一、说明
欢迎阅读此文,NLP 爱好者!当我们继续探索自然语言处理 (NLP) 的广阔前景时,我们已经在最初的博客中探讨了它的历史、应用和挑战。今天,我们更深入地探讨 NLP 的核心——数据预处理的复杂世界。
这篇文章是我们的“完整 NLP 指南:文本到上下文”博客系列的第二部分。我们的重点非常明确:我们深入研究为 NLP 任务奠定基础所必需的关键数据预处理步骤。虽然 NLP 的进步使得能够开发能够感知和理解人类语言的应用程序,但仍然存在一个关键的先决条件——以机器可以理解的格式准备并向机器提供数据。这个过程涉及一系列多样化且重要的预处理步骤。
以下是本次深入研究中的预期内容:
- 标记化和文本清理:探索将文本分解为有意义的单元并确保原始且易于理解的语言的艺术。这包括处理标点符号和细化文本以进行进一步处理。
- 停用词删除:了解为什么删除某些单词对于关注数据集中更有意义的内容至关重要。
- 词干提取和词形还原:深入研究文本规范化技术,了解何时以及如何使用词干提取或词形还原将单词简化为词根形式。
- 词性标注 (POS):探索为每个单词分配语法类别如何有助于更深入地理解句子结构和上下文。
- 命名实体识别 (NER):通过识别和分类文本中的实体,揭示 NER 在增强语言理解方面的作用。
其中每个步骤都是将原始文本翻译成机器可以理解的语言的关键构建块,为更高级的 NLP 任务奠定了基础。
在本次探索结束时,您不仅会牢牢掌握这些基本的预处理步骤,而且还会为我们旅程的下一阶段——探索高级文本表示技术做好准备。让我们深入了解 NLP 数据预处理的要点并增强自己的能力。快乐编码!
二. 分词和文本清理
NLP 的核心是将文本分解为有意义的单元的艺术。标记化是将文本分割成单词、短语甚至句子(标记)的过程。这是为进一步分析奠定基础的第一步。与文本清理(我们删除不必要的字符、数字和符号)相结合,标记化可确保我们使用原始的、可理解的语言单元。
#!pip install nltk
# Example Tokenization and Text Cleaning
text = "NLP is amazing! Let's explore its wonders."
tokens = nltk.word_tokenize(text)
cleaned_tokens = [word.lower() for word in tokens if word.isalpha()]
print(cleaned_tokens)['nlp', 'is', 'amazing', 'let', 'explore', 'its', 'wonders']三、 停用词删除:
并非所有单词对句子的含义都有同等的贡献。像“the”或“and”这样的停用词通常会被过滤掉,以专注于更有意义的内容。
# Example Stop Words
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
filtered_sentence = [word for word in cleaned_tokens if word not in stop_words]
print(filtered_sentence)['nlp', 'amazing', 'let', 'explore', 'wonders']四、词干提取和词形还原
词干提取和词形还原都是自然语言处理 (NLP) 中使用的文本规范化技术,用于将单词还原为其基本形式或词根形式。虽然他们的共同目标是简化单词,但他们在应用语言知识方面的运作方式有所不同。
词干提取:还原为根形式
词干提取涉及切断单词的前缀或后缀以获得其词根或基本形式,称为词干。目的是将具有相似含义的单词视为相同的单词。词干提取是一种基于规则的方法,并不总是产生有效的单词,但计算量较小。
词形还原:转换为字典形式
另一方面,词形还原涉及将单词减少为其基本形式或字典形式,称为词条。它考虑了句子中单词的上下文并应用形态分析。词形还原会产生有效的单词,并且与词干提取相比在语言学上更具信息性。
何时使用词干提取与词形还原:
词干提取:
- 优点:简单且计算成本较低。
- 缺点:可能并不总是产生有效的单词。
词形还原:
- 优点:产生有效的单词;考虑语言背景。
- 缺点:比词干提取的计算强度更大。
在词干提取和词形还原之间进行选择:

Day 4: Stemming and Lemmatization - Nomidl
词干提取和词形还原之间的选择取决于 NLP 任务的具体要求。如果您需要一种快速而直接的文本分析方法,词干提取可能就足够了。然而,如果语言准确性至关重要,特别是在信息检索或问答等任务中,则通常首选词形还原。
在实践中,选择通常取决于基于 NLP 应用程序的具体特征的计算效率和语言准确性之间的权衡。
# Example Stemming, and Lemmatization
from nltk.stem import PorterStemmer, WordNetLemmatizerstemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()stemmed_words = [stemmer.stem(word) for word in filtered_sentence]
