文章目录
- 1. 实验节点规划表
- 2. 安装Prometheus
- 3. 安装node_exporter
- 4. 配置prometheus.yml文件
- 5. 安装Grafana
- 6. 安装Altermanager监控告警
采用 "Prometheus+Grafana"的开源监控系统,安装部署K8S集群监控平台。
并使用Altermanager告警插件,配合使用企业微信,实现系统集群监控报警机制。
1. 实验节点规划表
| 主机名称 | IP地址 | 安装组件 |
|---|---|---|
| m1 | 192.168.200.61 | Prometheus+Grafana+Alertmanager+node_exporter |
| m2 | 192.168.200.62 | node_exporter |
| m3 | 192.168.200.63 | node_exporter |
| n1 | 192.168.200.64 | node_exporter |
| n2 | 192.168.200.65 | node_exporter |
| n3 | 192.168.200.66 | node_exporter |
2. 安装Prometheus
在master01节点上执行操作。
- 安装Prometheus
# 下载
wget https://github.com/prometheus/prometheus/releases/download/v2.34.0/prometheus-2.34.0.linux-amd64.tar.gz# 解压
tar -zxvf prometheus-2.34.0.linux-amd64.tar.gz -C /usr/local/# 更名
cd /usr/local/ && mv prometheus-2.34.0.linux-amd64 prometheus && cd prometheus
- 创建prometheus.service配置文件
cat > /usr/lib/systemd/system/prometheus.service << EOF
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus --storage.tsdb.retention=15d --log.level=info
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
- 启动prometheus服务
systemctl daemon-reload && systemctl start prometheus && systemctl enable prometheus && systemctl status prometheus
- 查看prometheus服务进程
netstat -lntp | grep prometheus
3. 安装node_exporter
