果为 true,则创建固定集合(有固定大小的集合,当集合到达最大值时,会自动覆盖最早的文档. 如果值为 true,必须指定 size 参数)。
size:数值类型. 指定集合最大值,单位字节. 如果 capped 为 true ,也需要指定该字段.
max:数值类型. 指定固定集合中文档的最大数量.
Ps:当集合不存在时,插入文档也会自动创建集合.
b)查看库中所有集合
show collections; | show tables;
c)删除集合
db.集合名称.drop();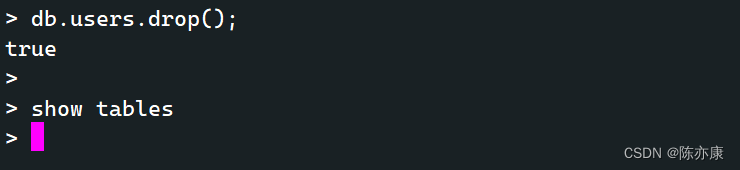
1.4、文档操作
1.4.1、插入文档
a)单条文档
db.集合名称.insert({"name": "cyk", "age": 20})
b)多条文档
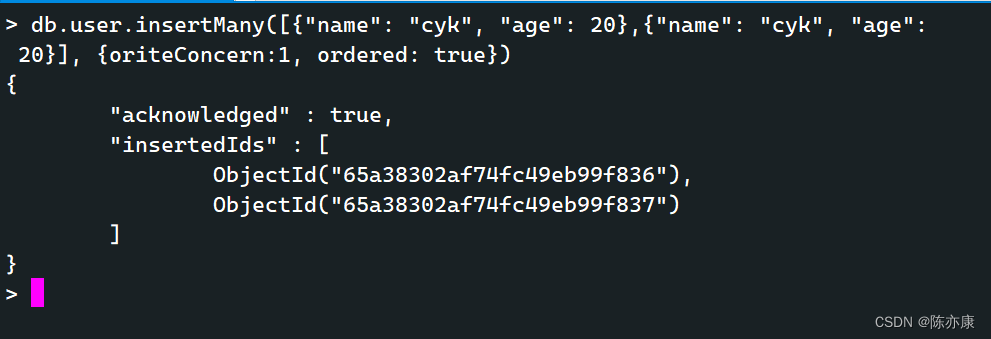
//写法一:
db.集合名.insertMany([<document1>, <document2>, ......],oriteConcern: 1, //写入策略,默认为 1,表示确认写操作,0 表示不要求.ordered: true //指定是否按顺序写入,默认为 true,表示顺序写入
)//写法二:
db.集合名.insert([<document1>,<document2>,......
]);

c)脚本方式
> for(let i = 0; i < 100; i++) {
... db.user.insert({"id": i, "name": "cyk" + i, "age": 20});
... }
WriteResult({ "nInserted" : 1 })
> db.user.find(); //查询所有
{ "_id" : ObjectId("65a38177af74fc49eb99f835"), "name" : "cyk", "age" : 20 }
{ "_id" : ObjectId("65a38302af74fc49eb99f836"), "name" : "cyk", "age" : 20 }
{ "_id" : ObjectId("65a38302af74fc49eb99f837"), "name" : "cyk", "age" : 20 }
{ "_id" : ObjectId("65a38372af74fc49eb99f838"), "name" : "cyk", "age" : 20 }
{ "_id" : ObjectId("65a38372af74fc49eb99f839"), "name" : "cyk", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83a"), "id" : 0, "name" : "cyk0", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83b"), "id" : 1, "name" : "cyk1", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83c"), "id" : 2, "name" : "cyk2", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83d"), "id" : 3, "name" : "cyk3", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83e"), "id" : 4, "name" : "cyk4", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f83f"), "id" : 5, "name" : "cyk5", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f840"), "id" : 6, "name" : "cyk6", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f841"), "id" : 7, "name" : "cyk7", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f842"), "id" : 8, "name" : "cyk8", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f843"), "id" : 9, "name" : "cyk9", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f844"), "id" : 10, "name" : "cyk10", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f845"), "id" : 11, "name" : "cyk11", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f846"), "id" : 12, "name" : "cyk12", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f847"), "id" : 13, "name" : "cyk13", "age" : 20 }
{ "_id" : ObjectId("65a383faaf74fc49eb99f848"), "id" : 14, "name" : "cyk14", "age" : 20 }
Type "it" for more
Ps:
- MongoDB 中每个文档都有一个 _id 作为唯一标识,_id 默认会自动生成,如果手动指定 _id 将使用手动指定的值作为 _id 的值.
- 上述案例中演示的 db.user.find() 表示查询所有,但默认会按照分页的方式,20条为单位进行显示.
1.4.2、删除文档
db.集合名称.remove(<query>,{justOne: <boolean>,writeConcern: <document>}
)可选参数如下:
- query:删除文档条件.
- justOne:如果设定为 true 或 1,则只删除一个文档,如果不设置该参数,或者使用默认值 false,则删除所有匹配条件的文档.
- writeConcern:抛出异常级别.
删除所有如下:

1.4.3、更新文档
db.集合名.update(<query>,<update>,{upsert: <boolean>,multi: <boolean>,writeConcern: <document>}
);参数说明:
- query(必选):update 的查询条件,类似于 sql 中 update 语句 where 后面的.
- update(必选):update 的对象和一些更新的的操作符(例如 $, $inc...),也可以理解为 sql 中 update 语句内 set 后面的.
- upsert(可选): 如果不存在 update 的记录,是否插入 objNew,true 表示插入,false 表示不插入.
- multit(可选):默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来的多条记录全部更新.
- writeConcernt(可选):抛出异常的级别.
a)示例一:将符合条件的全部更新成后面的文档,相当于先删除再插入(不保留原有文档).
> db.user.find();
{ "_id" : 0, "name" : "cyk0", "age" : 10000 }
{ "_id" : 1, "name" : "cyk1", "age" : 10000 }
{ "_id" : 2, "name" : "cyk2", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
>
> db.user.update({name: "cyk0"}, {name: "lyj", bir: new Date()})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
>
> db.user.find();
{ "_id" : 0, "name" : "lyj", "bir" : ISODate("2024-01-14T07:29:44.291Z") }
{ "_id" : 1, "name" : "cyk1", "age" : 10000 }
{ "_id" : 2, "name" : "cyk2", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
b)示例二:更新是所有符合条件的数据,并且保留原有数据,只更新指定字段.
> db.user.find();
{ "_id" : 0, "name" : "lyj", "bir" : ISODate("2024-01-14T07:29:44.291Z") }
{ "_id" : 1, "name" : "cyk1", "age" : 10000 }
{ "_id" : 2, "name" : "cyk2", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
>
> db.user.update({name: "cyk1"}, {$set: {name: "lyj"}},{multi: true})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
>
> db.user.find();
{ "_id" : 0, "name" : "lyj", "bir" : ISODate("2024-01-14T07:29:44.291Z") }
{ "_id" : 1, "name" : "lyj", "age" : 10000 }
{ "_id" : 2, "name" : "cyk2", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
c)更新符合条件的第一条数据,并且保留原有数据,只更新指定字段.
> db.user.find();
{ "_id" : 0, "name" : "lyj", "bir" : ISODate("2024-01-14T07:29:44.291Z") }
{ "_id" : 1, "name" : "lyj", "age" : 10000 }
{ "_id" : 2, "name" : "cyk2", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
>
> db.user.update({name: "cyk2"}, {$set: {name: "lyj"}});
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
>
> db.user.find();
{ "_id" : 0, "name" : "lyj", "bir" : ISODate("2024-01-14T07:29:44.291Z") }
{ "_id" : 1, "name" : "lyj", "age" : 10000 }
{ "_id" : 2, "name" : "lyj", "age" : 10000 }
{ "_id" : 3, "name" : "cyk3", "age" : 10000 }
{ "_id" : 4, "name" : "cyk4", "age" : 10000 }
{ "_id" : 5, "name" : "cyk5", "age" : 10000 }
{ "_id" : 6, "name" : "cyk6", "age" : 10000 }
{ "_id" : 7, "name" : "cyk7", "age" : 10000 }
{ "_id" : 8, "name" : "cyk8", "age" : 10000 }
{ "_id" : 9, "name" : "cyk9", "age" : 10000 }
>
d)更新符合条件的所有数据,保留原有数据,只更新指定字段. 如果没有条件符合时,直接插入数据.
