1.逻辑存储结构

行数据->行->页->区->段->表空间
表空间(ibd文件),一个mysql实例可以对应多个表空间,来存储记录,索引等数据。
段:分为数据段和索引段,回滚段,数据段就是B+树的叶子节点,索引段时B+树的非叶子节点,段用来管理多个extent区。
区:每个区大小是1m,默认下一个页的大小是16k,即一个区有64个连续的页。
页:存储磁盘管理的最小单元,为了保证页的连续性,每次innoDB都会向磁盘申请4-5个区
行:innoDB存储引擎是按行进行存放的
2.架构
innoDB在mysql5.5之后作为默认存储引擎,具有崩溃恢复特性

内存结构
(1)buffer pool:内存中的一个区域,保存磁盘经常操作的真实数据,执行crud时,先操作缓冲池的数据(若缓冲池没有数据,则从磁盘加载并缓存)然后再按一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度。
缓冲池以页为单位,其中的页分为
free page,空闲页,未被使用
clean page,被使用页数据但未被修改
dirty page,脏页,被使用且数据被修改,与磁盘上数据产生不一致
(2)change buffer:更改缓冲区(针对于非唯一二级索引页),即对唯一索引不支持,在执行DML语句时,如果数据不在buffer pool中,不会直接操作磁盘,会把数据变更保存在更改缓冲区里,当数据在未来被读取时,再合并数据恢复到buffer pool中,然后再刷新到磁盘上

(3)Adaptive hash index:自适应哈希索引,优化对buffer pool数据的查询,如果观察到使用hash索引可以提高速度,则会建立hash索引,无需人工干预
(4)log buffer:日志缓冲区,默认大小为16mb,该缓冲区的日志会定期刷新到磁盘,需要更新,插入,删除多行事务时,可以提高日志缓冲区的大小,来节约磁盘IO

磁盘结构
(1)system tablespace:系统表空间是更改缓冲区的存储区域,如果表是在系统表空间文件或通用表空间创建的,它也可能包含表和索引数据
(2)file-per-table-tablespaces:每个表的表空间文件(ibd)包含单个innoDB表的数据和索引,并存储在文件系统上的单个数据文件里
(3)general tablespaces:通用表空间,需要手动create tablespace来创建

(4)undo tablespaces:撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间,初始大小为16MB,用于存储undo log 日志
(5)temporary tablespaces:临时表空间,用于存储用户定义的临时表数据
(6)doublewrite buffer files:双写缓冲区,从buffer pool刷新到磁盘时,会先写入到双写缓冲区中,便于系统异常时恢复数据
(7)redo log:重做日志,实现事务的持久性,由重做日志缓冲区和重做日志文件构成,前者在内存中,后者在磁盘中,事务提交时会把所有的修改信息都存到该日志,用于以后再刷新脏页到磁盘,发生错误时,进行数据恢复,每隔一段时间redo log会自动清理
(8)后台线程:
master thread:核心后台线程。负责调度其他线程,将缓冲池的数据异步刷新到磁盘,包括脏页的刷新,合并插入缓存,undo页的回收
io thread:异步io
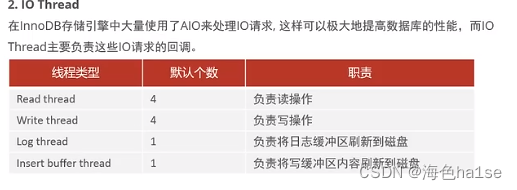
purge thread:回收事务已提交的undo log
page cleaner thread:协助核心线程刷新脏页到磁盘,减轻核心线程负担
3.事务原理

redo log

undo log


undo log 版本链
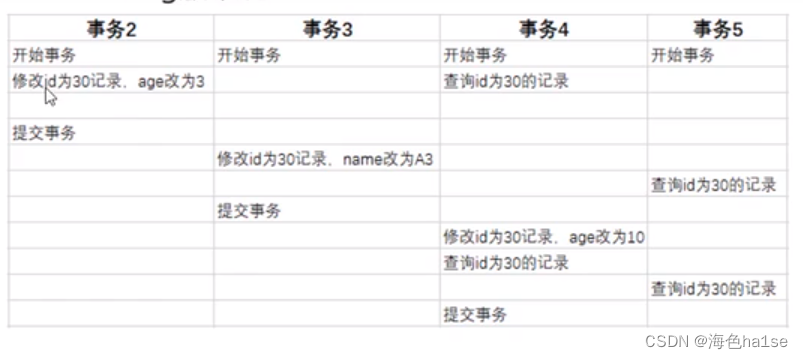
假设有以下四个事务同时开始,事务2修改后,将trx_id设为2,roll_pointer设置1
事务3更新时,trx_id设为3,rollpointer指向2,依次这样,形成一个链表,链表的头部是最新的旧记录,尾部是最旧的旧记录,即undo log 版本链

MVCC:多版本并发控制,即维护一个数据的多个版本,使得读写操作没有冲突
MVCC的实现原理:隐藏字段,undo log版本链,readview



readview,读视图是快照读的依据,记录并维护系统当前活跃事务的id


不同的隔离级别,生成readview的时机不同
RC下:事务每一次执行快照读都会生成readview,以事务5的两次读操作为例,第一次快照读中,事务2以提交,活动事务id为3,4,5,最小事务id = 3,预分配事务id = 最大事务id +1 = 6,创建事务id = 5.第二次快照读中,事务2,事务3以提交,活动事务id = 4,5,最小事务id = 4 ,预分配事务id = 6,创建事务id =5
则按照根据版本链从最新的记录id开始匹配,可得,第一次快照读,读取的是事务2已提交的数据,第二次快照读,读取的是事务3提交的数据
RR下:仅在事务第一次执行快照读时生成readview,后续复用该readview。
即两次快照读,读取的都是事务2提交的数据