1 Node Exporter for Prometheus Dashboard CN 0413 ConsulManager自动同步版 dashboard for Grafana | Grafana Labs
其余节点安装操作相同。
- 安装node_exporter
# 下载
wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz# 解压
tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz -C /usr/local/# 更名
cd /usr/local && mv node_exporter-1.3.1.linux-amd64 node_exporter && cd node_exporter
- 启动node_exproter
cat > /usr/lib/systemd/system/node_exporter.service << EOF
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target[Service]
Type=simple
User=root
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
- 启动node_exproter服务
systemctl daemon-reload && systemctl start node_exporter && systemctl enable node_exporter && systemctl status node_exporter
- 查看node_exproter服务进程
ps -ef | grep node_exporter
4. 配置prometheus.yml文件
- 修改prometheus.yml配置文件
[root@m1 prometheus]# cat prometheus.yml
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:- 127.0.0.1:9093# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:- "rules/*.yml"
# - "first_rules.yml"
# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['localhost:9090'] # 如果对本机node_exporter监控,加入,'localhost:9100'- job_name: 'K8S-Masters'#重写了全局抓取间隔时间,由15秒重写成5秒。scrape_interval: 5sstatic_configs:- targets: ['192.168.200.61:9100']- targets: ['192.168.200.62:9100']- targets: ['192.168.200.63:9100']- job_name: 'K8S-Nodes'scrape_interval: 5sstatic_configs:- targets: ['192.168.200.64:9100']- targets: ['192.168.200.65:9100']- targets: ['192.168.200.66:9100']
