作者:彭思达 | CCF专业会员 浙江大学研究员 主要研究方向为三维计算机视觉 | 本文版权归作者所有
文章目录
- 引言
- 阶段1:想idea
- 阶段2:如何做实验
- 阶段3:如何写论文
引言
完成一篇论文的常见科研历程包括三大阶段:想idea、做实验、写论文。每个阶段又有细分的小步骤。在“想idea”阶段,首先规划一个重要的科研任务,然后调研任务中需要解决的技术挑战/失败案例 (failure cases),最后针对挑战构思解决方案。在“做实验”阶段,首先根据问题的解决方案设计简单实验 (toy experiments),用于快速验证方案的正确性,然后在简单实验设定下改进并调整方案,最后在真实数据上把算法调出理想的效果。在“写论文”阶段,首先根据论文的截止日期规划论文各部分的完成时间,然后开始撰写论文。在完成论文初稿后,可以找导师或行业内专家帮忙评阅论文,找出论文缺陷并进行修改。
阶段1:想idea
“想idea”指的是确定具体的科研任务,找到该任务中最前沿的地方面临的技术挑战,并提出相应的解决方法。
以三维计算机视觉方向为例,笔者认为存在两种科研风格:目标驱动型科研 (goal-driven research) 和想法驱动型科研 (idea-driven research)。前者的思路为:首先设定一个长远的科研目标,然后规划实现该目标的路线(roadmap),即需要完成哪些科研任务,最后基于提出的路线图,选择其中的某个任务进行研究。而后者的思路为:看到了一篇有意思的前沿论文,想着如何着手改进该论文中的算法。
这两种科研风格有各自的优缺点。想法驱动型科研的优点是容易上手,是大部分科研新手会选择的科研方式,其缺点比较明显:(1)因为是在已有论文上改进已有的方法,所以除非改进的效果非常好,否则论文影响力有限;(2)科研思路可能被该论文带偏,因为该论文的路线有可能是错的;(3)容易和其他研究人员有相似的解决思路,因为其他人也可能在改进该论文;(4)由于任务已经被该论文尝试解决过了,解法上的创新空间有限,需要很聪明、很深刻的见解才能针对任务提出突破性的新技术。
目标驱动型科研有三个优点:(1)容易做出突破性的创新。因为该科研方式从个人感兴趣的任务出发,为领域提出新问题,不是对已有论文进行改进,而是引领该领域的发展;(2)该科研方式有明确的长远目标和路线图,因此更有自洽的动机,有利于形成自己独特的科研风格;(3)科研更具有连续性,科研成果可以形成体系。但目标驱动型科研也有缺点,因为规划一条合理的研究路线图是一件很难的事情,需要有丰富的科研经验。刚入门的科研新手往往无法构思出较好的研究路线图。不过笔者仍然鼓励科研新手尝试构建自己的研究路线,在此过程中可以锻炼自己的能力,并且厘清日后的科研规划。虽然路线一开始不一定合理,但可以随着经验的增加进行动态调整。
目标驱动型科研中“想idea”的详细步骤如下。首先规划一个长期目标,从事科研的人一般会有一个偏“科幻”的目标,比如想让ChatGPT有一个自己的身躯。为了实现这个目标,需要制定一组重要的任务,即研究路线。可以规划的几个任务是:先让ChatGPT模仿人的动作,再让ChatGPT生成自己新的动作,最后让ChatGPT与人、外界环境交互。有了研究路线后,再选择研究空间较大且用当前学术界的技术可以解决的科研任务,开始着手研究。
