即插即用的模块就像是一盒乐高,让我们能快速组合各种设计好的模块,搭建出我们需要的模型,这样做不仅让建模速度提升,还保证了模型的创新性和有效性。
文章目录
1、SCConv:空间和通道重构卷积(2023)
2、SENet:通道注意力模块(2018)
3、ECA:高效通道注意力模块(2020)
4、RefConv:重参数化重聚焦卷积(2023)
5、SNA-SAW:域泛化语义分割模型(2022)
6、HAT:混合注意力机制(2023)
7、EMA:高效多尺度注意力模块(2023)
8、ParC-Net:位置感知型循环卷积(2022)
9、Focused Linear Attention:聚焦式线性注意力模块(2023)
10、FlashOcc:占据预测模型(2023)
11、PromptIR:通用图像恢复(2023)
1、SCConv:空间和通道重构卷积(2023)
(SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy)
论文:SCConv论文
代码:https://github.com/cheng-haha/ScConv/tree/main?tab=readme-ov-file
简述:本文提出了一个新的卷积模块SCConv(空间和通道重构卷积),用于压缩CNN并减少冗余计算。SCConv包括空间重构单元(SRU)和通道重构单元(CRU),分别处理空间和通道冗余。SCConv可以简单地替换CNN中的标准卷积,实验证明,它可以在降低复杂性和计算成本的同时,提高模型性能。
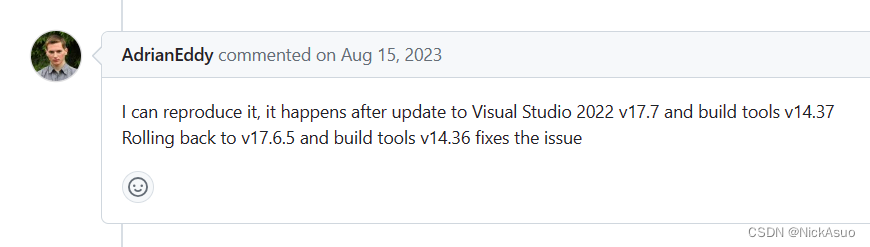
SCConv如图1所示,它由两个单元组成,空间重建单元(SRU)和通道重建单元(CRU),以顺序的方式放置。具体而言,对于瓶颈残差块中的中间输入特征X,首先通过SRU运算获得空间细化特征,然后利用CRU运算获得信道细化特征Y。SCConv模块充分利用了特征之间的空间冗余和通道冗余,可以无缝集成到任何CNN架构中,以减少中间特征映射之间的冗余并增强CNN的特征表示。
2、SENet:通道注意力模块(2018)
(Squeeze-and-Excitation Networks)
论文:https://arxiv.org/pdf/1709.01507.pdf
代码:https://github.com/hujie-frank/SENet
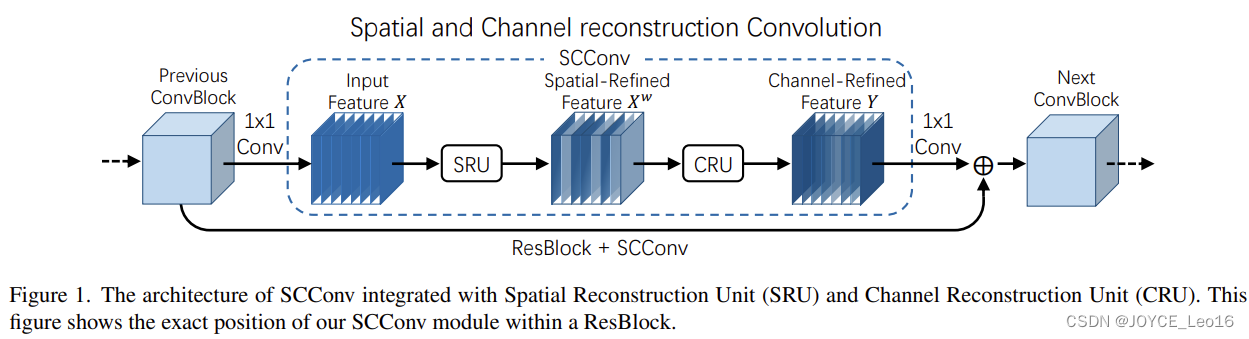
简述:本文提出了一种新的架构单元"挤压激励"(SE)块,通过明确模拟通道间的依赖关系,适应性地校准通道特征反应。在此基础上,研究人员构建了SENet架构,其具有出色的通用性,SE块对于现有的先进深度架构来说,可以在极小的额外计算成本下提供重大的性能改进。
3、ECA:高效通道注意力模块(2020)
(ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks)
论文:https://arxiv.org/pdf/1910.03151.pdf
代码:https://github.com/BangguWu/ECANet
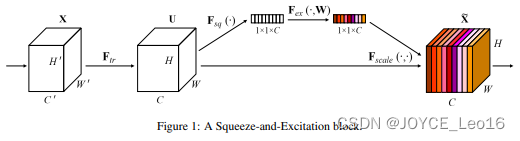
简述:本文提出了一个名为 ECA 的高效通道注意力模块,它不降维,仅用少量参数显著提升性能。通过1D卷积实现局部通道交互策略,并自适应确定最佳卷积核大小。实验证明ECA模块在ResNet50等网络中提高准确率,同时降低参数数量和计算成本。此模块在图像分类、对象检测和实例分割等多项任务中表现出更高的效率和性能。
4、RefConv:重参数化重聚焦卷积(2023)
(RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets)
论文:https://arxiv.org/pdf/2310.10563.pdf
代码:https://github.com/Aiolus-X/RefConv
简述:本文提出了一种新型的卷积模块 RefConv(重参数化重聚焦卷积),作为传统卷积层的高效替代品,无需增加额外的推理成本即可提升模型性能。它通过对预训练模型种的卷积核应用一个可训练的变换,进而建立参数间新的联系,增强模型处理不同层次特征的能力。实验证明,RefConv能够在保持原有模型结构不变的情况下,显著提高图像分类、目标检测和语义分割任务的性能。
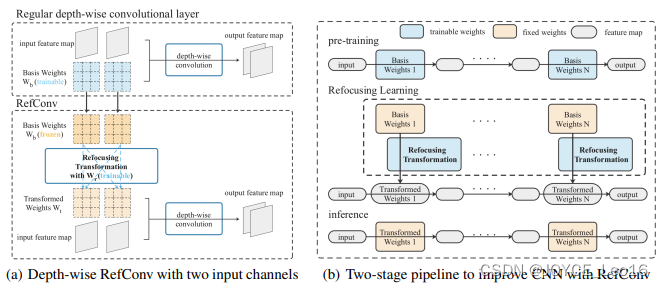
5、SNA-SAW:域泛化语义分割模型(2022)
(Semantic-Aware Domain Generalized Segmentation)
论文:https://arxiv.org/pdf/2204.00822.pdf
代码:https://github.com/leolyj/SAN-SAW
简述:本文提出了一个新的框架,其中包括两个模块:语义感知标准化(SAN)和语义感知百化(SAW)。SAN模块用于在不同图像样式之间进行类别级的特征对齐;SAW模块则用于对齐特征分布,并增强类内紧凑性与类间分离性。通过在多个标准数据集上的实验验证,这种方法各种主干网络上都表现出了明显优于现有技术的改进。
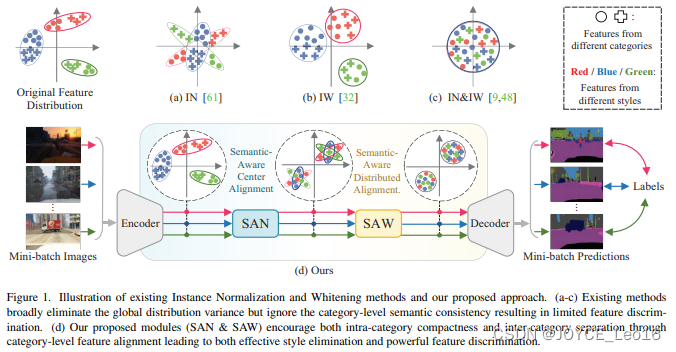
6、HAT:混合注意力机制(2023)
(Activating More Pixels in Image Super-Resolution Transformer)
论文:https://arxiv.org/pdf/2205.04437.pdf
代码:https://github.com/XPixelGroup/HAT
简述:本文提出了一种称为混合注意力Transformer(HAT)的新型网络架构,它融合了通道注意力和窗口注意力机制的长处,提高了模型处理全局和局部信息的能力。此外,研究人员还引入了一个跨窗口的注意力模块,用以强化临近窗口特征间的互动。通过在训练阶段实行同任务预训练,进一步提升了模型性能。经过一系列实验,这个方法在性能上显著优于现有最先进技术,达到了1dB以上的提高。
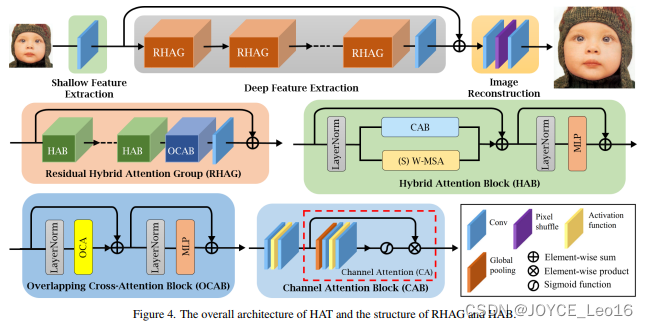
7、EMA:高效多尺度注意力模块(2023)
(Efficient Multi-Scale Attention Module with Cross-Spatial Learning)
论文:https://arxiv.org/ftp/arxiv/papers/2305/2305.13563.pdf
代码:https://github.com/YOLOonMe/EMA-attention-module
简述:本文提出了一种叫做 EMA 的新型多尺度注意力模块,它能够同时保持信息有效性和降低计算成本,EMA通过将通道分成子组和平衡特征组内的空间语义特征来实现这一目标。还设计了一个双分支结构,以编码全局信息,并通过跨维度的交互进一步加强特征。对CIFAR100图像分类和MS COCO与VisDrone2019数据集上的目标检测进行的实验验证了EMA的有效性,它在不增加网络复杂度的前提下,超越了多个现有的注意力机制。
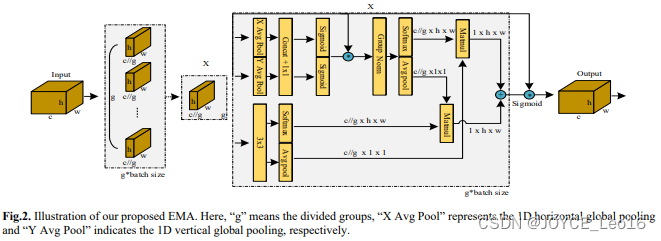
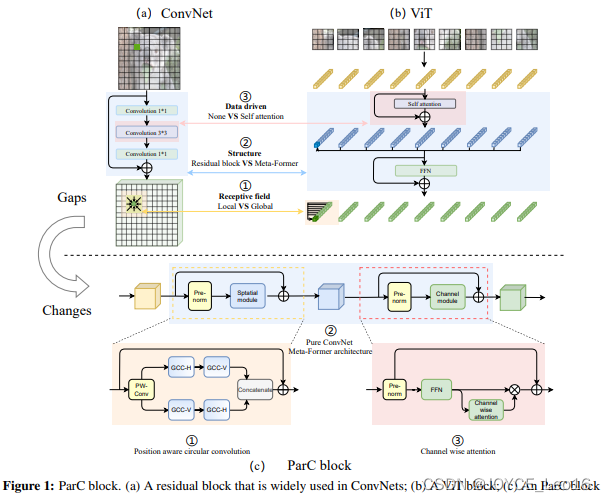
8、ParC-Net:位置感知型循环卷积(2022)
(ParC-Net: Position Aware Circular Convolution with Merits from ConvNets and Transformer)
论文:https://arxiv.org/pdf/2203.03952.pdf
代码:https://github.com/hkzhang-git/ParC-Net
简述:本文提出了一个基于卷积网络的新模型ParC-Net,融合了视觉变换器的优点,核心创新是位置感知环式卷积(ParC),兼具全局感受野和位置敏感特性。ParC与挤压-激励操作结合,形成类似变换器的模型块,可替换卷积或变换器部分。实验证明,ParC-Net在常见视觉任务中性能优异,参数少、推理快。
9、Focused Linear Attention:聚焦式线性注意力模块(2023)
(FLatten Transformer: Vision Transformer using Focused Linear Attention)
论文:https://arxiv.org/pdf/2308.00442.pdf
代码:https://github.com/LeapLabTHU/FLatten-Transformer
简述:本文提出了一种新颖的Focused Linear Attention模块,以实现高效率和表达性。通过分析影响性能的关键因素,引入了一个简单而有效的映射函数和一个高效的等级恢复模块,以增强self-attention的表达性,同时保持较低的计算复杂度。大量的实验表明,这个线性注意力模块适用于各种先进的vision Transformers,并在多个基准测试中取得了持续的改进性能。

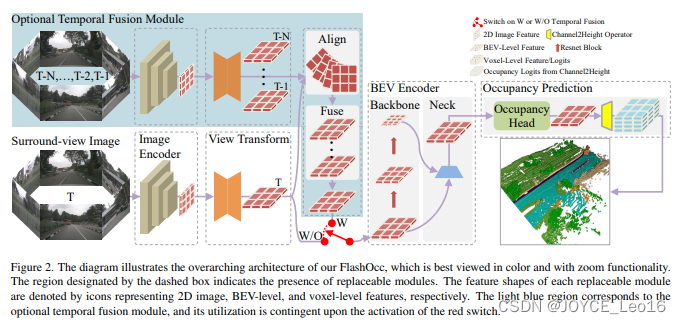
10、FlashOcc:占据预测模型(2023)
(FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin)
论文:https://arxiv.org/pdf/2311.12058.pdf
代码:https://github.com/Yzichen/FlashOCC
简述:本文提出了提出了即插即用的占用预测范式FlashOCC,快速、内存高效且精度高。它有两项创新:特征保存在BEV中,利用二维卷积;逻辑值从BEV转为3D空间。在Occ3D-nuScenes基准测试中,FlashOCC显著超越了最先进方法,证明了其在精度、效率和内存成本上的优势,展示了其部署潜力。
11、PromptIR:通用图像恢复(2023)
(PromptIR: Prompting for All-in-One Blind Image Restoration)
论文:https://arxiv.org/pdf/2306.13090.pdf
代码:https://github.com/va1shn9v/PromptIR
简述:本文提出了一种名为PromptIR的新型学习方法,处理多种图像退化问题的通用解决方案。该方法通过编码与退化相关的提示信息来指导恢复网络,使其能够处理不同类型和程度的图像问题,如噪音、雨滴和雾霾,并取得领先效果。PromptIR作为一个轻量级的插件模块,可以适用于多种退化情况的图像恢复,无需预先知道具体损坏类型。


参考:享享学AI