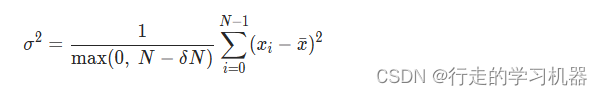文章目录
- 前言
- 一、ARGMAX
- 二、ARGMIN
- 三、AMAX和AMIN
- 四、ALL和ANY
- 五、MAX和MIN
- 六、MEAN
- 七、MEDIAN
- 八、NORM
- 九、PROD
- 十、STD
- 十一、SUM
- 十二、UNIQUE
- 十三、VAR
前言
介绍pytorch的Reduction Ops。
一、ARGMAX
torch.argmax(input, dim, keepdim=False) → LongTensor
Parameters:
input (Tensor) – the input tensor.
dim (int) – the dimension to reduce. If None, the argmax of the flattened input is returned.
keepdim (bool) – whether the output tensor has dim retained or not. Ignored if dim=None.
返回输入张量中所有元素的最大值的索引。
这是 torch.max() 返回的第二个值。
注意:
如果存在多个最大值,则返回第一个最大值的索引。


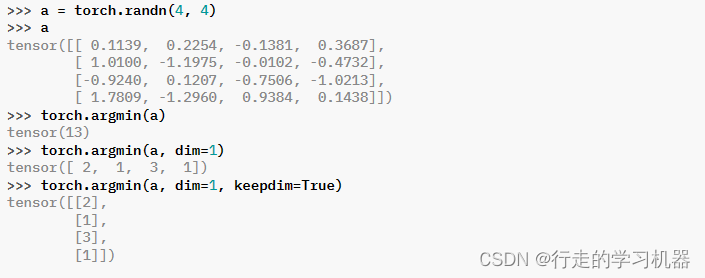
二、ARGMIN
torch.argmin(input, dim=None, keepdim=False) → LongTensor
Parameters:
input (Tensor) – the input tensor.
dim (int) – the dimension to reduce. If None, the argmin of the flattened input is returned.
keepdim (bool) – whether the output tensor has dim retained or not…
返回输入张量中所有元素的最小值的索引。
这是 torch.min() 返回的第二个值。
注意:
如果存在多个最小值,则返回第一个最小值的索引。
三、AMAX和AMIN
torch.amax(input, dim, keepdim=False, , out=None) → Tensor
torch.amin(input, dim, keepdim=False, , out=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int or tuple of ints) – the dimension or dimensions to reduce.
keepdim (bool) – whether the output tensor has dim retained or not.
Keyword Arguments:
out (Tensor, optional) – the output tensor.
返回输入张量在给定维度(维度)dim中的每个切片的最大值/最小值。
注意:
max/min 与 amax/amin 之间的区别为:
- amax/amin 支持在多个维度上进行减少,
- amax/amin 不返回索引,
- amax/amin 在相等的值之间均匀分配梯度,而 max(dim)/min(dim) 仅将梯度传播到源张量中的单个索引。
如果 keepdim 为 True,则输出张量在除了维度(维度)dim的位置大小与输入相同。否则,dim 被挤压(参见 torch.squeeze()),导致输出张量的维度减少1(或 len(dim))。


四、ALL和ANY
torch.all(input) → Tensor
torch.any(input) → Tensor
all:输入中是否所有的任何元素评估为 True。
any:测试输入中是否有任何元素评估为 True。
此函数匹配 NumPy 的行为,在除 uint8 外的所有支持的 dtype 上返回 bool 类型的输出。对于 uint8,输出的 dtype 本身是 uint8。


五、MAX和MIN
**torch.max(input, dim, keepdim=False, , out=None)
torch.min(input, dim, keepdim=False, , out=None)
Parameters:
input (Tensor) – the input tensor.
dim (int) – the dimension to reduce.
keepdim (bool) – whether the output tensor has dim retained or not. Default: False.
Keyword Arguments:
out (tuple, optional) – the result tuple of two output tensors (max, max_indices)
返回一个命名元组 (values, indices),其中 values 是输入张量在给定维度 dim 中每行的最大值。而 indices 是找到的每个最大值的索引位置(argmax)。
如果 keepdim 为 True,则输出张量在除了维度 dim 的位置大小与输入相同。否则,dim 被挤压(参见 torch.squeeze()),导致输出张量的维度比输入少 1。
注意:
如果在缩减的行中存在多个最大值,则返回第一个最大值的索引。
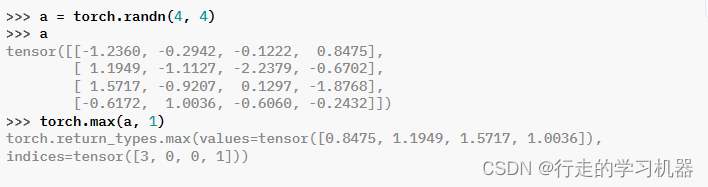