- 检验prometheus.yml配置是否有效
./promtool check config prometheus.yml
- 重启prometheus服务
systemctl daemon-reload && systemctl restart prometheus && systemctl status prometheus
- 重启node_exporter服务
systemctl daemon-reload && systemctl restart node_exporter && systemctl status node_exporter
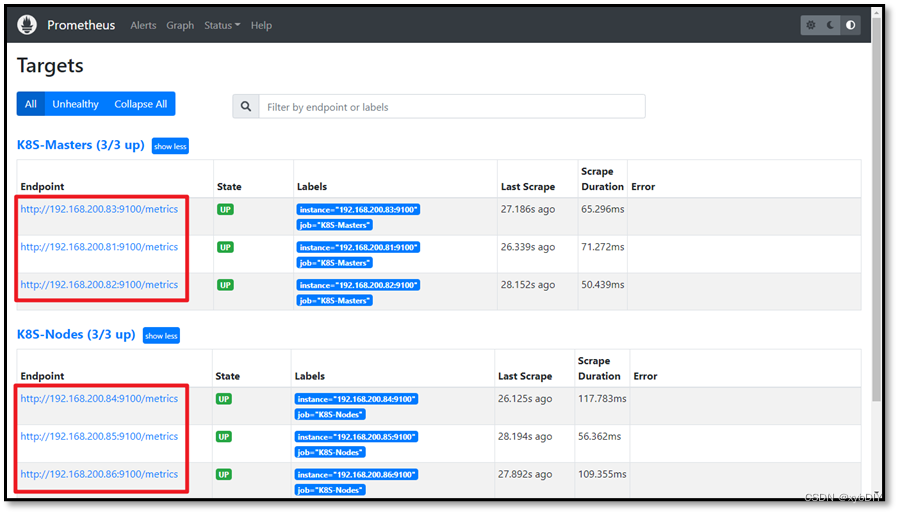
- 访问Prometheus网站
http://192.168.200.61:9090/targets
5. 安装Grafana
在master01节点上执行操作。
- 下载安装Grafana
下载链接:Download Grafana | Grafana Labs
# 下载
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-8.4.5-1.x86_64.rpm# 安装
yum install -y grafana-enterprise-8.4.5-1.x86_64.rpm
- 启动grafana服务
systemctl start grafana-server.service && systemctl enable grafana-server.service && systemctl status grafana-server.service
- 查看grafana进程
netstat -lntp | grep grafana-serve
- 访问Grafana网页,即访问http://192.168.200.61:3000
- 修改密码
- 登录访问Grafana网页
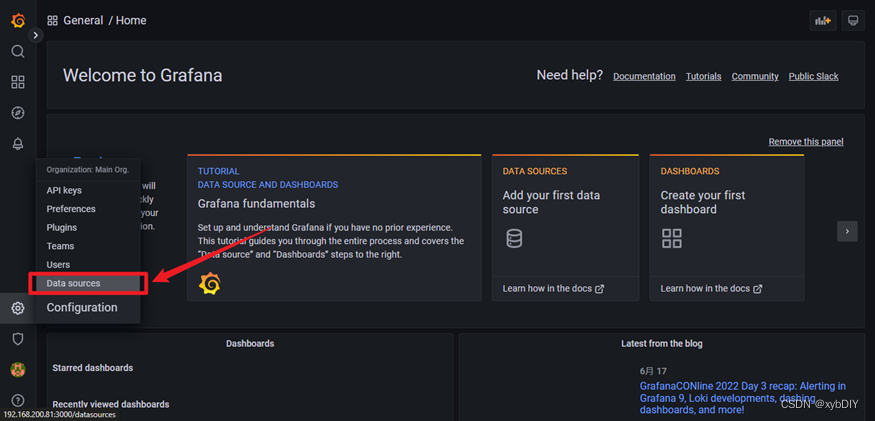
- 添加data sources
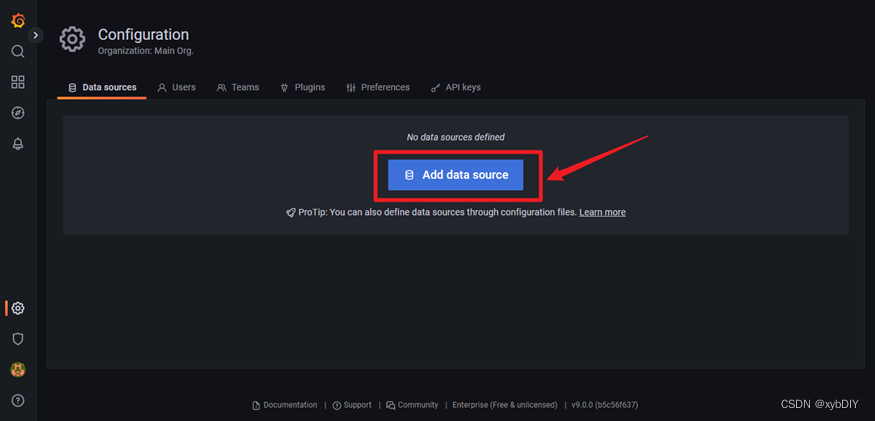
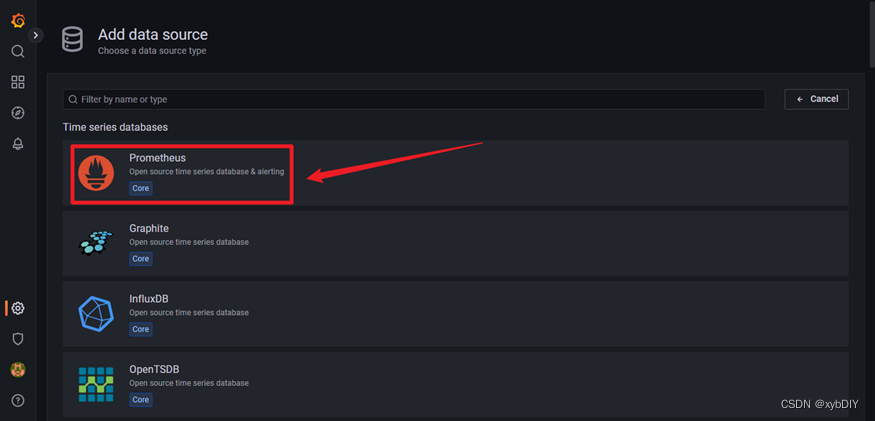
- 选择"Prometheus"
- 添加URL
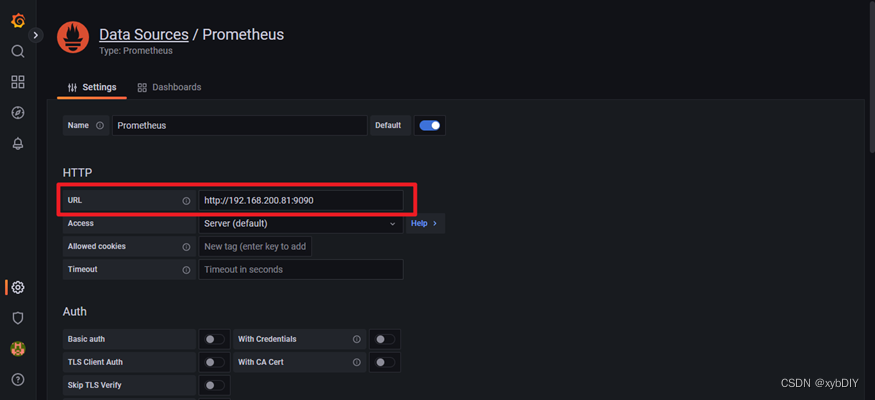
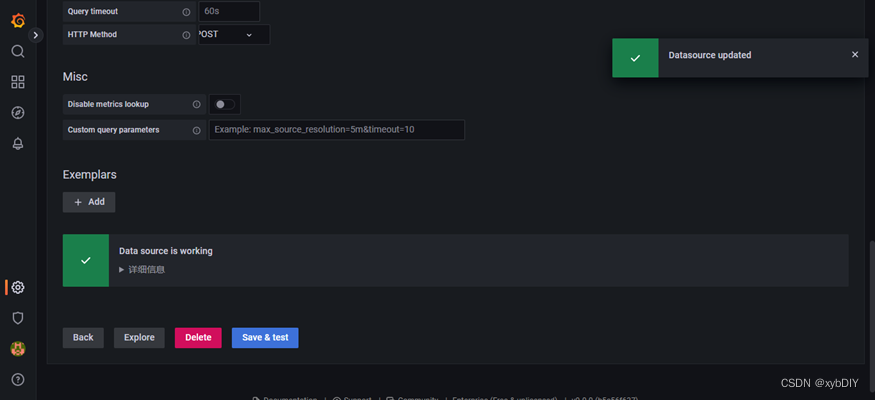
- 保存测试,点击“Save&Test”提示绿色成功。
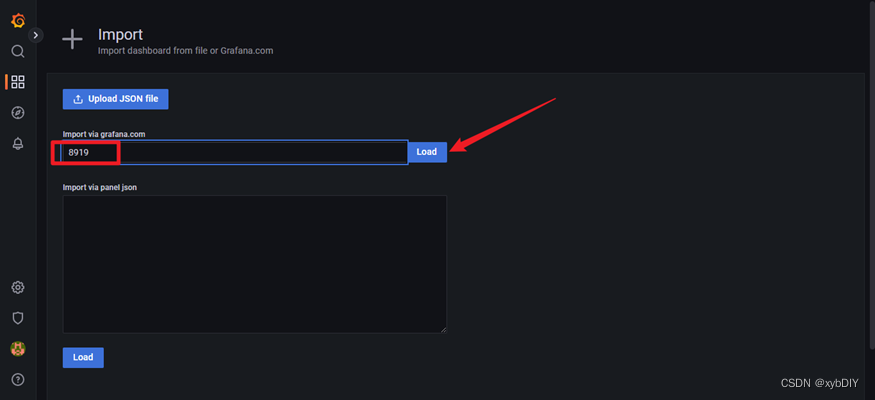
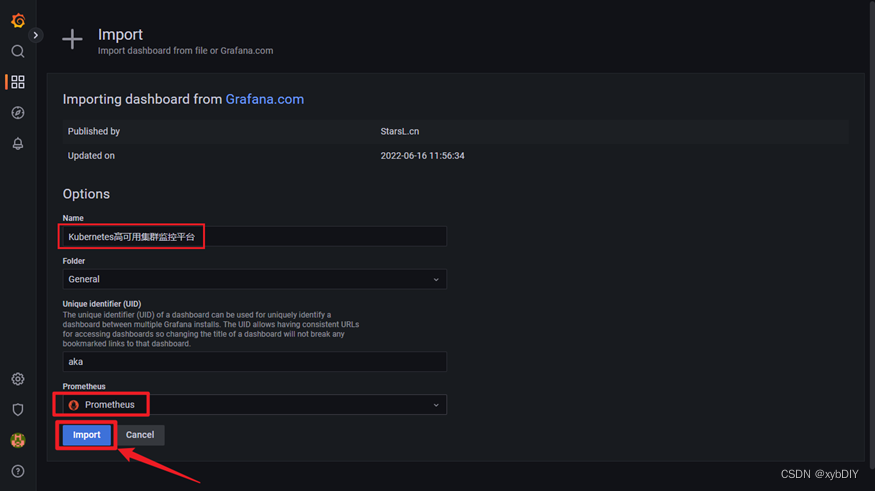
