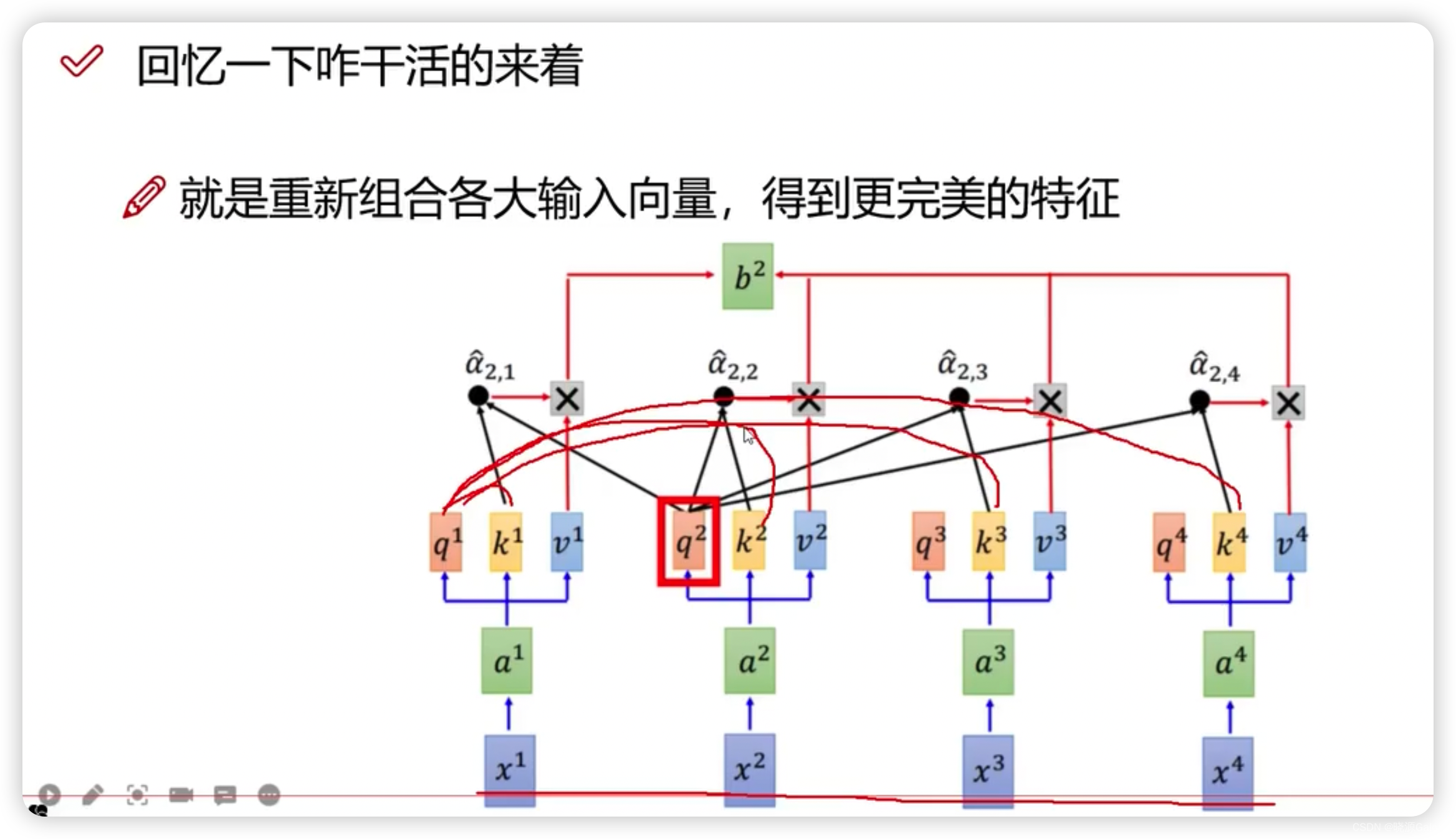
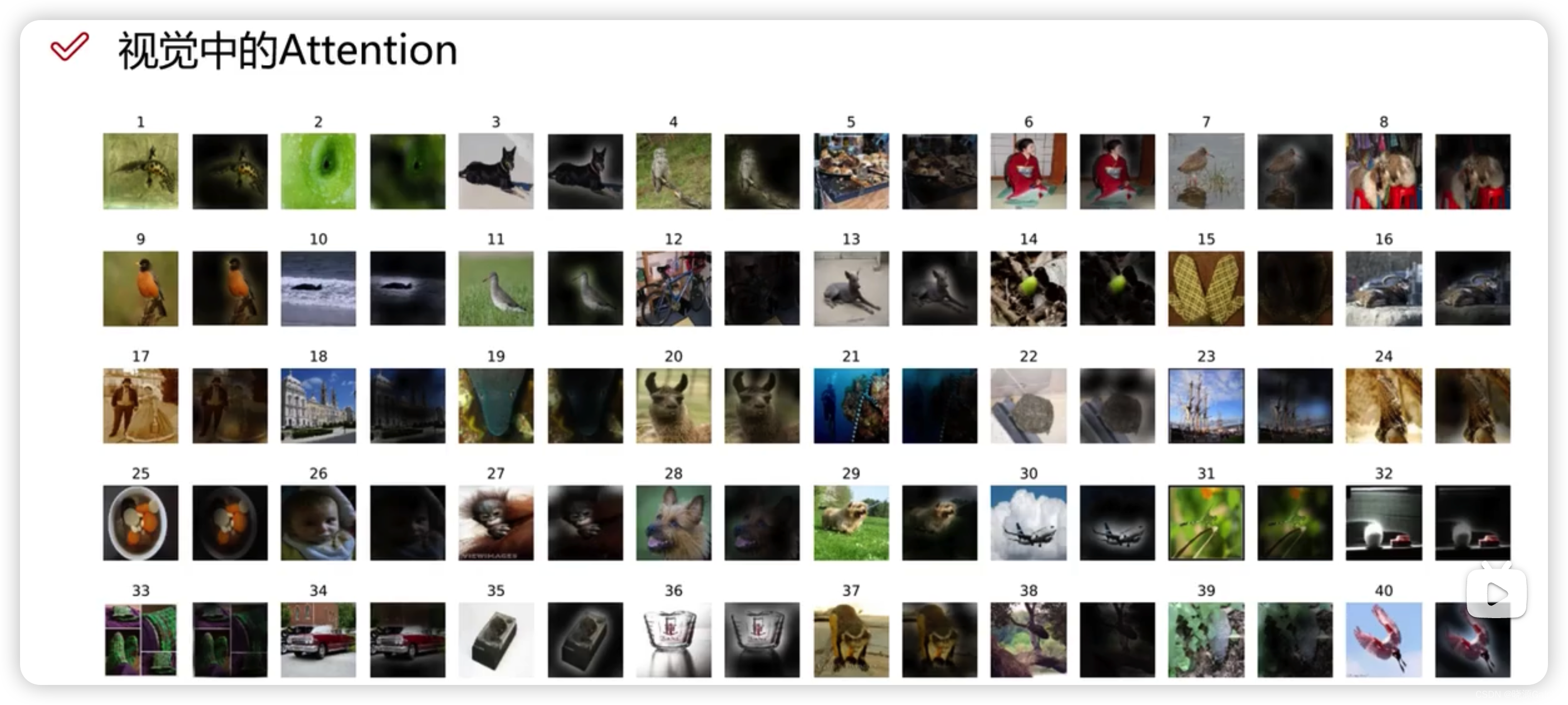
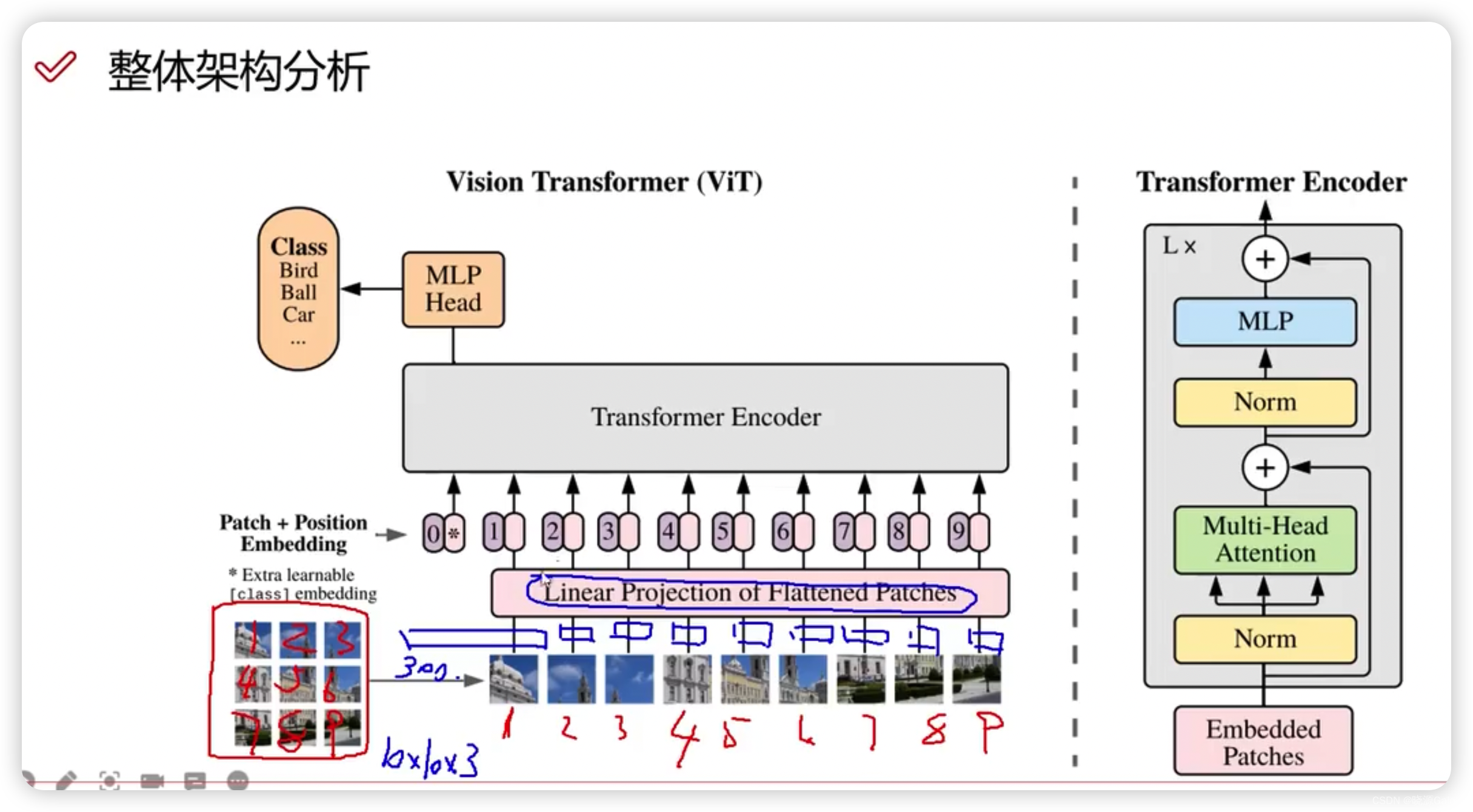
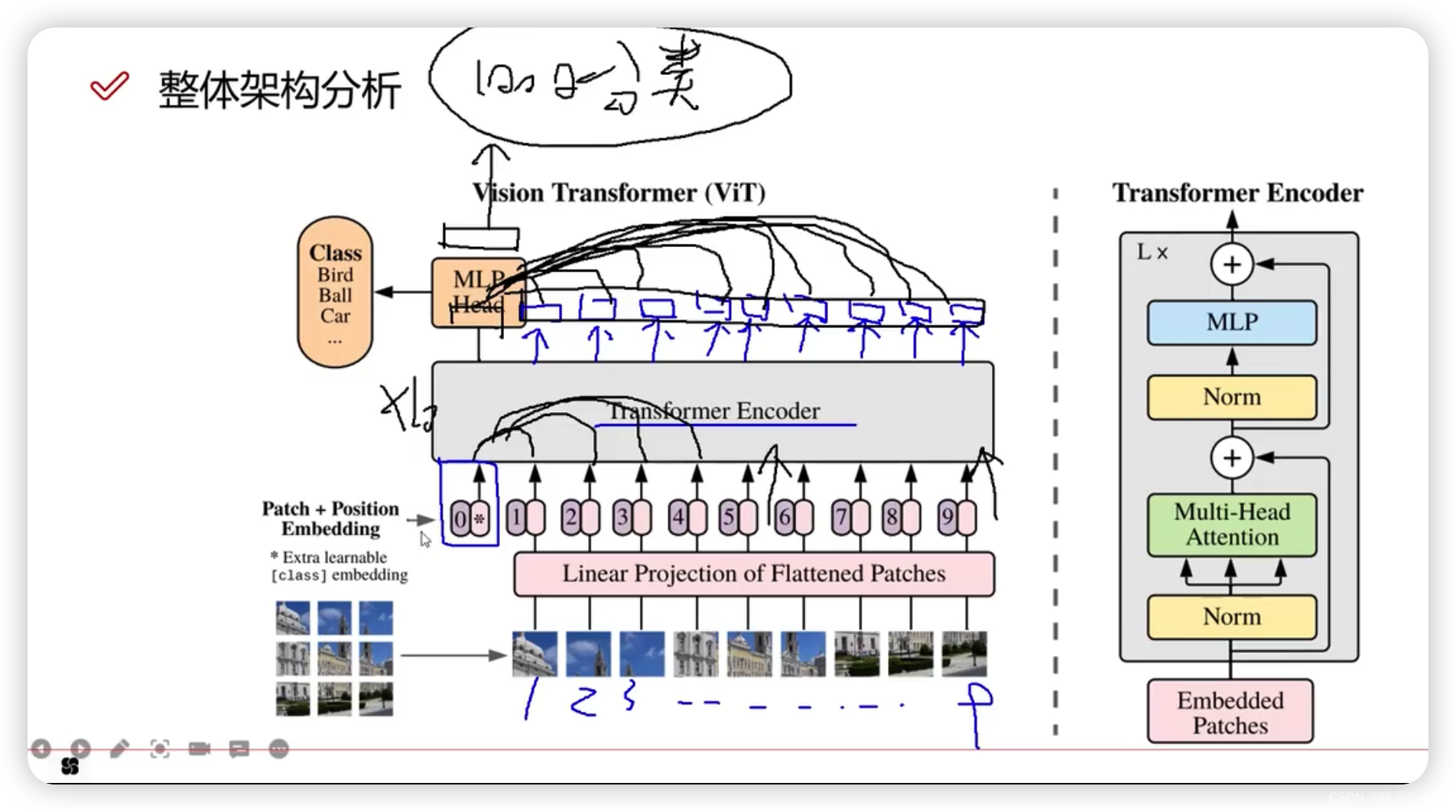
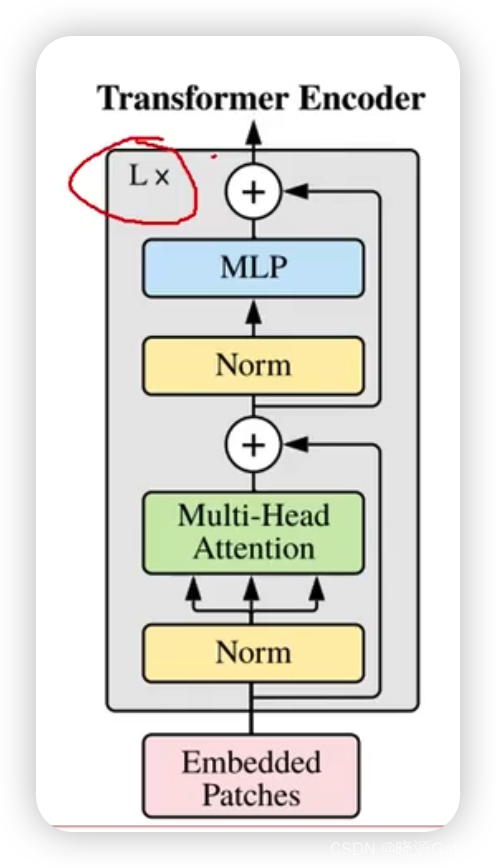
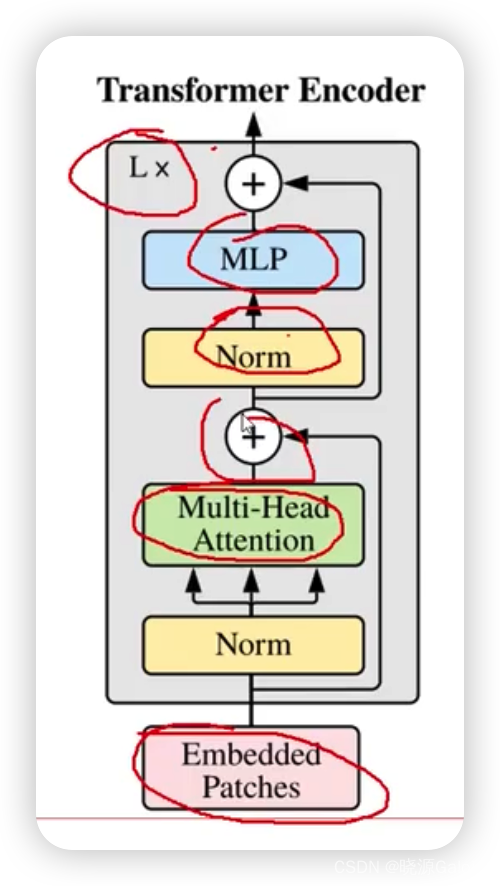
Transformer|对图像数据构造patch序列+VIT整体架构解读(需进一步完善)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/417245.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