torch.min()用法同torch.max()。
六、MEAN
*torch.mean(input, dim, keepdim=False, , dtype=None, out=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int or tuple of ints) – the dimension or dimensions to reduce.
keepdim (bool) – whether the output tensor has dim retained or not.
Keyword Arguments:
dtype (torch.dtype, optional) – the desired data type of returned tensor. If specified, the input tensor is casted to dtype before the operation is performed. This is useful for preventing data type overflows. Default: None.
out (Tensor, optional) – the output tensor.
返回输入张量在给定维度 dim 中每行的均值。如果 dim 是维度的列表,则对所有维度进行缩减。
如果 keepdim 为 True,则输出张量在除了维度(维度)dim的位置大小与输入相同。否则,dim 被挤压(参见 torch.squeeze()),导致输出张量的维度减少1(或 len(dim))。
torch.nanmean() 计算非nan元素的平均值。

七、MEDIAN
*torch.median(input, dim=-1, keepdim=False, , out=None)
Parameters:
input (Tensor) – the input tensor.
dim (int) – the dimension to reduce.
keepdim (bool) – whether the output tensor has dim retained or not.
Keyword Arguments:
out ((Tensor, Tensor), optional) – The first tensor will be populated with the median values and the second tensor, which must have dtype long, with their indices in the dimension dim of input.
返回一个命名元组 (values, indices),其中 values 包含输入在维度 dim 中每行的中位数,而 indices 包含在维度 dim 中找到的中位数的索引。
默认情况下,dim 是输入张量的最后一个维度。
如果 keepdim 为 True,则输出张量在除了维度 dim 的位置大小与输入相同。否则,dim 被挤压(参见 torch.squeeze()),导致输出张量的维度比输入少 1。
注意:
对于在维度 dim 中元素数为偶数的输入张量,中位数不是唯一的。在这种情况下,返回两个中位数中较小的一个。要计算输入中两个中位数的平均值,请使用 torch.quantile() 并将 q 设为 0.5。
警告:
indices 不一定包含找到的每个中位数值的第一个出现,除非它是唯一的。确切的实现细节是特定于设备的。一般而言,不要期望在 CPU 和 GPU 上运行时获得相同的结果。出于同样的原因,不要期望梯度是确定性的。

torch.nanmedian() 返回输入数据的中值,忽略NAN值
八、NORM
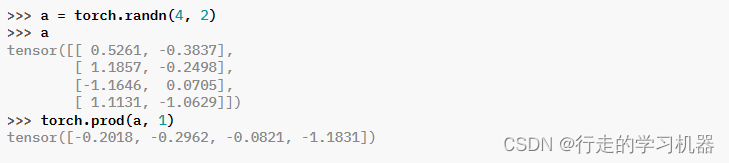
九、PROD
*torch.prod(input, dim, keepdim=False, , dtype=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int) – the dimension to reduce.
keepdim (bool) – whether the output tensor has dim retained or not.
Keyword Arguments:
dtype (torch.dtype, optional) – the desired data type of returned tensor. If specified, the input tensor is casted to dtype before the operation is performed. This is useful for preventing data type overflows. Default: None.
返回给定维度dim中输入张量的每一行的乘积。
十、STD
*torch.std(input, dim=None, , correction=1, keepdim=False, out=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int or tuple of ints) – the dimension or dimensions to reduce.
Keyword Arguments:
correction (int) –
difference between the sample size and sample degrees of freedom. Defaults to Bessel’s correction, correction=1.
keepdim (bool) – whether the output tensor has dim retained or not.
out (Tensor, optional) – the output tensor.
计算沿指定维度 dim 的标准差。dim 可以是单个维度、维度列表或 None(在所有维度上进行缩减)。
标准差(σ)的计算方式是对每个维度的元素进行以下步骤:
- 计算该维度上的平均值(μ)。
- 对每个元素,计算其与平均值的差值,然后取平方。
- 对所有差值的平方求和。
- 将总和除以元素的数量。
- 取结果的平方根,得到标准差。
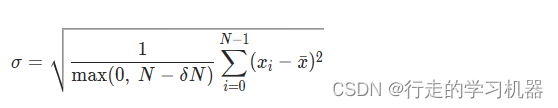
如果 keepdim 为 True,则输出张量在除了维度 dim 的位置大小与输入相同。否则,dim 被挤压(参见 torch.squeeze()),导致输出张量的维度比输入少 1(或 len(dim))。

