🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
✨博客主页:小小恶斯法克的博客
🎈该系列文章专栏:力扣刷题讲解-MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注! ❤️

目录
🚀查找重复的电子邮箱
🚀查找没有买东西的顾客
🚀总结
🚀查找重复的电子邮箱
表:
Person+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | email | varchar | +-------------+---------+ id 是该表的主键(具有唯一值的列)。 此表的每一行都包含一封电子邮件。电子邮件不包含大写字母。 编写解决方案来报告所有重复的电子邮件。 请注意,可以保证电子邮件字段不为 NULL。
以 任意顺序 返回结果表。
结果格式如下例。
示例 1:
输入:
Person 表:
+----+---------+
| id | email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
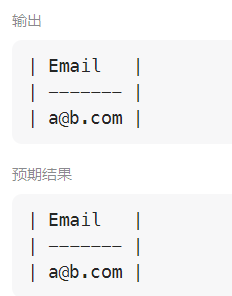
输出:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
解释: a@b.com 出现了两次。
解法一:
1.自连接
2.因为实际上就这一个表,一般这类题目都是首选用自连接的方法
3.那么自连接就是需要起别名
4.这里我们肯定是把它想成两个表,一个p1,一个p2
5.那么我们自连接后面的on的条件是什么?
6.因为要找重复的邮箱,所以我们肯定是找两个表相同的邮箱,即p1.email = p2.email
7.但是只有这一个条件肯定是不够的,因为你这里是把它想成了两张表,但实际上这两张表本来就是一样的,它们两的字段email里面的value本身也就是一样的,你只有这一个条件,没有任何意义
8.所以还需要一个条件,就是我们是根据不同的id相同的email,这才叫重复
9.连接两个不同的条件用and
10.两个表中id要不相同的去比较,即p1.Id != p2.Id
11.所以写为select p1.Email from Person p1 join Person p2 on p1.Email = p2.Email AND p1.Id!=p2.Id
12.但此时还是不对的,因为id为1的email=id为3的email,然后id为3的email=id为1的email,相当于最后输出email,会输出两次一样的,重复了
13.那么最后一步就是去重,用关键字distinct,代码如下
select distinct(p1.Email) from Person p1
join Person p2 on p1.Email = p2.Email AND p1.Id!=p2.Id执行:
解法二:
1.使用 GROUP BY 和 HAVING 子句
2.这个解法首先按照电子邮件地址分组,然后使用 HAVING 子句筛选出出现次数大于 1 的电子邮件地址,从而找出重复的电子邮件。
SELECT email
FROM Person
GROUP BY email
HAVING COUNT(email) > 1;
解法三:
1.使用子查询
2.这个解法使用了子查询,首先在子查询中找出重复的电子邮件,然后在外部查询中选择出现在子查询结果中的电子邮件。
3.这个意思就相当于把解法2作为一个嵌套select,只是没有去重,然后外部再套一个select用于去找子查询中的email
5.用where去筛查子查询中的电子邮件
6.代码如下:
SELECT email
FROM Person
WHERE email IN (SELECT emailFROM PersonGROUP BY emailHAVING COUNT(email) > 1
);
不过博主比较推荐用第一种和第二种,逻辑比较清晰,最后一种相当于画蛇添足
🚀查找没有买东西的顾客
Customers表:+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ 在 SQL 中,id 是该表的主键。 该表的每一行都表示客户的 ID 和名称。
Orders表:+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | customerId | int | +-------------+------+ 在 SQL 中,id 是该表的主键。 customerId 是 Customers 表中 ID 的外键( Pandas 中的连接键)。 该表的每一行都表示订单的 ID 和订购该订单的客户的 ID。
找出所有从不点任何东西的顾客。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入:
Customers 表:
+----+-------+
| id | name |
+----+-------+
| 1 | Joe |
| 2 | Henry |
| 3 | Sam |
| 4 | Max |
+----+-------+
Orders 表:
+----+------------+
| id | customerId |
+----+------------+
| 1 | 3 |
| 2 | 1 |
+----+------------+
输出:
+-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
解法一:
1.要找出所有从不点任何东西的顾客,我们可以使用 SQL 中的 LEFT JOIN 和 IS NULL 来解决这个问题。
2.左外连接相当于查询左表的所有数据,也包含了左表和右表交集部分的数据
3.所以我们肯定是select * from Customers left join Orders on 条件
4.我们肯定是要给表取一个别名比较方便简洁
5.SELECT * FROM Customers c LEFT JOIN Orders o ON 条件
6.那么现在最重要的其实就是我们的ON后面的连接条件到底是什么?
7.即用Orders的外键,去关联Customers的主键,因为实际上Orders的外键代表的就是Customers的主键,所有条件是O.customerId = C.Id
8.即SELECT * FROM Customers c LEFT JOIN Orders o ON c.id = o.customerId
9.此时只是左外连接成功了,但是我们还没有完成,它只是把所有数据返回了,这时候我们要进行筛选
10.筛选我们用到where条件,那么where后面的条件如何写呢?
8..我们会把左表的所有数据返回,包括没有买东西的顾客和他们的订单,那么没有买东西的顾客就是null
9.我们再用where子句去过滤出Orders 表中没有对应订单的顾客,即 o.id IS NULL。这样就能找出所有从不点任何东西的顾客。
10.SELECT * FROM Customers c LEFT JOIN Orders o ON c.id = o.customerId WHERE o.id IS NULL;
11.再把*优化一下,代码如下:
SELECT c.name AS Customers
FROM Customers c
LEFT JOIN Orders o ON c.id = o.customerId
WHERE o.id IS NULL;
🚀总结
这个查询首先从 Customers 表中选择顾客的名称,并左连接 Orders 表,以便找出所有顾客和他们的订单。然后使用 WHERE 子句过滤出在 Orders 表中没有对应订单的顾客,即 o.id IS NULL。这样就能找出所有从不点任何东西的顾客。
在这个示例中,查询的结果会返回 Henry 和 Max,因为他们在 Orders 表中没有对应的订单记录。
解法二:
1.运用not in去找Customers表中谁的id,没有在Orders表中的CustomerId中
2.意思也就是,这4个人,谁没有顾客订单,我们就返回谁的名字
3.select * from Customers c where c.id not in (select CustomerId from Orders)
4.优化一下*,返回名字,然后字段取需要的别名Customers
5.代码如下
select Name Customers
from Customers c
where c.Id not in (select CustomerId from Orders
)