- 配置grafana-node_exporter仪表版

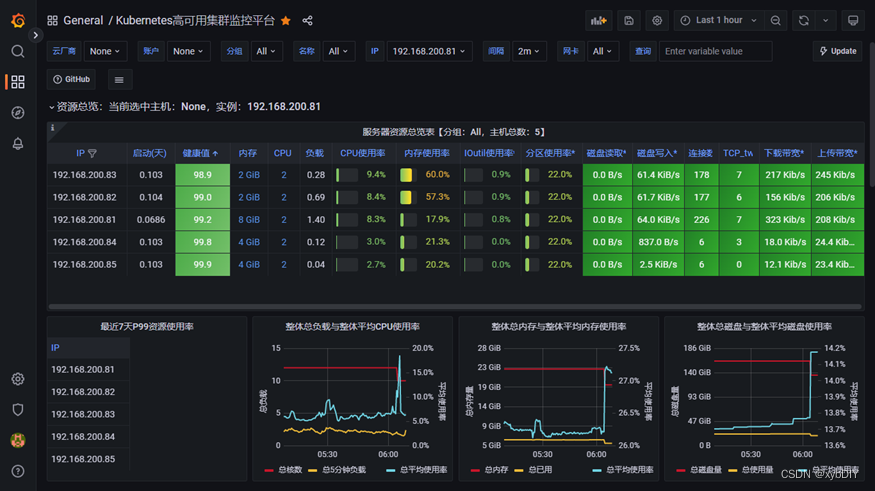
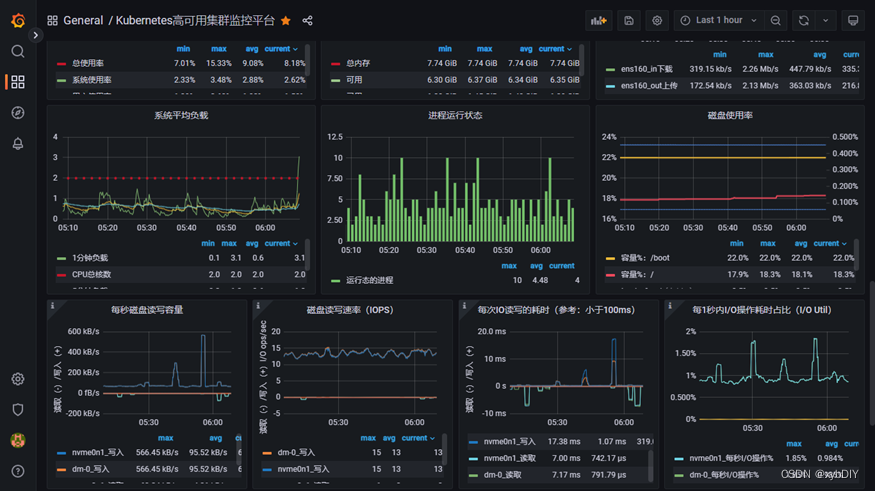
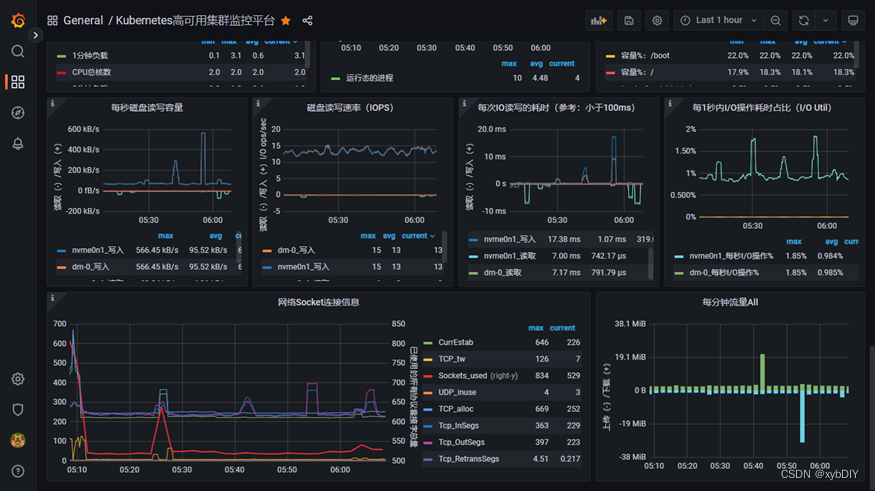
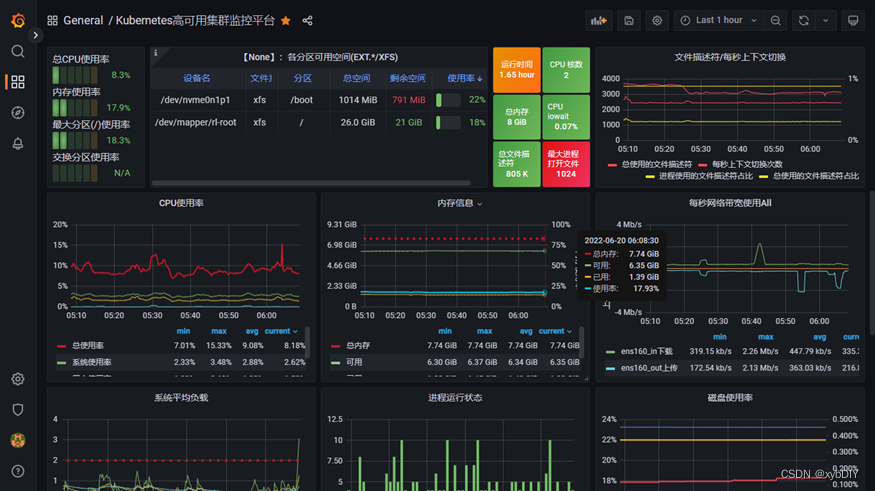
6. 安装Altermanager监控告警
下载地址
Releases · prometheus/alertmanager (github.com)
Download | Prometheus
- 安装Altermanager
# 下载
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz# 解压
tar xvf alertmanager-0.24.0.linux-amd64.tar.gz -C /usr/local/# 更名
cd /usr/local/ && mv alertmanager-0.24.0.linux-amd64 alertmanager && cd alertmanager/
- 登录企业微信
- 获取企业ID:ww9fxxxxxx03000
- 获取部门ID:2
- AgentId:1000003
- Secret:8FZ_LnlwuFKNf6xxxxxxxxxxxxWwVPH8R3ExJvIs
- 获取应用ID
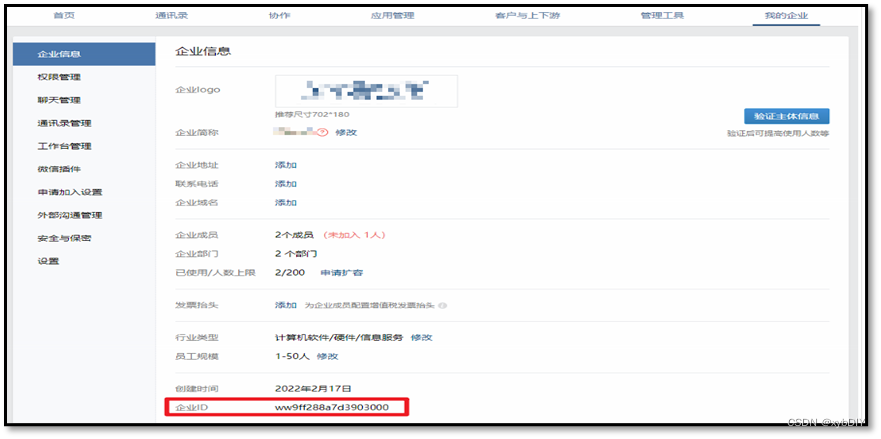
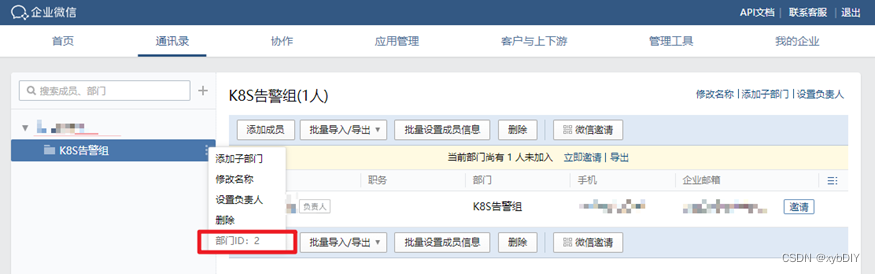
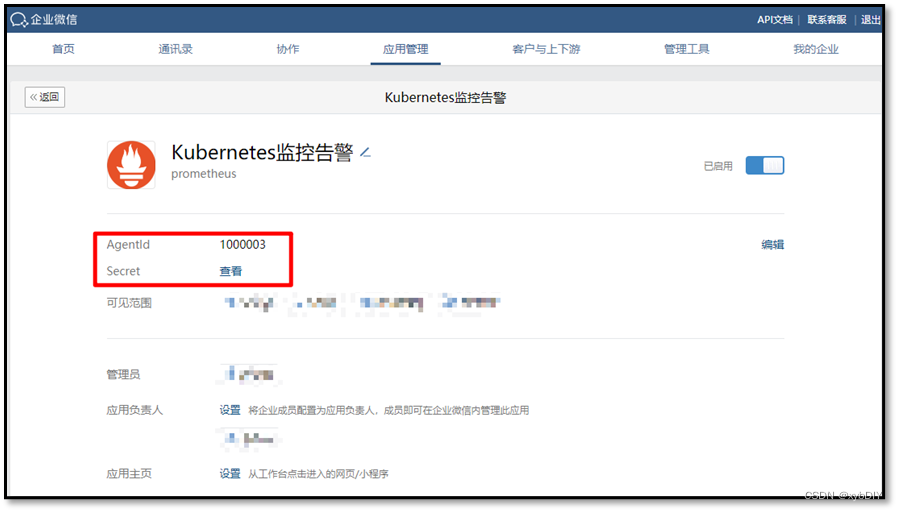

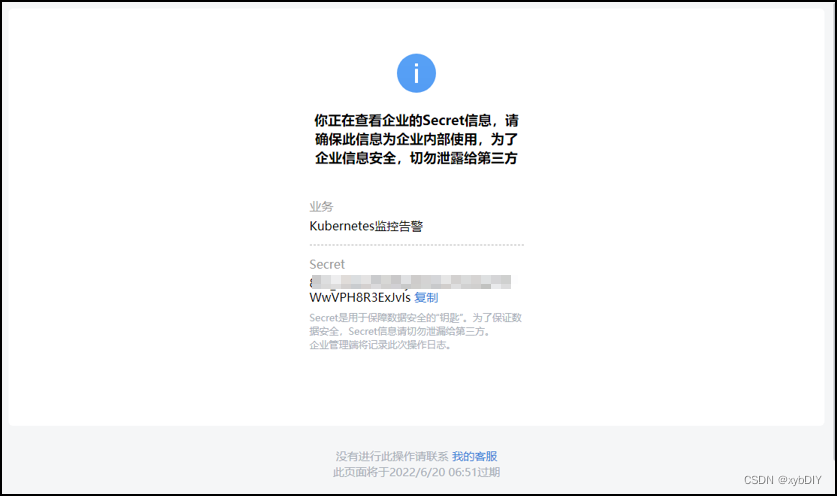
以上步骤完成后,我们就得到了配置Alertmanager的所有信息,包括:企业ID,AgentId,Secret和接收告警的部门id
- 创建wechat.tmpl文件
[root@m1 template]# cat /usr/local/alertmanager/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
=====================
{{- end }}
===告警详情===
告警详情: {{ $alert.Annotations.message }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
===参考信息===
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例ip: {{ $alert.Labels.instance }};{{- end -}}
{{- if gt (len $alert.Labels.namespace) 0 -}}故障实例所在namespace: {{ $alert.Labels.namespace }};{{- end -}}