规划自己的研究路线是“想idea”中最重要也是最难的一步。如果一个研究人员有特别丰富的科研经验,知道这个领域有哪些重要技术、重要论文、重要问题,很容易规划出一个合理的研究路线。笔者设计了一棵“文献树”用来规划研究路线,构建过程如下:首先列出自己科研方向上的大多数论文,阅读论文并梳理论文解决了什么问题,根据问题将论文分类。这些论文解决的问题通常是有进展性的,难度是不断加深的。然后梳理每个任务下的论文的一般性框架和流程,并根据技术框架进一步分类论文。这样就建立起了一棵三层文献树。该文献树可以帮助自己清楚地了解该领域的重要问题和重要技术框架,从而有助于规划研究路线。除此之外,以后写论文时,可以把论文放到这棵文献树下面,根据该论文在文献树中的位置,判断其贡献程度,比如是否提出了一个新问题,或者提出了一个新的技术框架。
规划好重要任务后,要找到任务中最前沿的方法面临的技术挑战。例如,探索算法上限的一个方法是在一些更具有挑战性的数据或者设定下验证该算法,看其实验效果。这种方法除了帮助我们发现有意思的研究点,还能让同行看到新的实验结论和可能性。这在实验上是一个很大的贡献,在论文里放这些实验结论是一个比较大的加分项。这种情况下,论文是比较容易被接收的。
确定好想要解决的技术挑战后,就要构思解决方法。提出漂亮解法的前提是积累已有的解法,构建自己的“武器库”。很多任务和实验现象背后有相似的技术挑战,也就是一些方法效果不好的技术原因往往比较相近。因此,解决这些任务的技术思想较为通用。笔者构建武器库的方法是构建一棵挑战-解法树(challenge-insight tree):首先收集一个研究方向存在的抽象技术挑战,然后收集这些技术挑战下面的解法。例如,逆渲染任务(inverse rendering)常见的挑战有渲染计算量较大和光照建模不准,应对这些挑战的解法有预计算、各种光照模型等。逆渲染任务在不同设定下会经常遇到类似的挑战。在遇到类似的技术挑战时,就可以在挑战-解法树中寻找解法,而不是从零开始构思解法。总体来说,构思解法的流程是:在新数据、新设定下尝试现有方法,发现较差的实验结果,分析其本质的技术原因,抽离表面问题得到真正的技术挑战;从武器库中选择一些技术,进行创新性的组合,解决该技术挑战。
基于技术挑战想解决方法的一个好处是,重要的技术挑战会推动我们提出新颖的解法。如果一个技术挑战可以被简单的“A+B”式技术组合解决,那么该技术挑战可能不重要。重要的技术挑战会有其独特的地方,无法被简单的“A+B”式方法解决,因此会推动我们提出新的技巧或框架,将已有的一些技术进行创新性的组合,解决该技术挑战下的特有问题。
除了上述常规的流程,“想idea”的过程还有一个特殊情况:当出现一个新“技术锤子”时,用这个新锤子尝试解决研究路线上的一些科研任务是非常值得的做法。这样容易做出有影响力的工作。举两个三维视觉领域的例子,当神经辐射场(NeRF)这个工作出现时,有人将其用于三维重建的任务,实现了神经表面重建方法NeuS。当稳定扩散(stable diffusion)方法出现时,有人将其用于文本生成3D的任务,做出了DreamFusion。这种想idea的方式仍然属于目标驱动型,拿一个新的技术解决科研路线上的任务,只不过不是分析当前任务面临的技术挑战能被哪些技术解决,而是分析新锤子能解决该任务的哪些技术挑战。
阶段2:如何做实验
提出基本的解决思路以后,就可以开始做实验,在目标数据上验证算法。在实验过程中,我们可能会遇到一些预想不到的问题,一般会在实验过程中迭代式地改进算法。
做实验一般是一篇论文完成过程中工作量最大的一个环节。好的实验习惯和能力能够极大地影响一篇论文的完成质量和速度。同样的idea,有人用一年完成一篇论文,而有人用六个月就完成了,并且论文实验很充分。造成两者差异的原因就在于实验习惯和实验能力不同。
做实验阶段包含三个步骤:首先根据解法设计简单实验,用于快速验证解法的正确性,然后在简单实验设定下改进并调通解法,最后用真实数据将这个解法实践成功。
