我们之前分别从 Linux Namespace 的隔离能力、Linux Cgroups 的限制能力,以及基于 rootfs 的文件系统三个角度来理解了一下关于容器的核心实现原理。
这里一定注意说的是Linux环境,因为Linux Docker (namespaces + cgroups + rootfs) != Docker on Mac (based on virtualization) != Windows Docker (based on virtualization, Hyper-V)。mac和win上面那都是虚拟化技术,不是容器技术。
这次我们实际操作一下Docker来进一步理解一下其中的概念。
一、创建一个java项目
因为我大部分都是做的java开发,所以这里就以java项目来实现操作,而我直接依赖于springboot简单方便的创建一个web项目。下面是主要的文件。
1、pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.4.RELEASE</version><relativePath/></parent><groupId>com.levi</groupId><artifactId>springboot_demo</artifactId><version>0.0.1-SNAPSHOT</version><name>springboot_demo</name><description>Demo project for Spring Boot</description><properties><java.version>11</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency></dependencies><build><plugins><!-- 指定编译器版本为 11 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><release>11</release></configuration></plugin><!-- 指定运行时环境版本为 11 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>3.0.0-M5</version><configuration><argLine>--illegal-access=permit</argLine><argLine>--enable-preview</argLine></configuration></plugin><!--避免找不到主类文件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>2、application.propertities文件
# 应用名称
spring.application.name=springboot_demo
# 应用服务 WEB 访问端口
server.port=8080
3、controller文件
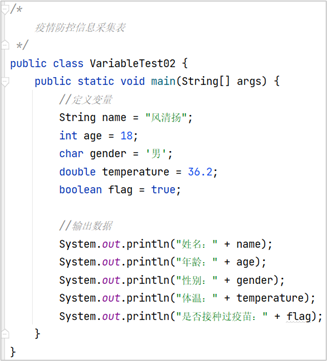
@RestController
public class HelloController {@Autowiredprivate Environment environment;@GetMapping("/getInfo")public String getInfo() throws UnknownHostException {StringBuilder sb = new StringBuilder();// 获取环境中的NAME变量,如果有这个变量就输出Hello,否则就输出Hello World!String name = environment.getProperty("NAME");if (name != null) {sb.append("Hello ").append(name).append("! ");} else {sb.append("Hello world! ");}// 一起把hostname输出sb.append("Hostname: ").append(InetAddress.getLocalHost().getHostName());return sb.toString();}
}
此时一个springboot的wen项目就创建好了,我们本地测试一下,启动起来。访问localhost:8080/getInfo地址,返回如下,表示成功。因为我本地没配置NAME属性,所以输出Hello world!,而我本机name就是叫YX。所以符合预期。

然后maven打jar包为,springboot_demo-0.0.1-SNAPSHOT.jar。
二、编写Dockerfile
创建名为Dockerfile的文件
# 容器环境为jdk11
FROM openjdk:11-jre-slim# 切换工作目录到 /app
WORKDIR /app# 将当前目录下的所有内容复制到/app下
ADD . /app# 暴露端口号
EXPOSE 8080# 设置环境变量
ENV NAME World# 启动 Spring Boot 应用程序
CMD ["java", "-jar", "springboot_demo-0.0.1-SNAPSHOT.jar"]
OK我们现在编写好了,至于每一项是什么内容,待会再说。
三、创建镜像,启动容器,访问接口
此时我们把Dockerfile文件和jar包一起上传到服务器上。如下:

然后进入这个目录,执行命令创建镜像。
# 创建镜像,并且命名为myapp
docker build -t myapp ./# 启动容器,并且把容器内服务的端口8080映射出来为8080,这样我们就能在容器外访问了
docker run -p 8080:8080 myapp
OK,此时容器启动了,对应的容器内的服务也启动了。此时我们访问接口:记得什么防火墙,端口访问开启,都开开。
http://服务器ip地址:8080/getInfo
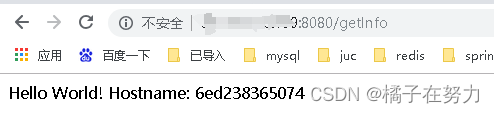
此时我们操作容器就成功了,下面我们来分析一下。
四、分析Dockerfile
1、创建Dockerfile
我们的一切开始都是基于这个Dockerfile来创建的镜像和容器,我们先来看看这个文件,
FROM openjdk:11-jre-slim# 切换工作目录到 /app
WORKDIR /app# 将当前目录下的所有内容复制到/app下
ADD . /app# 暴露端口号
EXPOSE 8080# 设置环境变量
ENV NAME World# 启动 Spring Boot 应用程序
CMD ["java", "-jar", "springboot_demo-0.0.1-SNAPSHOT.jar"]
通过这个文件的内容,你可以看到 Dockerfile 的设计思想,是使用一些标准的原语(即大写高亮的词语),描述我们所要构建的 Docker 镜像。
并且这些原语,都是按顺序处理的。比如 FROM 原语,指定了我们使用的java环境的基础镜像,从而免去了安装 java语言环境的操作。否则我们还要在文件里写安装jdk的命令。
RUN 原语就是在容器里执行 shell 命令的意思。我们这里没用到。
而 WORKDIR,意思是在这一句之后,Dockerfile 后面的操作都以这一句指定的 /app 目录作为当前目录。
ADD . /app是把所有文件都复制到app目录下,指的是Dockerfile所在的目录,也就是我们的Linux机器的目录,此时jar包就拷贝到了app目录下了。
所以,到了最后的 CMD,意思是 Dockerfile 指定 的这个容器的进程。这里,springboot_demo-0.0.1-SNAPSHOT.jar 的实际路径是 /app/springboot_demo-0.0.1-SNAPSHOT.jar,因为已经切换到了当前目录。此时就进入这个目录执行这个jar包。
另外,在使用 Dockerfile 时,你可能还会看到一个叫作 ENTRYPOINT 的原语。实际上,它和 CMD 都是 Docker 容器进程启动所必需的参数,完整执行格式是:“ENTRYPOINT CMD”。
但是,默认情况下,Docker 会为你提供一个隐含的 ENTRYPOINT,即:/bin/sh -c。所以,在不指定 ENTRYPOINT 时,比如在我们这个例子里,实际上运行在容器里的完整进程是:/bin/sh -c “springboot_demo-0.0.1-SNAPSHOT.jar”,即 CMD 的内容就是 ENTRYPOINT 的参数。
基于以上原因,我们后面会统一称 Docker 容器的启动进程为 ENTRYPOINT,而不是 CMD。
需要注意的是,Dockerfile 里的原语并不都是指对容器内部的操作。就比如 ADD,它指的是把当前目录(即 Dockerfile 所在的目录)里的文件,复制到指定容器内的目录当中。
以上就是我们对于Dockerfile的解释。在理解了这个之后,我们来看下下一句。
2、创建镜像命令
docker build -t myapp ./
其中,-t 的作用是给这个镜像加一个 Tag,即:起一个好听的名字。docker build 会自动加载当前目录下的 Dockerfile 文件,然后按照顺序,执行文件中的原语。而这个过程,实际上可以等同于 Docker 使用基础镜像启动了一个容器,然后在容器中依次执行 Dockerfile 中的原语。需要注意的是,Dockerfile 中的每个原语执行后,都会生成一个对应的镜像层。即使原语本身并没有明显地修改文件的操作(比如,ENV 原语),它对应的层也会存在。只不过在外界看来,这个层是空的。
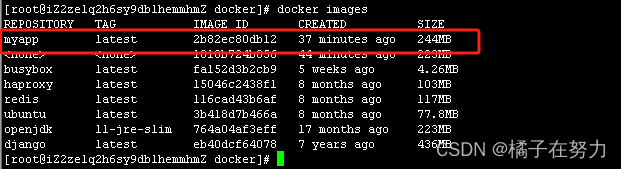
docker build 操作完成后,我可以通过 docker images 命令查看结果:
3、通过镜像,启动容器
docker run -p 8080:8080 myapp
在这一句命令中,镜像名 myapp后面,我什么都不用写,因为在 Dockerfile 中已经指定了 CMD。否则,我就得把进程的启动命令加在后面:
$ docker run -p 8080:8080 myapp java -jar springboot_demo-0.0.1-SNAPSHOT.jar
容器启动之后,我可以使用 docker ps 命令看到:

同时,我已经通过 -p 8080:8080 告诉了 Docker,请把容器内的 8080 端口映射在宿主机的 8080 端口上。这样做的目的是,只要访问宿主机的8080 端口,我就可以看到容器里应用返回的结果:
否则,我就得先用 docker inspect 命令查看容器的 IP 地址,然后访问“http://< 容器 IP 地址 >:8080”才可以看到容器内应用的返回。至此,我已经使用容器完成了一个应用的开发与测试,如果现在想要把这个容器的镜像上传到 DockerHub 上分享给更多的人,我要怎么做呢?
实际上这个和你使用的方式有关系,这个具体的和DockerHub的交互操作就这里不说了,因为企业里面都是自己部署的仓库,一般不直接和docker官方的仓库打交道,所以我们后面搭起来k8s集群的时候,部署自己的镜像仓库比如Harbor项目搭建的仓库,后面们再说如何保存镜像,如何通过容器保存镜像,如何load push等操作,实际这些操作都很简单,随便找一个资料都能操作。我们下面来说一个问题。
五、和容器交互exec
当容器启动之后,此时就等于我们的服务也跟着启动了,实际上你完全可以把这个容器就当成服务,他们就是一个东西。
那么此时我们如何想和docker容器交互一下呢,或者更通俗一点,我想进入这个容器看一下我的服务呢,以前物理机部署,直接就操作了,现在你在物理机只能看到容器。此时我们需要和容器进行交互。我们需要请出一个命令exec。这里顺便分享一个学习操作docker的习惯,就是看文档。
来吧,这里我稍微示范一下,其实大家估计都会,我就班门弄斧一下。
1、当你不会docker,怎么使用文档
在任何位置输入docker,就会出现文档。
此时我们就确定了,嗯,我们是用exec这个指令来交互,然后进一步,你就可以docker exec --help来进一步看这个指令。
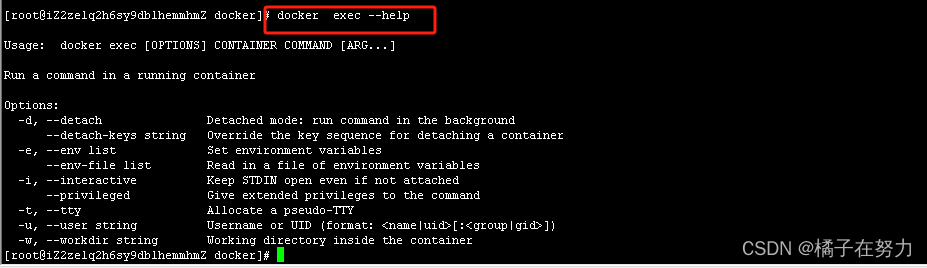
# docker exec --help
# 这里他的使用格式就是docker exec 选项 容器id/名字 进入容器后的指令 以及详细的参数
Usage: docker exec [OPTIONS] CONTAINER COMMAND [ARG...]Run a command in a running containerOptions:-d, --detach Detached mode: run command in the background--detach-keys string Override the key sequence for detaching a container-e, --env list Set environment variables--env-file list Read in a file of environment variables-i, --interactive Keep STDIN open even if not attached--privileged Give extended privileges to the command-t, --tty Allocate a pseudo-TTY-u, --user string Username or UID (format: <name|uid>[:<group|gid>])-w, --workdir string Working directory inside the container
我们来逐句分析
1、使用格式
用格式就是docker exec 选项 容器id/名字 进入容器后的指令 以及详细的参数
Usage: docker exec [OPTIONS] CONTAINER COMMAND [ARG…]
我知道你看完就懵逼了,不要急,接着看。
2、下面就是options:
这个option就是第一个格式里面的那个选项,你看他列出这几个。我们就挑今天有用的来说。
# 即使未连接STDIN(标准输入)也保持打开状态,分配一个交互终端,我们不就是要交互吗,没毛病 -i, --interactive Keep STDIN open even if not attached--privileged Give extended privileges to the command 赋予权限
# 分配一个伪tty设备,可以支持终端登录,就是登录进去容器里面的系统,容器内部自成世界-t, --tty Allocate a pseudo-TTY
所以我们就知道了:
docker exec [OPTIONS] CONTAINER COMMAND [ARG…]这个启动公式的OPTIONS就能被-i -t代替了,一般都直接写-it
变成了docker exec -it CONTAINER COMMAND [ARG…]
而容器id我们直接docker ps 就能看到,这个也可以拿到变为假如我这里是6ed238365074
docker exec -it 6ed238365074 COMMAND [ARG…]
而COMMAND就是你进入容器之后干嘛,我们进去当然是想和shell交互了,那就打开shell
于是变为
docker exec -it 16ed238365074 /bin/sh [ARG…]
后面的参数目前我们不用,他本身也加了中括号,可选的那就不加了。于是我们就变为这样。
docker exec -it 6ed238365074 /bin/sh ,我们来试试。你能看到此时就进入容器了,我们的文件就在里面,而且当前目录正是我们指定的工作目录/app
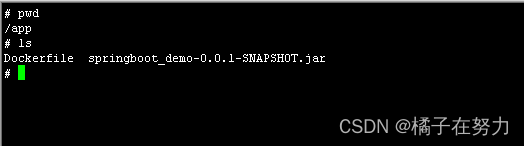
2、docker exec 是怎么做到进入容器里的呢?
好的,我们已经进入容器了使用exec命令,那是怎么进入的呢,我们这里来想一下。
实际上,Linux Namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 Namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在。
比如,通过如下指令,你可以看到当前正在运行的 Docker 容器的进程号(PID)是 21408:注意是容器进程,就是这个容器运行在宿主机的进程号,我们之前说过,宿主机通过namespece隔离起来,容器内部看到的进程号永远是1,但是实际在宿主机还是有自己真实的进程ID。这里就是这个ID。
$ docker inspect --format '{{ .State.Pid }}' 4ddf4638572d
21408
这时,你可以通过查看宿主机的 proc 文件,看到这个 21408进程的所有 Namespace 对应的文件:
[root@iZ2ze1q2h6sy9dblhemmhmZ docker]# ls -l /proc/21408/ns
total 0
lrwxrwxrwx 1 root root 0 Jan 17 12:40 ipc -> ipc:[4026532223]
lrwxrwxrwx 1 root root 0 Jan 17 12:40 mnt -> mnt:[4026532221]
lrwxrwxrwx 1 root root 0 Jan 17 12:39 net -> net:[4026532226]
lrwxrwxrwx 1 root root 0 Jan 17 12:40 pid -> pid:[4026532224]
lrwxrwxrwx 1 root root 0 Jan 17 13:01 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Jan 17 12:40 uts -> uts:[4026532222]
可以看到,一个进程的每种 Linux Namespace,都在它对应的 /proc/[进程号]/ns 下有一个对应的虚拟文件,并且链接到一个真实的 Namespace 文件上。有了这样一个可以“hold 住”所有 Linux Namespace 的文件,我们就可以对 Namespace 做一些很有意义事情了,比如:加入到一个已经存在的 Namespace 当中。
这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
而如何加入呢?
这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用。它的调用方法,我可以用如下一段小程序为你说明:
#define _GNU_SOURCE
#include <fcntl.h>
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE);} while (0)int main(int argc, char *argv[]) {int fd;fd = open(argv[1], O_RDONLY);if (setns(fd, 0) == -1) {errExit("setns");}execvp(argv[2], &argv[2]); errExit("execvp");
}
这段代码功能非常简单:它一共接收两个参数,第一个参数是 argv[1],即当前进程要加入的 Namespace 文件的路径,比如 /proc/21408/ns/net;而第二个参数,则是你要在这个 Namespace 里运行的进程,比如 /bin/bash。
这段代码的核心操作,则是通过 open() 系统调用打开了指定的 Namespace 文件,并把这个文件的描述符 fd 交给 setns() 使用。在 setns() 执行后,当前进程就加入了这个文件对应的 Linux Namespace 当中了。
概括来说就是docker exec的原理,具体一点就是使用linux系统指令setns将进程加入到一个容器进程的namespace,从而“进入”容器,也就是找到proc的namespace信息,并加入进程。
现在,你可以编译执行一下这个程序,加入到容器进程(PID=21408)的 Network Namespace 中:
$ gcc -o set_ns set_ns.c
$ ./set_ns /proc/21408/ns/net /bin/bash
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02 inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0inet6 addr: fe80::42:acff:fe11:2/64 Scope:LinkUP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1RX packets:12 errors:0 dropped:0 overruns:0 frame:0TX packets:10 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:0 RX bytes:976 (976.0 B) TX bytes:796 (796.0 B)lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0inet6 addr: ::1/128 Scope:HostUP LOOPBACK RUNNING MTU:65536 Metric:1RX packets:0 errors:0 dropped:0 overruns:0 frame:0TX packets:0 errors:0 dropped:0 overruns:0 carrier:0collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
正如上所示,当我们执行 ifconfig 命令查看网络设备时,我会发现能看到的网卡“变少”了:只有两个。而我的宿主机则至少有四个网卡。这是怎么回事呢?因为被隔离到单独的net ns里了,下面我们分析一下。
实际上,在 setns() 操作之后我看到的这两个网卡,正是我在前面启动的 Docker 容器里的网卡。也就是说,我新创建的这个 /bin/bash 进程,由于加入了该容器进程(PID=21408)的 Network Namepace,它看到的网络设备与这个容器里是一样的,即:/bin/bash 进程的网络设备视图,也被修改了。而一旦一个进程加入到了另一个 Namespace 当中,在宿主机的 Namespace 文件上,也会有所体现。在宿主机上,你可以用 ps 指令找到这个 set_ns 程序执行的 /bin/bash 进程,其真实的 PID 是 28807:
# 在宿主机上
ps aux | grep /bin/bash
root 28807 0.0 0.0 19944 3612 pts/0 S 14:15 0:00 /bin/bash
这时,如果按照前面介绍过的方法,查看一下这个 PID=28807 的进程的 Namespace,你就会发现这样一个事实:
$ ls -l /proc/28807/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:18 /proc/28807/ns/net -> net:[4026532226]$ ls -l /proc/21408/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:05 /proc/21408/ns/net -> net:[4026532226]
在 /proc/[PID]/ns/net 目录下,这个 PID=28807进程,与我们前面的 Docker 容器进程(PID=21408)指向的 Network Namespace 文件完全一样。这说明这两个进程,共享了这个名叫 net:[4026532226]的 Network Namespace。
此外,Docker 还专门提供了一个参数,可以让你启动一个容器并“加入”到另一个容器的 Network Namespace 里,这个参数就是 -net,比如:
$ docker run -it --net container:4ddf4638572d busybox ifconfig
这样,我们新启动的这个容器,就会直接加入到 ID=4ddf4638572d 的容器,也就是我们前面的创建的 java 应用容器(PID=21408)的 Network Namespace 中。所以,这里 ifconfig 返回的网卡信息,跟我前面那个小程序返回的结果一模一样,你也可以尝试一下。
而如果我指定–net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。
做了这么多其实就是想说exec就是在宿主机上启动一个进程,然后通过setns()函数操作,加入宿主机上保存的namespace的本地文件,可以进入到目标容器的namespace中,并与之共享namespace。达到进入容器的概念。
六、使用容器创建镜像
这个操作就是docker commit ,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像。
当然,下面这些只读层在宿主机上是共享的,不会占用额外的空间。而由于使用了联合文件系统,你在容器里对镜像 rootfs 所做的任何修改,都会被操作系统先复制到这个可读写层,然后再修改。这就是所谓的:Copy-on-Write。
而正如前所说,Init 层的存在,就是为了避免你执行 docker commit 时,把 Docker 自己对 /etc/hosts 等文件做的修改,也一起提交掉。有了新的镜像,我们就可以把它推送到 仓库上了:
说的简单一点,就是我们在一个容器启动之后,我们在容器里面通过exec进入加了一些内容比如创建了一个配置文件,这时候我们提交镜像是可以打包进去的。但是对于一些环境变量的修改则不会被提交,因为他们在init层。这样是因为下次使用这个镜像创建出来的容器不会有环境变量的影响。
专门用来存放 /etc/hosts、/etc/resolv.conf,修改往往只对当前的容器有效,执行 docker commit 时不会提交。
再简单理解一下就是,需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。但是这些修改往往只对当前的容器有效,并不会执行 docker commit 时,把这些信息连同可读写层一起提交掉。
七、Volume数据卷
我们知道容器技术使用了 rootfs 机制和 Mount Namespace,构建出了一个同宿主机完全隔离开的文件系统环境。这时候,我们就需要考虑这样两个问题:
1、容器里进程新建的文件,怎么才能让宿主机获取到?
2、宿主机上的文件和目录,怎么才能让容器里的进程访问到?
这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
在 Docker 项目里,它支持两种 Volume 声明方式,可以把宿主机目录挂载进容器的 /test 目录当中:
$ docker run -v /test ...
$ docker run -v /home:/test ...
而这两种声明方式的本质,实际上是相同的:都是把一个宿主机的目录挂载进了容器的 /test 目录。只不过,在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。
那么,Docker 又是如何做到把一个宿主机上的目录或者文件,挂载到容器里面去呢?
之前我们说过,当容器进程被创建之后,尽管开启了 Mount Namespace,但是在它执行 chroot(或者 pivot_root)之前,容器进程一直可以看到宿主机上的整个文件系统。而宿主机上的文件系统,也自然包括了我们要使用的容器镜像。这个镜像的各个层,保存在 /var/lib/docker/aufs/diff 目录下,在容器进程启动后,它们会被联合挂载在 /var/lib/docker/aufs/mnt/ 目录中,这样容器所需的 rootfs 就准备好了。
所以,我们只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。更重要的是,由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。宿主机看不到各个容器的挂载,他只管理宿主机的挂载,容器内部他们各自管理,各个容器之间不会因为宿主机的操作影响,因为宿主机都看不到。
注意:这里提到的"容器进程",是 Docker 创建的一个容器初始化进程 (dockerinit),而不是应用进程 (ENTRYPOINT + CMD)。dockerinit 会负责完成根目录的准备、挂载设备和目录、配置 hostname 等一系列需要在容器内进行的初始化操作。最后,它通过 execv() 系统调用,让应用进程取代自己,成为容器里的 PID=1 的进程。
dockerinit是容器自己启动的进程,ENTRYPOINT + CMD运行容器内部服务的(这里存疑,后面再研究)。
参考文章,https://www.cnblogs.com/mayongjie/p/17130433.html
而这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。其实,如果你了解 Linux 内核的话,就会明白,绑定挂载实际上是一个 inode 替换的过程。在 Linux 操作系统中,inode 可以理解为存放文件内容的“对象”,而 dentry,也叫目录项,就是访问这个 inode 所使用的“指针”。
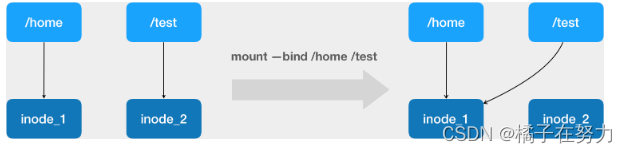
正如上图所示,mount --bind /home /test,会将 /home 挂载到 /test 上。其实相当于将 /test 的 dentry,重定向到了 /home 的 inode。这样当我们修改 /test 目录时,实际修改的是 /home 目录的 inode。这也就是为何,一旦执行 umount 命令,/test 目录原先的内容就会恢复:因为修改真正发生在的,是 /home 目录里。
所以,在一个正确的时机,进行一次绑定挂载,Docker 就可以成功地将一个宿主机上的目录或文件,不动声色地挂载到容器中。这样,进程在容器里对这个 /test 目录进行的所有操作,都实际发生在宿主机的对应目录(比如,/home,或者 /var/lib/docker/volumes/[VOLUME_ID]/_data)里,而不会影响容器镜像的内容。那么,这个 /test 目录里的内容,既然挂载在容器 rootfs 的可读写层,它会不会被 docker commit 提交掉呢?也不会。
这个原因其实我们前面已经提到过。容器的镜像操作,比如 docker commit,都是发生在宿主机空间的。而由于 Mount Namespace 的隔离作用,宿主机并不知道这个绑定挂载的存在。所以,在宿主机看来,容器中可读写层的 /test 目录(/var/lib/docker/aufs/mnt/[可读写层 ID]/test),始终是空的。不过,由于 Docker 一开始还是要创建 /test 这个目录作为挂载点,所以执行了 docker commit 之后,你会发现新产生的镜像里,会多出来一个空的 /test 目录。毕竟,新建目录操作,又不是挂载操作,Mount Namespace 对它可起不到“障眼法”的作用。
结合以上的讲解,我们现在来亲自验证一下:首先,启动一个 helloworld 容器,给它声明一个 Volume,挂载在容器里的 /test 目录上:
$ docker run -d -v /test myapp
f53b766fa6f
容器启动之后,我们来查看一下这个 Volume 的 ID:
$ docker volume ls
DRIVER VOLUME NAME
local cb1c2f7221fa9b0971cc35f68aa1034824755ac44a034c0c0a1dd318838d3a6d
然后,使用这个 ID,可以找到它在 Docker 工作目录下的 volumes 路径:
$ ls /var/lib/docker/volumes/cb1c2f7221fa/_data/
这个 _data 文件夹,就是这个容器的 Volume 在宿主机上对应的临时目录了。接下来,我们在容器的 Volume 里,添加一个文件 text.txt:
$ docker exec -it cf53b766fa6f /bin/sh
cd test/
touch text.txt
这时,我们再回到宿主机,就会发现 text.txt 已经出现在了宿主机上对应的临时目录里:
$ ls /var/lib/docker/volumes/cb1c2f7221fa/_data/
text.txt
可是,如果你在宿主机上查看该容器的可读写层,虽然可以看到这个 /test 目录,但其内容是空的,
$ ls /var/lib/docker/aufs/mnt/6780d0778b8a/test
可以确认,容器 Volume 里的信息,并不会被 docker commit 提交掉;但这个挂载点目录 /test 本身,则会出现在新的镜像当中。
八、总结
1、整体结构
我们今天全部的结构都可以用这个描述来体现,这个容器进程“java -jar springboot_demo-0.0.1-SNAPSHOT.jar”,运行在由 Linux Namespace 和 Cgroups 构成的隔离环境里;而它运行所需要的各种文件,比如jdk环境等等,以及整个操作系统文件,则由多个联合挂载在一起的 rootfs 层提供。这些 rootfs 层的最下层,是来自 Docker 镜像的只读层。在只读层之上,是 Docker 自己添加的 Init 层,用来存放被临时修改过的 /etc/hosts 等文件。而 rootfs 的最上层是一个可读写层,它以 Copy-on-Write 的方式存放任何对只读层的修改,容器声明的 Volume 的挂载点,也出现在这一层。
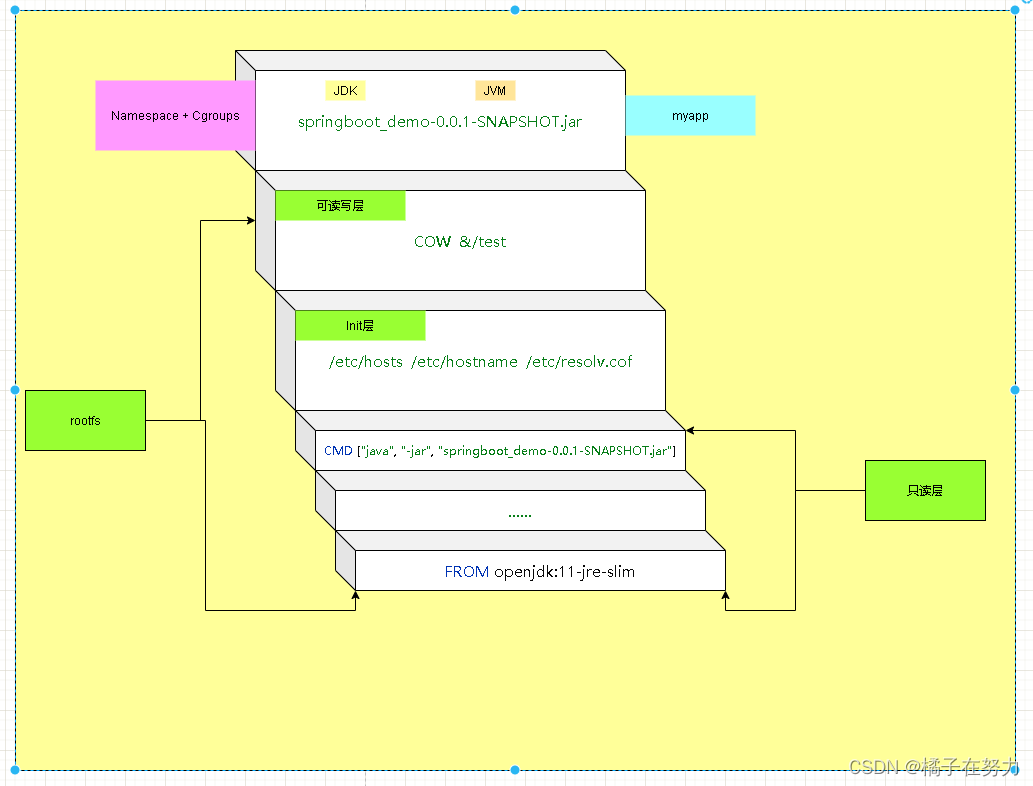
多个镜像之间共享联合的只读写层,然后他们各自上面有各自的可读写层,然后在namespace+cgroup限制下运行容器进程。这里有使用的操作系统文件和类库和jdk这种我们引入的内容。而 所有的层都保存在diff目录下。容器中的主进程在系统调用或调用一些lib时,调用到的和容器只读层提供的lib。
2、exec
我简单说,就是docker exec 每次都会创建一个和容器共享namespace的新进程。
3、补充一些阅读博客
https://blog.phusion.nl/2015/01/20/docker-and-the-pid-1-zombie-reaping-problem/
而且在学习的时候发现自己对于Linux的很多概念不是和很清楚,这一块还是得加强。
而且很多细节其实有点不是彻底理解,随着后续的加强学习,再补一下。


![[一]ffmpeg音视频解码](https://img-blog.csdnimg.cn/direct/e87df84551d44320aa1e464c35f7b8fb.png)