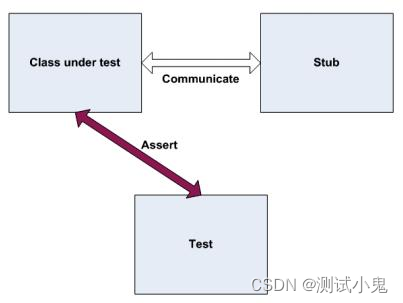
单元测试之Stub和Mock
实例
Analyze类会检查filename的长度,如果小于8,我们就会使用一个实现IWebService的类来记录错误.
我们需要给Analyze方法写单元测试。
public class LogAnalyzer
{private IWebService service;private IEmailService email;public IWebService Serv…

C++类与对象【运算符重载】
🌈个人主页:godspeed_lucip 🔥 系列专栏:C从基础到进阶 🎄1 运算符重载🌽1.1 加号运算符重载🌽1.2 左移运算符重载🌽1.3 递增运算符重载🌽1.4 赋值运算符重载ἳ…

信道复用技术码分复用 CDM(Code Division Multiplexing)
目录
一、码分复用 CDM(Code Division Multiplexing)
二、码分多址CDMA
三、码片序列的概念
四、码片序列的正交关系
五、CDMA的工作原理 一、码分复用 CDM(Code Division Multiplexing) 常用的名词是码分多址 CDMA (Code Di…

Linux 内核被冬季风暴 “封印“
Linus Torvalds在内核邮件列表上宣布,由于他所在的美国俄勒冈州波特兰地区受到严重冬季风暴的影响,导致网络和电力中断。波特兰及其周边地区气温急降至零下 -10C,因此他不得不临时中断对Linux 6.8内核的合并窗口操作。 Linus于1月7日发布了Li…