简单实验指的是只存在核心技术挑战的实验。一般而言,一个实验数据不会只有一个技术挑战。举个例子,三维重建任务的目标数据可能同时存在相机位姿不准、目标物体纹理较弱、目标物体几何复杂等技术挑战。如果只想解决几何复杂度的问题,可以先假设其他技术挑战已解决,专注于在复杂几何问题下验证解法的正确性。简单实验有两个好处:一个是降低实验的难度,只需要解决一个技术挑战即可;另一个是可以降低实验的时间成本,如果在论文初始阶段就在一个特别复杂的数据上做实验,一两个月以后发现解法不正确,那么就浪费了很多时间。
如何设计简单的实验?首先要明确论文想解决的核心技术挑战,然后分析当前数据或设定存在哪些额外的技术挑战,并寻找或人为构建额外技术挑战的数据或设定。
设计好简单实验后开始在这组数据上验证提出的解法。图1展示了一个常见的实验流程。首先基于一个idea进行实验,实验成功即可进入下一个实验。如果实验失败了,就要分析实验效果不理想的原因,并基于原因改进idea,然后进入下一个循环。这是一个经典的实验循环流程。根据笔者的个人经验,论文初期的实验会经历几十次这样的循环,在这些循环中研究人员会逐渐地收获很多认知,一步步改进算法,最终得到一个效果理想的算法。实验循环的迭代速度决定了做论文的时间。有人一天能经历五次循环,而有人一天只经历一次循环,前者做一个月的实验相当于后者做五个月的实验,论文进度的差距就拉开了。

图1 一般实验流程
做实验的核心步骤是分析实验效果不理想的原因。该步骤一般分为三步:发现实验效果不理想的表面原因,发现本质的技术原因,通过实验验证这个原因。表面原因指一些表层因素,比如切换数据以后效果变差,那么数据就是一个表层原因。本质的技术原因指内部的机理,比如为什么换了数据以后效果变差,数据的哪个特征导致效果变差?假设一些原因后,再通过实验验证该原因是否确实存在,然后有针对性地进行改进。
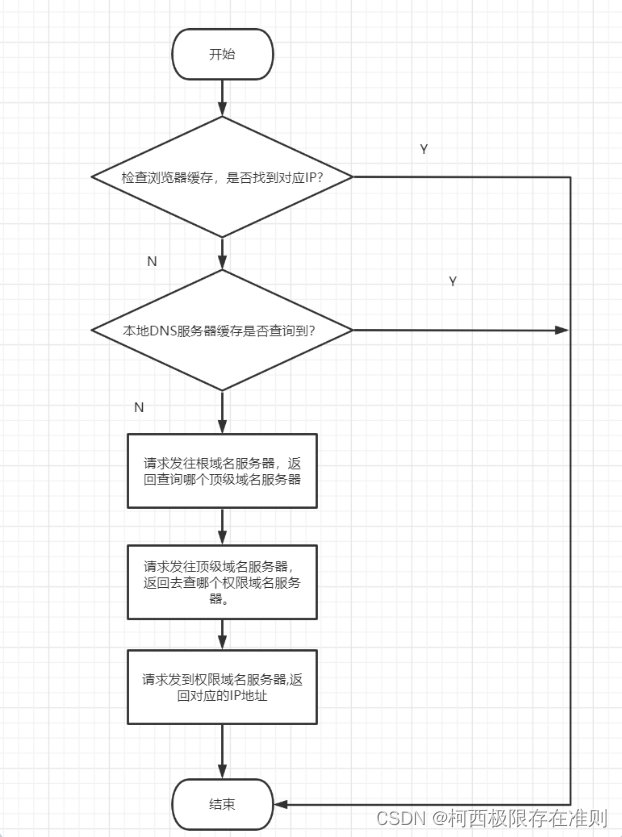
图2展示了一个流程图,用于发现实验效果不理想的表面原因。笔者的经验是基于一个效果不理想的实验,再设计一个效果理想的实验,然后把两头的实验固定住,分析两个实验的差异。

图2 实验流程图
如果是数据造成了实验效果不理想,一般有两种情况。第一种情况是,同一个实验中,可能有一些数据例子效果很好,而有一些数据例子效果较差,可以对比这两组数据的差异。第二种情况是,实验中所有数据效果都不好,此时可以切换到更简单的数据再做一次实验,看看简单数据上实验效果是否理想。找到一个让实验效果理想的数据后,再对比两组数据的差异。
如果是算法模块造成实验效果不理想,可以先找到一个效果理想的算法,再对比其与之前算法的差异。在对比的过程中不断地缩小两个算法的差异,最终定位到一个关键的算法模块或者技巧(trick)。
在分析本质的技术原因时,笔者总结了两个可能的原因:代码有bug和算法在某个数据上的效果不理想。查找代码的bug有两个方法:逐行检查代码输出,验证输出结果和预期是否一致,以及检查个人对算法的理解是否到位。
检查算法问题的一个有效方法是看相关论文使用了什么技巧,给相关论文算法做消融实验,找出算法的关键部分。一些情况下,算法本身没问题,只是缺少技巧。一个经典的例子是NeRF,该算法如果缺少位置编码(positional encoding)这一技巧,效果会大打折扣。
在寻找问题的过程中,不能只归就于某一个原因,不能一开始就觉得算法完全不行。算法效果不好很可能是多种原因叠加在一起造成的。算法可能在A数据上效果不好,但在B数据上效果很好。我们需要不断地质疑算法,并同时相信自己的算法,寻找各方面的原因,包括数据难度、代码bug、算法技巧等。最后,针对找到的技术原因,再有针对性地改进解法,畅想更多的解法。
在简单数据上把算法调出理想的效果后,需要在真实数据上运行算法。这一步骤和前文描述的实验流程类似。因为已经验证了核心的创新性算法,对于真实数据,如果存在其他的技术挑战,只需要有针对性地使用一些已有的解决方法即可。