十一、SUM
**torch.sum(input, dim, keepdim=False, , dtype=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int or tuple of ints, optional) – the dimension or dimensions to reduce. If None, all dimensions are reduced.
keepdim (bool) – whether the output tensor has dim retained or not.
Keyword Arguments:
dtype (torch.dtype, optional) – the desired data type of returned tensor. If specified, the input tensor is casted to dtype before the operation is performed. This is useful for preventing data type overflows. Default: None.
返回给定维度dim中输入张量的每行之和。如果dim是一个维度列表,则对所有维度进行约简。

torch.nansum() 返回所有元素的和,将非数字(nan)视为零。
十二、UNIQUE
torch.unique(input, sorted=True, return_inverse=False, return_counts=False, dim=None) → Tuple[Tensor, Tensor, Tensor]
Parameters:
input (Tensor) – the input tensor
sorted (bool) – Whether to sort the unique elements in ascending order before returning as output.
return_inverse (bool) – Whether to also return the indices for where elements in the original input ended up in the returned unique list.
return_counts (bool) – Whether to also return the counts for each unique element.
dim (int, optional) – the dimension to operate upon. If None, the unique of the flattened input is returned. Otherwise, each of the tensors indexed by the given dimension is treated as one of the elements to apply the unique operation upon. See examples for more details. Default: None
Returns:
A tensor or a tuple of tensors containing
output (Tensor): the output list of unique scalar elements.
inverse_indices (Tensor): (optional) if return_inverse is True, there will be an additional returned tensor (same shape as input) representing the indices for where elements in the original input map to in the output; otherwise, this function will only return a single tensor.
counts (Tensor): (optional) if return_counts is True, there will be an additional returned tensor (same shape as output or output.size(dim), if dim was specified) representing the number of occurrences for each unique value or tensor.
Return type:
(Tensor, Tensor (optional), Tensor (optional))
返回输入张量的唯一元素。
注意:
此函数与 torch.unique_consecutive() 不同,因为此函数还会消除非连续的重复值。
当前在 CUDA 实现和 CPU 实现中,当指定 dim 时,torch.unique 无论 sort 参数如何,都会在开始时对张量进行排序。排序可能会很慢,因此如果您的输入张量已经排序,建议使用 torch.unique_consecutive(),它避免了排序操作。

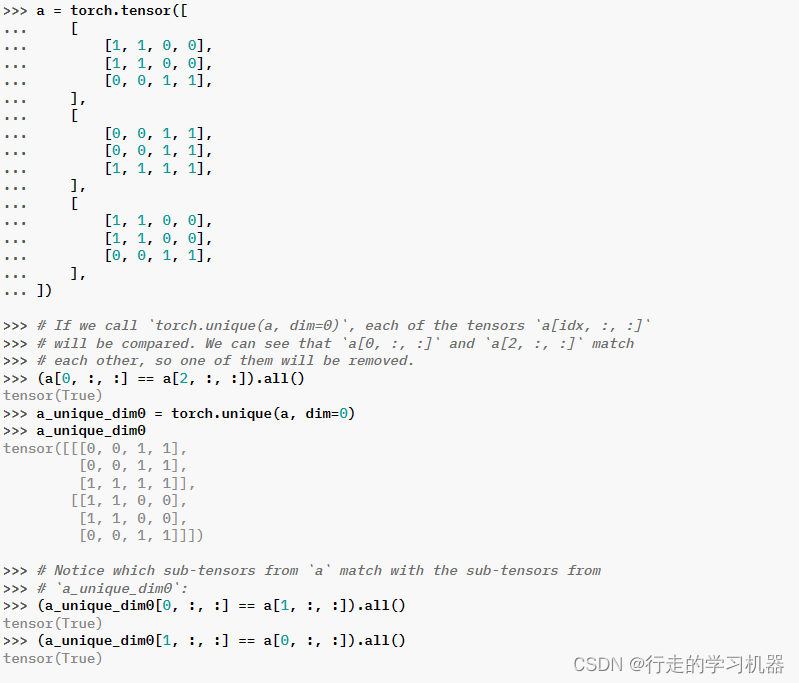
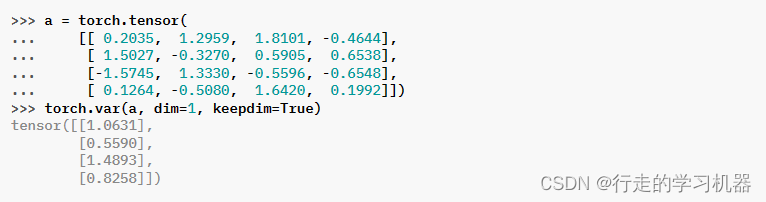
十三、VAR
*torch.var(input, dim=None, , correction=1, keepdim=False, out=None) → Tensor
Parameters:
input (Tensor) – the input tensor.
dim (int or tuple of ints, optional) – the dimension or dimensions to reduce. If None, all dimensions are reduced.
Keyword Arguments:
correction (int) –
difference between the sample size and sample degrees of freedom. Defaults to Bessel’s correction, correction=1.
keepdim (bool) – whether the output tensor has dim retained or not.
out (Tensor, optional) – the output tensor.
计算沿指定维度 dim 的方差。dim 可以是单个维度、维度列表或 None(在所有维度上进行缩减)。计算公式如下: