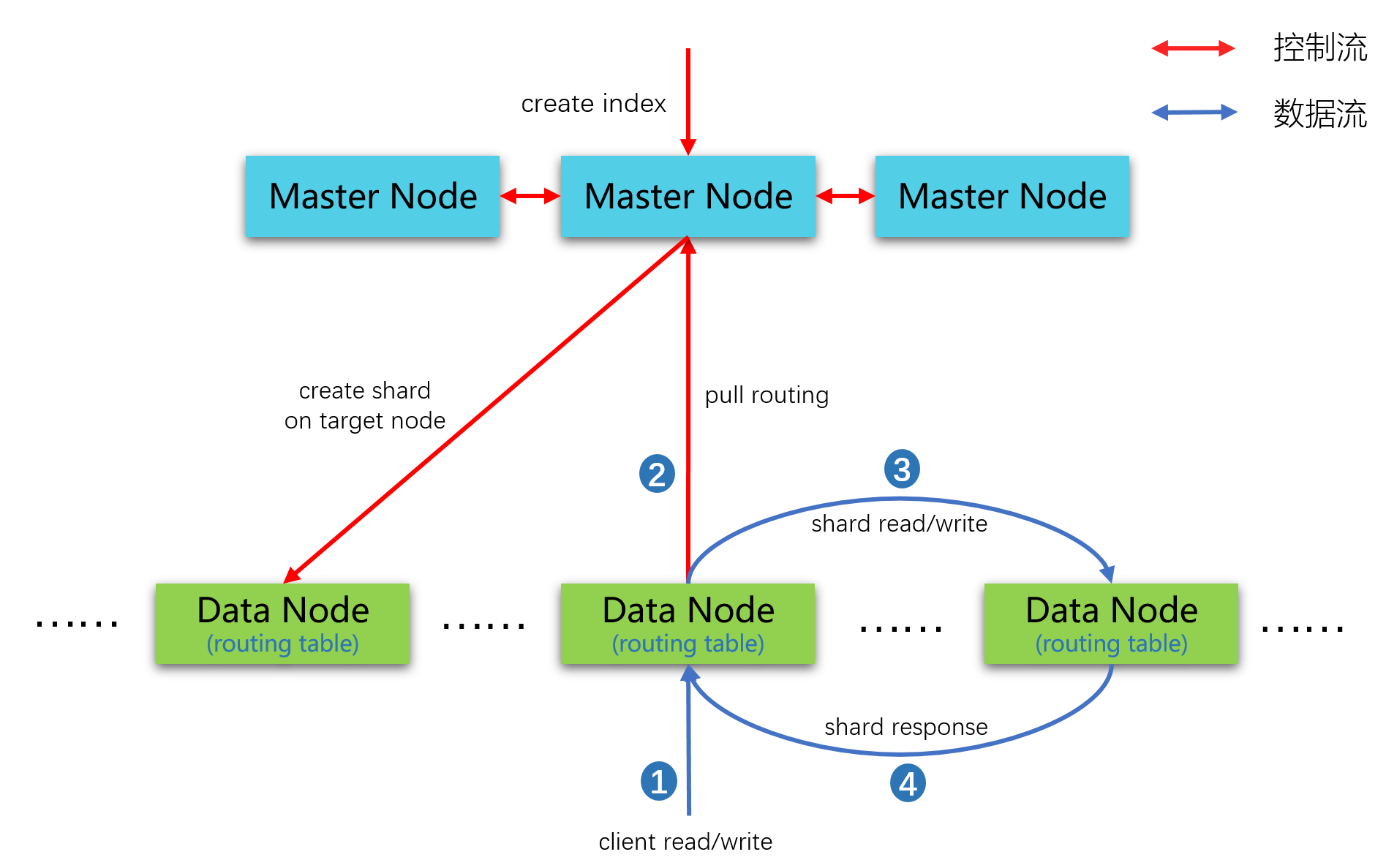
焊接是一个不陌生但是对于开发来说相对小众的场景,在我们前面的博文开发实践中也有一些相关的实践,感兴趣的话可以自行移步阅读即可:
《轻量级模型YOLOv5-Lite基于自己的数据集【焊接质量检测】从零构建模型超详细教程》
《基于DeepLabV3Plus实现焊缝分割识别系统》
《基于官方YOLOv4-u5【yolov5风格实现】开发构建目标检测模型超详细实战教程【以自建缺陷检测数据集为例】》
《探索工业智能检测,基于轻量级YOLOv8开发构建焊接缺陷检测识别系统》
《探索工业智能检测,基于轻量级YOLOv5s开发构建焊接缺陷检测识别系统》
《助力工业焊缝质量检测,YOLOv3开发构建工业焊接场景下钢材管道焊缝质量检测识别分析系统》
《助力工业焊缝质量检测,YOLOv7【tiny/l/x】不同系列参数模型开发构建工业焊接场景下钢材管道焊缝质量检测识别分析系统》
助力工业焊缝质量检测,基于YOLOv8【n/s/m/l/x】全系列参数模型开发构建工业焊接场景下钢材管道焊缝质量检测识别分析系统》
《助力工业焊缝质量检测,基于YOLOv5【n/s/m/l/x】全系列参数模型开发构建工业焊接场景下钢材管道焊缝质量检测识别分析系统》
《助力焊接场景下自动化缺陷检测识别,基于YOLOv5【n/s/m/l/x】全系列参数模型开发构建工业焊接场景下缺陷检测识别分析系统》
前面我们做的关于焊接场景数据开发的实践项目大都是基于焊缝质量进行的检测识别,少有基于表面焊接缺陷进行检测识别,特定产经下小众领域数据本身的采集和标注难度都比较高也进一步限制了这块的工作。
本文主要的目的是想要基于经典的YOLOv3开发构建用于焊接表面缺陷检测的自动化智能检测识别系统,首先看下实例效果:

接下来简单看下数据集情况:


本文是选择的比较经典的也是比较古老的YOLOv3来进行模型的开发,YOLOv3(You Only Look Once v3)是一种目标检测算法模型,它是YOLO系列算法的第三个版本。该算法通过将目标检测任务转化为单个神经网络的回归问题,实现了实时目标检测的能力。
YOLOv3的主要优点如下:
实时性能:YOLOv3采用了一种单阶段的检测方法,将目标检测任务转化为一个端到端的回归问题,因此具有较快的检测速度。相比于传统的两阶段方法(如Faster R-CNN),YOLOv3能够在保持较高准确率的情况下实现实时检测。
多尺度特征融合:YOLOv3引入了多尺度特征融合的机制,通过在不同层级的特征图上进行检测,能够有效地检测不同尺度的目标。这使得YOLOv3在处理尺度变化较大的场景时表现出较好的性能。
全局上下文信息:YOLOv3在网络结构中引入了全局上下文信息,通过使用较大感受野的卷积核,能够更好地理解整张图像的语义信息,提高了模型对目标的识别能力。
简洁的网络结构:YOLOv3的网络结构相对简洁,只有75个卷积层和5个池化层,使得模型较易于训练和部署,并且具有较小的模型体积。
YOLOv3也存在一些缺点:
较低的小目标检测能力:由于YOLOv3采用了较大的感受野和下采样操作,对于小目标的检测能力相对较弱。当场景中存在大量小目标时,YOLOv3可能会出现漏检或误检的情况。
较高的定位误差:由于YOLOv3将目标检测任务转化为回归问题,较粗糙的特征图和较大的感受野可能导致较高的定位误差。这意味着YOLOv3在需要较高精度的目标定位时可能会受到一定的限制。
YOLOv3是YOLO系列里程碑性质的模型,随着不断地演变和发展,目前虽然已经在性能上难以与YOLOv5之类的模型对比但是不可否认其做出的突出贡献。
本文选择的是yolov3-tiny模型,训练数据配置文件如下:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/# number of classes
nc: 5# class names
names: ['BeadDefect', 'BlowHole', 'OverCurrent', 'Spatter', 'UnderCut']模型配置文件如下:
# parameters
nc: 5 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,14, 23,27, 37,58] # P4/16- [81,82, 135,169, 344,319] # P5/32# YOLOv3-tiny backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [16, 3, 1]], # 0[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2[-1, 1, Conv, [32, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4[-1, 1, Conv, [64, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8[-1, 1, Conv, [128, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16[-1, 1, Conv, [256, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32[-1, 1, Conv, [512, 3, 1]],[-1, 1, nn.ZeroPad2d, [0, 1, 0, 1]], # 11[-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12]# YOLOv3-tiny head
head:[[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)[[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)]默认100次epoch的迭代计算,终端日志输出如下所示:

等待训练完成后来整体看下结果详情:
【数据分布可视化】

【PR曲线】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。
精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
绘制精确率-召回率曲线的步骤如下:
使用不同的阈值将预测概率转换为二进制类别标签。通常,当预测概率大于阈值时,样本被分类为正例,否则分类为负例。
对于每个阈值,计算相应的精确率和召回率。
将每个阈值下的精确率和召回率绘制在同一个图表上,形成精确率-召回率曲线。
根据曲线的形状和变化趋势,可以选择适当的阈值以达到所需的性能要求。
精确率-召回率曲线提供了更全面的模型性能分析,特别适用于处理不平衡数据集和关注正例预测的场景。曲线下面积(Area Under the Curve, AUC)可以作为评估模型性能的指标,AUC值越高表示模型的性能越好。
通过观察精确率-召回率曲线,我们可以根据需求选择合适的阈值来权衡精确率和召回率之间的平衡点。根据具体的业务需求和成本权衡,可以在曲线上选择合适的操作点或阈值。

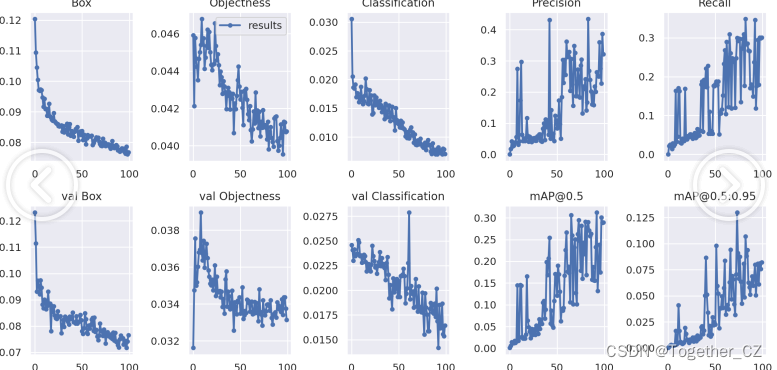
【训练可视化】
【Batch实例】


前文我们已经基于YOLOv5全系列模型开发构建了表面缺陷检测识别模型效果也都不尽如人意,这里基于YOLOv3-tiny模型开发构建的检测模型也是如此。
感兴趣的话也都可以自行动手尝试下!
如果自己不具备开发训练的资源条件或者是没有时间自己去训练的话这里我提供出来对应的训练结果可供自行按需索取。
单个模型的训练结果默认YOLOv3-tiny