{{- if gt (len $alert.Labels.node) 0 -}}故障物理机ip: {{ $alert.Labels.node }};{{- end -}}
{{- if gt (len $alert.Labels.pod_name) 0 -}}故障pod名称: {{ $alert.Labels.pod_name }}{{- end }}
=====================
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
=====================
{{- end }}
===告警详情===
告警详情: {{ $alert.Annotations.message }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间: {{ $alert.EndsAt.Format "2006-01-02 15:04:05" }}
===参考信息===
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例ip: {{ $alert.Labels.instance }};{{- end -}}
{{- if gt (len $alert.Labels.namespace) 0 -}}故障实例所在namespace: {{ $alert.Labels.namespace }};{{- end -}}
{{- if gt (len $alert.Labels.node) 0 -}}故障物理机ip: {{ $alert.Labels.node }};{{- end -}}
{{- if gt (len $alert.Labels.pod_name) 0 -}}故障pod名称: {{ $alert.Labels.pod_name }};{{- end }}
=====================
{{- end }}
{{- end }}
{{- end }}
- 编辑alertmanager.yml配置文件
global:resolve_timeout: 1m # 每1分钟检测一次是否恢复wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 请勿修改!!!wechat_api_corp_id: '*************' # 企业微信中企业IDwechat_api_secret: '************************' # 企业微信中创建应用的Secret
templates:- '/usr/local/alertmanager/template/*.tmpl'
route:receiver: 'wechat'group_by: ['env','instance','type','group','job','alertname']group_wait: 10s # 初次发送告警延时group_interval: 10s # 距离第一次发送告警,等待多久再次发送告警repeat_interval: 1h # 告警重发时间
# receiver: 'email'
receivers:
- name: 'wechat'wechat_configs:- send_resolved: truemessage: '{{ template "wechat.default.message" . }}'to_party: '2' # 企业微信中创建的接收告警的部门【K8S告警组】的部门IDagent_id: '1000003' # 企业微信中创建的应用的IDapi_secret: '************************************' # 企业微信中创建应用的Secret
global:resolve_timeout: 1m # 每1分钟检测一次是否恢复wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/' # 请勿修改!!!wechat_api_corp_id: 'ww9ff288a7d3903000' # 企业微信中企业IDwechat_api_secret: '8FZ_LnlwuFKNf6yR8A8svWO0arYYrWwVPH8R3ExJvIs' # 企业微信中创建应用的Secret
templates:- '/usr/local/alertmanager/template/*.tmpl'
route:receiver: 'wechat'group_by: ['env','instance','type','group','job','alertname']group_wait: 10s # 初次发送告警延时group_interval: 3m # 距离第一次发送告警,等待多久再次发送告警repeat_interval: 3m # 告警重发时间
# receiver: 'email'
receivers:
- name: 'wechat'wechat_configs:- send_resolved: true # 是否发出已解决消息to_user: '@all' # 所有用户message: '{{ template "wechat.default.message" . }}'to_party: '2' # 企业微信中创建的接收告警的部门【K8S告警组】的部门IDagent_id: '1000003' # 企业微信中创建的应用的IDapi_secret: '8FZ_LnlwuFKNf6yR8A8svWO0arYYrWwVPH8R3ExJvIs' # 企业微信中创建应用的Secret
- 创建alertmanager.service配置文件。
cat > /usr/lib/systemd/system/alertmanager.service << EOF
[Unit]
Description=alertmanager
Documentation=https://github.com/prometheus/alertmanager