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_sentence]print(stemmed_words)
print(lemmatized_words)['nlp', 'amaz', 'let', 'explor', 'wonder']
['nlp', 'amazing', 'let', 'explore', 'wonder']五、词性标注:
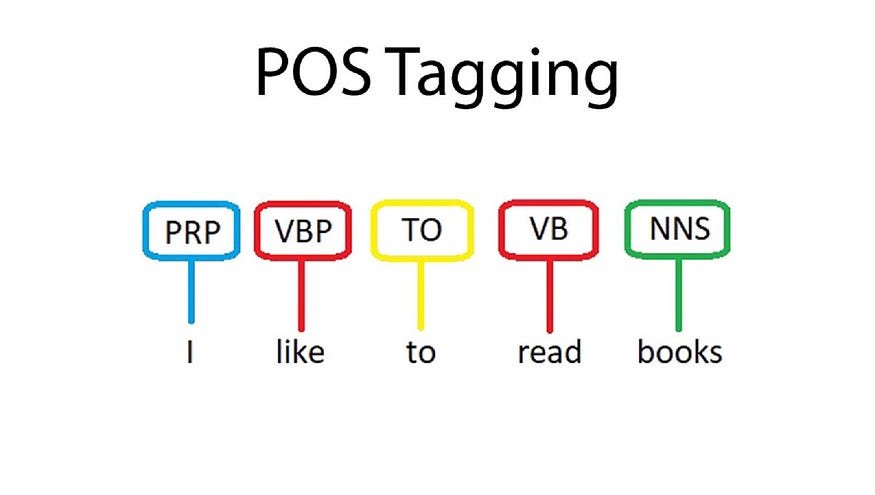
词性标注(词性标注)是一种自然语言处理任务,其目标是为给定文本中的每个单词分配语法类别(例如名词、动词、形容词等)。这可以更深入地理解句子中每个单词的结构和功能。
Penn Treebank POS 标签集是一种广泛使用的标准,用于在英语文本中表示这些词性标签。
# Example Part-of-Speech Tagging
from nltk import pos_tag
pos_tags = nltk.pos_tag(filtered_sentence)
print(pos_tags)[('nlp', 'RB'), ('amazing', 'JJ'), ('let', 'NN'), ('explore', 'NN'), ('wonders', 'NNS')]六、命名实体识别(NER):
NER 通过对给定文本中的名称、位置、组织等实体进行识别和分类,将语言理解提升到一个新的水平。这对于从非结构化数据中提取有意义的信息至关重要。
# Example Named Entity Recognition (NER)
from nltk import ne_chunkner_tags = ne_chunk(pos_tags)
print(ner_tags)(S nlp/RB amazing/JJ let/NN explore/NN wonders/NNS)七、NLP 预处理步骤的实际应用
虽然我们深入研究了 NLP 预处理的技术方面,但了解如何在现实场景中应用这些步骤也同样重要。让我们探讨一些值得注意的例子:
社交媒体情感分析中的标记化和文本清理
在社交媒体情感分析中,标记化和文本清理至关重要。例如,在分析推文以评估公众对新产品的看法时,标记化有助于将推文分解为单个单词或短语。文本清理用于消除社交媒体文本中常见的话题标签、提及和 URL 等噪音。
import re
def clean_tweet(tweet):tweet = re.sub(r'@\w+', '', tweet) # Remove mentionstweet = re.sub(r'#\w+', '', tweet) # Remove hashtagstweet = re.sub(r'http\S+', '', tweet) # Remove URLsreturn tweettweet = "Loving the new #iPhone! Best phone ever! @Apple"
clean_tweet(tweet)'Loving the new ! Best phone ever! ' 搜索引擎中的停用词删除
搜索引擎广泛使用停用词删除。在处理搜索查询时,通常会删除“the”、“is”和“in”等常用词,以重点关注更有可能与搜索结果相关的关键字。
文本分类中的词干提取和词形还原
新闻机构和内容聚合商经常使用词干提取和词形还原进行文本分类。通过将单词简化为基本形式或词根形式,算法可以更轻松地将新闻文章分类为“体育”、“政治”或“娱乐”等主题。
语音助手中的词性标记
亚马逊的 Alexa 或苹果的 Siri 等语音助手使用词性标记来提高语音识别和自然语言理解。通过确定单词的语法上下文,这些助手可以更准确地解释用户请求。
客户支持自动化中的命名实体识别 (NER)
NER 广泛用于客户支持聊天机器人。通过识别和分类产品名称、位置或用户问题等实体,聊天机器人可以对客户的询问提供更有效和量身定制的响应。
这些例子凸显了 NLP 预处理步骤在各个行业中的实际意义,使抽象概念更加具体、更容易掌握。了解这些应用程序不仅可以提供背景信息,还可以激发未来项目的想法。
八、结论
在本文中,我们仔细浏览了增强 NLP 任务文本所必需的各种数据预处理步骤。从最初通过标记化和清理对文本进行分解,到更高级的词干提取、词形还原、词性标记和命名实体识别过程,我们为有效理解和处理语言数据奠定了坚实的基础。
然而,我们的旅程并没有就此结束。处理后的文本虽然现在更加结构化和信息丰富,但仍需要进一步转换才能完全被机器理解。在下一部分中,我们将深入研究文本表示技术。这些技术,包括词袋模型、TF-IDF(词频-逆文档频率)以及词嵌入的介绍,对于将文本转换为机器不仅可以理解而且可以用于各种用途的格式至关重要。复杂的 NLP 任务。
因此,请继续关注我们,我们将继续揭开 NLP 的复杂性。我们的探索将为您提供将原始文本转换为有意义的数据的知识,为高级分析和应用做好准备。祝您编码愉快,我们下一篇文章再见!