> db.user.find()
{ "_id" : 0, "name" : "cyk", "age" : "20" }
{ "_id" : 1, "name" : "cyk", "age" : "20" }
{ "_id" : 2, "name" : "cyk", "age" : "20" }
{ "_id" : 3, "name" : "cyk", "age" : "20" }
{ "_id" : 4, "name" : "cyk", "age" : "20" }
{ "_id" : 5, "name" : "cyk", "age" : "20" }
{ "_id" : 6, "name" : "cyk", "age" : "20" }
{ "_id" : 7, "name" : "cyk", "age" : "20" }
{ "_id" : 8, "name" : "cyk", "age" : "20" }
{ "_id" : 9, "name" : "cyk", "age" : "20" }
>
> db.user.update({name: "cyk"}, {$set: {name: "lyj"}}, {multi:true, upsert:true});
WriteResult({ "nMatched" : 10, "nUpserted" : 0, "nModified" : 10 })
>
> db.user.find();
{ "_id" : 0, "name" : "lyj", "age" : "20" }
{ "_id" : 1, "name" : "lyj", "age" : "20" }
{ "_id" : 2, "name" : "lyj", "age" : "20" }
{ "_id" : 3, "name" : "lyj", "age" : "20" }
{ "_id" : 4, "name" : "lyj", "age" : "20" }
{ "_id" : 5, "name" : "lyj", "age" : "20" }
{ "_id" : 6, "name" : "lyj", "age" : "20" }
{ "_id" : 7, "name" : "lyj", "age" : "20" }
{ "_id" : 8, "name" : "lyj", "age" : "20" }
{ "_id" : 9, "name" : "lyj", "age" : "20" }
>
> db.user.update({name: "cyk"}, {$set: {name: "lyj"}}, {multi:true, upsert:true});
WriteResult({"nMatched" : 0,"nUpserted" : 1,"nModified" : 0,"_id" : ObjectId("65a39089bfda7f595ed18e98")
})
>
> db.user.find();
{ "_id" : 0, "name" : "lyj", "age" : "20" }
{ "_id" : 1, "name" : "lyj", "age" : "20" }
{ "_id" : 2, "name" : "lyj", "age" : "20" }
{ "_id" : 3, "name" : "lyj", "age" : "20" }
{ "_id" : 4, "name" : "lyj", "age" : "20" }
{ "_id" : 5, "name" : "lyj", "age" : "20" }
{ "_id" : 6, "name" : "lyj", "age" : "20" }
{ "_id" : 7, "name" : "lyj", "age" : "20" }
{ "_id" : 8, "name" : "lyj", "age" : "20" }
{ "_id" : 9, "name" : "lyj", "age" : "20" }
{ "_id" : ObjectId("65a39089bfda7f595ed18e98"), "name" : "lyj" }
1.4.4、查询文档
a)基本查询
db.集合名.find(query, projection)query:可选,使用查询操作符指定查询条件.
projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值,只需要省略该参数即可(默认省略).
如果需要以易读的方式来读取数据,可以使用 pretty() 方法以格式化的方式来显示文档,语法如下:
db.集合名.find().pretty()b)类比 MySQL 的 where name = 'cyk'
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({name: "cyk0"})
{ "_id" : 0, "name" : "cyk0" }c)类比 MySQL 的 where _id < 5
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
>
> db.user.find({_id: {$lt: 5}})
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
d)类比 MySQL 的 where _id <= 5
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: {$lte: 5}})
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
>
e)类比 MySQL 的 where _id > 5
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: {$gt: 5}})
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
f)类比 MySQL 的 where _id >= 5
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: {$gte: 5}})
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }g)类比 MySQL 的 where age != 5
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: {$ne: 5}})
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
h)AND 连接
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: 5, name: "cyk5"});
{ "_id" : 5, "name" : "cyk5" }
>
如果 and 查询字段相同的有多个,那么只有最后一个生效.
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({name: cyk2, name: cyk3})
uncaught exception: ReferenceError: cyk2 is not defined :
@(shell):1:15
> db.user.find({name: "cyk2", name: "cyk3"})
{ "_id" : 3, "name" : "cyk3" }
i)OR 连接
这里需要使用关键字 $or 表示 "或者"
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({$or: [{name: "cyk1"}, {name: "cyk2"}]})
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
>
j)AND 和 OR 联合
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
>
> db.user.find({_id: {$gt:5}, $or: [{name: "cyk7"}, {name: "cyk8"}]})
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
>
k)数组中查询
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find({likes: "唱歌"})
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
也可以按照数组的长度查询指定文档.
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find({likes: {$size: 3}})
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
l)模糊查询
例如 SQL 中的 where name like '%y%',在 MongoDB 中可以使用正则表达式实现近似模糊查询功能.
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find({likes: /钢/})
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
m)排序
1 表示升序,-1 表示降序
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find().sort({_id: -1})
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 0, "name" : "cyk0" }
>
n)分页
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find().count();
11
>
o)分页
类似于 MySQL 的 limit ... offset ...
