文章目录
- 大模型部署背景
- 模型部署
- 大模型的特点
- 大模型部署的挑战
- 大模型部署方案
- LMDeploy简介
大模型部署背景
模型部署
- 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
- 为了满足性能和效率的需求,常常需要对模型进行优化,如模型压缩和硬件加速
- 云端、边缘计算端、移动端部署
- 计算设备为CPU、GPU、NPU、TPU等
大模型的特点
- 内存开销巨大
- 参数量巨大
- 回归生成token,需要缓存Attention的k/v,带来巨大的内存消耗
- 动态shape,输入输出都是动态的
- 相对视觉模型,LLM结构简单
大模型部署的挑战
- 设备
- 如何应对巨大的存储问题?低存储设备如何部署?
- 推理
- 如何加速token的生成速度
- 如何解决动态shape,让推理可以不间断
- 如何有效管理和利用内存
- 服务
- 如何提升系统整体的吞吐量
- 对于个体用户,如何降低响应时间
大模型部署方案
- 技术点
- 模型并行
- 低比特量化
- Page Attention
- transformer 计算和访存优化
- Continuous Batch
- …
- 方案
- huggingface transformers
- 专门推理加速框架
- 云端
- imdeploy
- vllm
- tensorrt-llm
- deepspeed
- 移动端
- llama.cpp
- mlc-llm
- 云端
LMDeploy简介
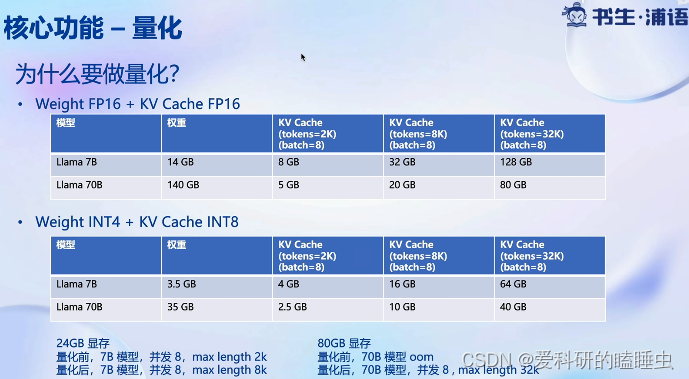
- 高效推理引擎,持续批量处理技巧,深度优化的低比特计算kernel,模型并行,高效的k/v缓存机制
- 完备易用的工具链,量化、推理、服务全流程,无缝对接OpenCompass评测推理精度,与OpenAI接口高度兼容





![街机模拟游戏逆向工程(HACKROM)教程:[11]68K汇编sub指令](https://img-blog.csdnimg.cn/direct/7773c772eb124210b603c3aab3c219b1.png)