After=network.target[Service]
Type=simple
User=root
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/data/alertmanager
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
- 启动alertmanager.service
systemctl daemon-reload && systemctl start alertmanager.service && systemctl enable alertmanager.service
- 修改prometheus.yml配置文件
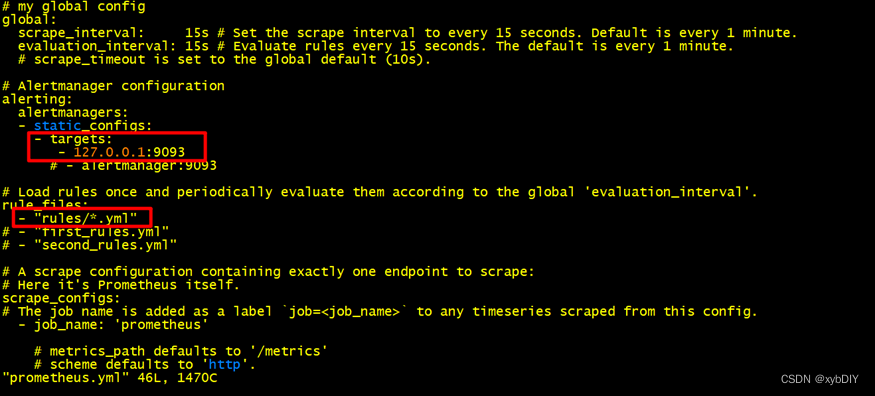
- 在prometheus/rules路径下创建node_status.yml
# 创建rules目录并进入
mkdir /usr/local/prometheus/rules && cd rules/ # 创建node_status.yml配置文件
cat node_status.yml
groups:
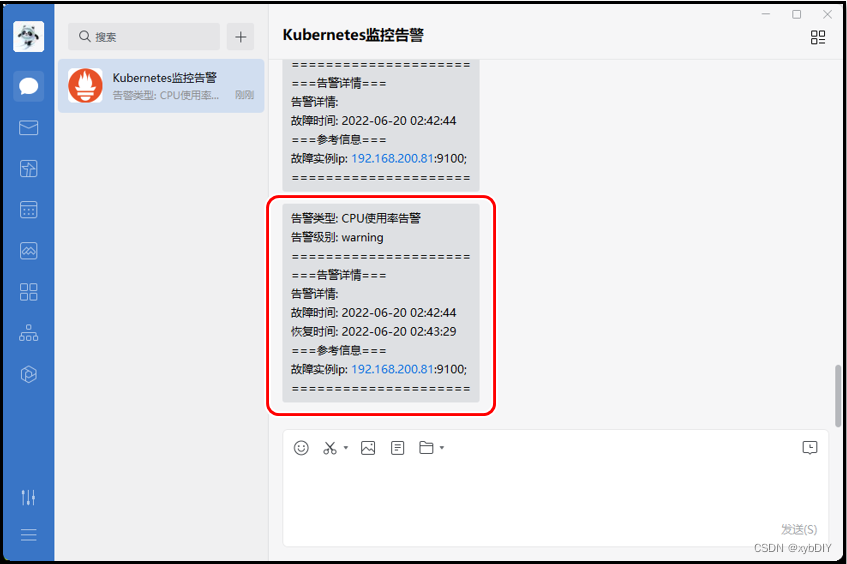
- name: 实例存活告警规则rules:- alert: 实例存活告警expr: up{job="prometheus"} == 0 or up{job="K8S-Nodes"} == 0for: 1mlabels:user: rootseverity: Disasterannotations:summary: "Instance {{ $labels.instance }} is down"description: "Instance {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."value: "{{ $value }}"- name: 内存告警规则rules:- alert: "内存使用率告警"expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 75for: 1mlabels:user: rootseverity: warningannotations:summary: "服务器: {{$labels.alertname}} 内存报警"description: "{{ $labels.alertname }} 内存资源利用率大于75%!(当前值: {{ $value }}%)"value: "{{ $value }}"- name: CPU报警规则rules:- alert: CPU使用率告警expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 70for: 1mlabels:user: rootseverity: warningannotations:summary: "服务器: {{$labels.alertname}} CPU报警"description: "服务器: CPU使用超过70%!