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find().skip(3).limit(3);
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
> db.user.find().skip(0).limit(3);
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
>
p)去重
> db.user.distinct('name')
["cyk0","cyk1","cyk10","cyk2","cyk3","cyk4","cyk5","cyk6","cyk7","cyk8","cyk9"
]
>
q)返回指定字段
语法: db.集合名.find({查询条件}, {指定字段: 1, ...})1 表示返回,0 表示不反悔.
Ps:1 和 0 不能同时使用.
> db.user.find();
{ "_id" : 0, "name" : "cyk0" }
{ "_id" : 1, "name" : "cyk1" }
{ "_id" : 2, "name" : "cyk2" }
{ "_id" : 3, "name" : "cyk3" }
{ "_id" : 4, "name" : "cyk4" }
{ "_id" : 5, "name" : "cyk5" }
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
> db.user.find({_id :{$gt: 5}}, {name: 1})
{ "_id" : 6, "name" : "cyk6" }
{ "_id" : 7, "name" : "cyk7" }
{ "_id" : 8, "name" : "cyk8" }
{ "_id" : 9, "name" : "cyk9" }
{ "_id" : 10, "name" : "cyk10" }
> db.user.find({_id :{$gt: 5}}, {name: 0})
{ "_id" : 6 }
{ "_id" : 7 }
{ "_id" : 8 }
{ "_id" : 9 }
{ "_id" : 10, "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
> db.user.find({_id :{$gt: 5}}, {_id: 0})
{ "name" : "cyk6" }
{ "name" : "cyk7" }
{ "name" : "cyk8" }
{ "name" : "cyk9" }
{ "name" : "cyk10", "likes" : [ "敲代码", "唱歌", "弹钢琴" ] }
>
1.5、$type
$ type 操作符是基于 BSON 类型来检索集合中匹配的数据类型,并返回结果.
MongoDB 中可以使用的类型如下:
- String − 这是存储数据最常用的数据类型。字符串在 MongoDB 必须是UTF-8有效。
- Integer − 此类型用于存储数值。整数可以是32位 或 64位,具体取决于您的服务器。
- Boolean −此类型用于存储布尔(true / false)值。
- Double − 此类型用于存储浮点值。
- Min/ Max keys −该类型用于将值与最低和最高的BSON元素进行比较。
- Arrays −此类型用于将数组或列表或多个值存储到一个键中。
- Timestamp− ctimestamp(时间戳)。当文档被修改或添加时,这可以方便地进行记录。
- Object −此数据类型用于嵌入式文档。
- Null −此类型用于存储 Null 值。
- Symbol−此数据类型与字符串使用相同;但是,它通常是为使用特定符号类型的语言保留的。
- Date − 此数据类型用于以UNIX时间格式存储当前日期或时间。您可以通过创建 Date 对象并将日期,月份,年份递到其中来指定自己的日期时间。
- Object ID −此数据类型用于存储文档的ID。
- Binary data −此数据类型用于存储二进制数据。
- Code −此数据类型用于将JavaScript代码存储到文档中。
- Regular expression −此数据类型用于存储正则表达式。
Ps:查询的时候类型要全小写
例如我插入了如下文档:
> db.aaa.insert({_id: 1, tar: 1})
WriteResult({ "nInserted" : 1 })
>
> db.aaa.insert({_id: 2, tar: "cyk"})
WriteResult({ "nInserted" : 1 })
>
> db.aaa.insert({_id: 3, tar: true})
WriteResult({ "nInserted" : 1 })
>
> db.aaa.insert({_id: 4, tar: ['aaa', 'bbb', 'ccc']})
>
> db.aaa.insert({_id: 5, tar: 1.2})
WriteResult({ "nInserted" : 1 })
>
> db.aaa.find();
{ "_id" : 1, "tar" : 1 }
{ "_id" : 2, "tar" : "cyk" }
{ "_id" : 3, "tar" : true }
{ "_id" : 4, "tar" : [ "aaa", "bbb", "ccc" ] }
{ "_id" : 5, "tar" : 1.2 }
a)现在需要查询 tar 类型为 array 的数据,则可以使用以下命令:
> db.aaa.find({tar: {$type: 'array'}})
{ "_id" : 4, "tar" : [ "aaa", "bbb", "ccc" ] }
b)现在需要查询 tar 类型为 string 的数据(字符串数组也算),则可以使用以下命令:
> db.aaa.find({tar: {$type: 'string'}})
{ "_id" : 2, "tar" : "cyk" }
{ "_id" : 4, "tar" : [ "aaa", "bbb", "ccc" ] }
>