![[AI]文心一言爆火的同时,ChatGPT-4.5的正确打开方式](https://img-blog.csdnimg.cn/direct/1ceb3fd255254ceeaa91ded1c5c1ddba.png)
[AI]文心一言爆火的同时,ChatGPT-4.5的正确打开方式
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z
ChatGPT体验地址 文章目录 前言4.5key价格泄漏ChatGPT4.0使用地址ChatGPT正确打开方式最新功能语音助手存档…
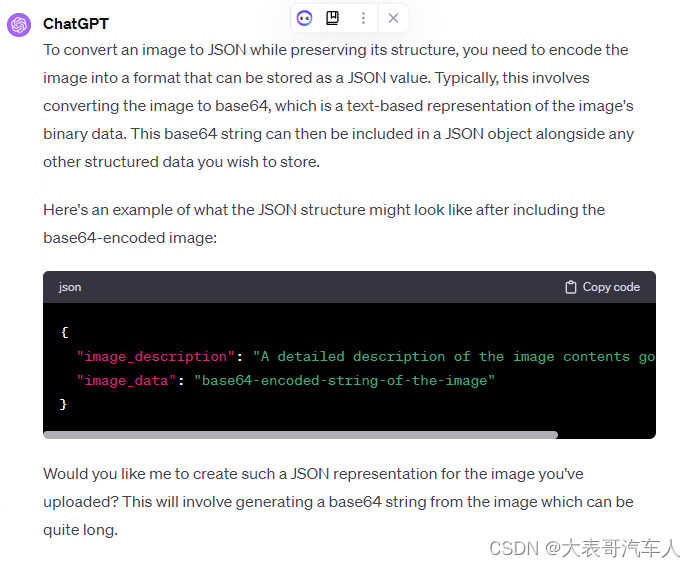
【ChatGPT】利用ChatGPT将图片转换成JSON文件