阶段3:如何写论文
论文是展示新想法的重要方式。优秀的撰写论文的能力能够极大地提升一个idea的影响力。同样的idea,有人能写出非常有影响力的论文,而有些人却只能写出在接收边缘的论文。一篇好的论文,写作思路要清晰,能讲清楚核心贡献点。论文的实验部分要有充足的对比实验和消融实验,以此验证技术贡献点的有效性。论文尽量在更具有挑战性的数据上做实验,以充分挖掘算法的潜力,扩展领域的想象力和可能性。
将核心算法在目标数据上实践后,即可开始写论文:(1)首先梳理论文的故事(story),写一个类似论文引言(introduction)的初稿,同时整理论文所需的对比实验和消融实验。最好先做消融实验,确认方法的最优版本,然后做对比实验。(2)构思论文方法(method)的提纲,撰写论文方法,同步做论文实验。(3)修改论文的引言和方法,同步进行论文实验。(4)构思实验的提纲,撰写实验。(5)撰写论文的相关工作(related work)。(6)评阅论文,修改论文的引言、方法和实验。(7)写论文摘要,取论文标题。(8)反复评阅论文,修改论文。
组织论文的故事是“写论文”阶段的核心步骤。笔者常常使用“倒推-正推”法梳理论文的故事。在倒推部分,首先明确论文的贡献是什么,比如提出了某个新任务,发现了某个新的技术挑战,提出了某个新技术;然后明确论文提出的技术有什么优势,解决了什么挑战;最后研究如何通过描述之前的方法引出论文解决的技术挑战。
基于倒推部分回答的三点问题,在正推部分即可梳理出论文的故事:首先介绍论文的任务;然后讨论之前的方法,引出论文解决的技术挑战;针对该技术挑战,论文提出了某个新技术;描述论文技术的优势。
论文实验部分主要包括:对比实验、消融实验和一些可视化效果(demo)。消融实验的目的是验证论文提出的各部分技术的有效性,一般包含一张大表格和一些小表格。大表格列出论文核心技术贡献点以及一些技术模块对论文方法效果的影响。小表格分别列出某个方法模块中的技术设计、超参的消融结果,或者是方法对输入数据质量的敏感程度。
论文的demo与论文的影响力有较大关系。好的demo可以较好地展示论文技术的有效性,让读者直观地体会到论文对领域的推动程度。因此,在目标数据上把算法调出理想效果后,尽量在更多新的有挑战性的数据上做实验,看看算法的极限,挖掘算法的潜力。读者通常希望看到一个算法的效果能达到什么程度。论文在具有挑战性的新数据上将一个算法调出理想效果是一个很大的贡献。
论文写完后,需要评阅论文,找出需要修改的点,通常是检查论文是否存在被拒的因素,常见的论文被拒因素有以下五个方面。
1.论文贡献不够,没有给读者带来新的知识,分两种情况:论文想解决的技术挑战已经被很多论文解决过了,而且被解决得比较好了;论文提出的技术已经被很好地探索了,该技术带来的效果提升是可预⻅的。在这两种情况下,读者很可能看多了类似的工作,缺乏新鲜感。
2.写作不清楚。常见情况是论文缺少一些技术细节,导致论文不可复现。还有的情况是论文方法设计缺少研究动机(motivation),没有讲清楚为什么采用该设计。
3.实验效果不够好。论文方法的效果只比之前的方法好一点,或者是虽然比之前的方法效果好,但总体效果仍然不够好。
4.实验测试不充分。论文缺少重要的消融实验、重要的基线方法以及重要的实验指标,或者是论文的实验数据太简单,无法证明方法是否真的产生理想效果。
5.方法设计有问题。有四种情况:(1)论文的任务设定不切实际,没有意义;(2)方法存在技术缺陷,看起来不合理;(3)方法不鲁棒,需要在每个场景上调超参,对目标数据很敏感;(4)新的方法设计在带来收益的同时,也引入了更强的缺陷,导致新方法的收益为负。