(当前值: {{ $value }}%)"value: "{{ $value }}"- name: 磁盘报警规则rules:- alert: 磁盘使用率告警expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80for: 1mlabels:user: rootseverity: warningannotations:summary: "服务器: {{$labels.alertname}} 磁盘报警"description: "服务器:{{$labels.alertname}},磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"value: "{{ $value }}"
- 检验alertmanager.yml文件是否配置正确
./amtool check-config alertmanager.yml
输出结果
[root@m1 alertmanager]# pwd
/usr/local/alertmanager
[root@m1 alertmanager]# ./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:- global config- route- 0 inhibit rules- 1 receivers- 1 templatesSUCCESS
- 启动alertmanager服务
systemctl daemon-reload && systemctl start alertmanager && systemctl enable alertmanager && systemctl status alertmanager
- 查看alertmanager服务进程是否启动
ps -ef | grep alertmanager
- 重启prometheus服务
systemctl daemon-reload && systemctl restart prometheus && systemctl status prometheus
- 访问http://192.168.200.61:9090/alerts ,可以查看相关规则信息。
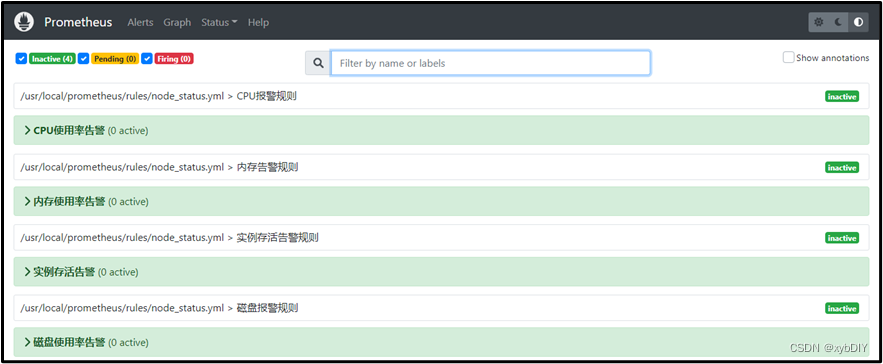
至此,企业Prometheus对接企业微信告警部署完毕,出现故障时就能看到如下告警信息和恢复信息了。
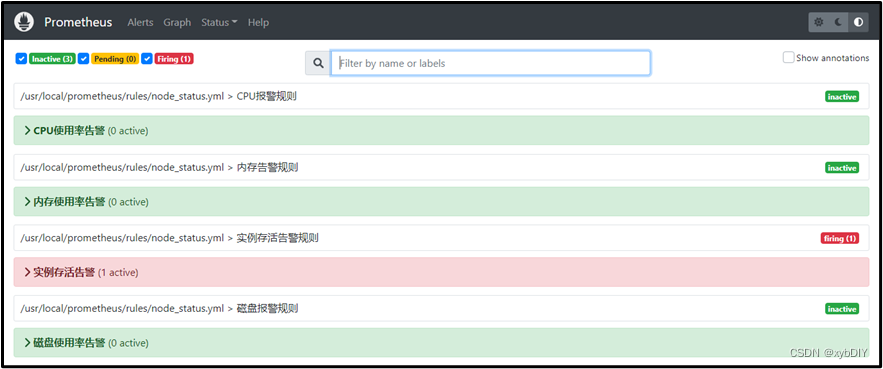
此时,模拟其中一台主机宕机,查看配置的告警信息在企业微信中是否生效。
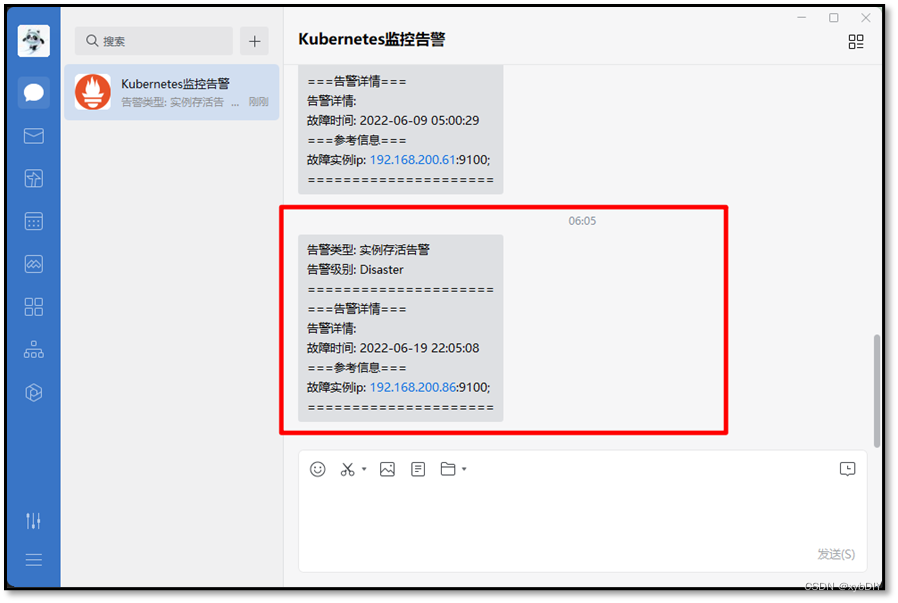
- 查看到实例存活告警,发现其中一个主机宕机
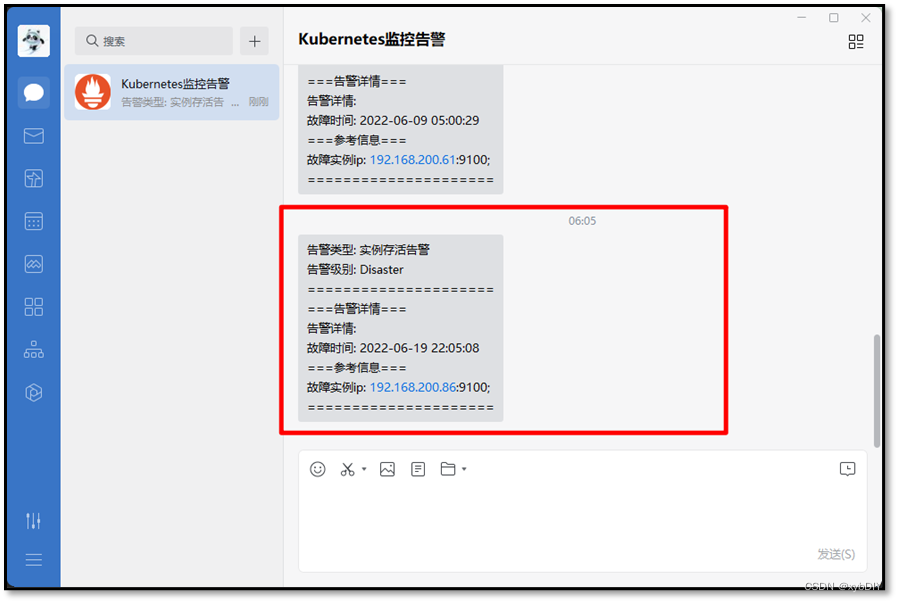
- 查看企业微信发出告警信息