前言 我在创建自己的GPT时,通常会上传一些JSON文件作为知识库,我还制作了一些脚本工具,将PDF文件转换成JSON文件。但是在这个过程中产生一个问题,PDF文件中会有一些图表,JSON文件就不能存储和表达这些图表的内容了。那该怎么办呢?这里跟大家介绍一个方法,可以有效地将图…

第五篇:其他窗口部件 QAbstractButton
QAbstractButton
QAbstractButton 类是按钮部件的抽象基类,提供了按钮的通用功能。它的子类包括标准按钮 QPushButton、工具按钮 QToolButton、复选框 QCheckBox和单选按钮 QRadioButton 等。
QPushButton
QPushButton 提供了创建交互按钮的基本功能。它可以包含…
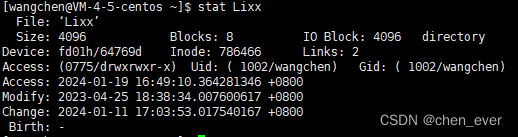
Linux-ionde(软硬件链接)剖析
概述 文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这…
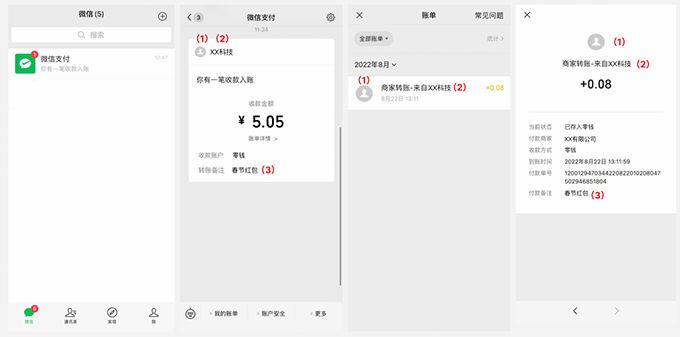
商家转账到零钱开通证明材料怎么办?
商家转账到零钱是什么?
商家转账到零钱是企业付款到零钱的升级版,它的功能是,如果系统需要对用户支付费用,比如发放佣金、提成、退款等,可以直接转账到用户的微信零钱。这个功能在 2022 年 5 月 18 日之前叫做企业付款…
BossCMS RCE
简介
BossCMS是一款基于自主研发PHP框架MySQL架构的内容管理系统,能够满足各类网站开发建设的需求。系统开源、安全、稳定、简洁、易开发、专注为中小型企业及政企单位、个人站长、广大开发者、建站公司提供一套简单好用的网站内容管理系统解决方案。官网提供了大量…