基于 InternLM 和 LangChain 搭建你的知识库
1. 基础作业:
环境配置
1.1 InternLM 模型部署
创建开发机

进入 conda 环境之后,使用以下命令从本地一个已有的 pytorch 2.0.1 的环境,激活环境,在环境中安装运行 demo 所需要的依赖。
conda activate InternLM# 升级pip
python -m pip install --upgrade pippip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
1.2 模型下载
在本地的 /root/share/temp/model_repos/internlm-chat-7b 目录下已存储有所需的模型文件参数,可以直接拷贝到个人目录的模型保存地址:
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b
1.3 LangChain 相关环境配置
在已完成 InternLM 的部署基础上,还需要安装以下依赖包:
pip install langchain==0.0.292
pip install gradio==4.4.0
pip install chromadb==0.4.15
pip install sentence-transformers==2.2.2
pip install unstructured==0.10.30
pip install markdown==3.3.7
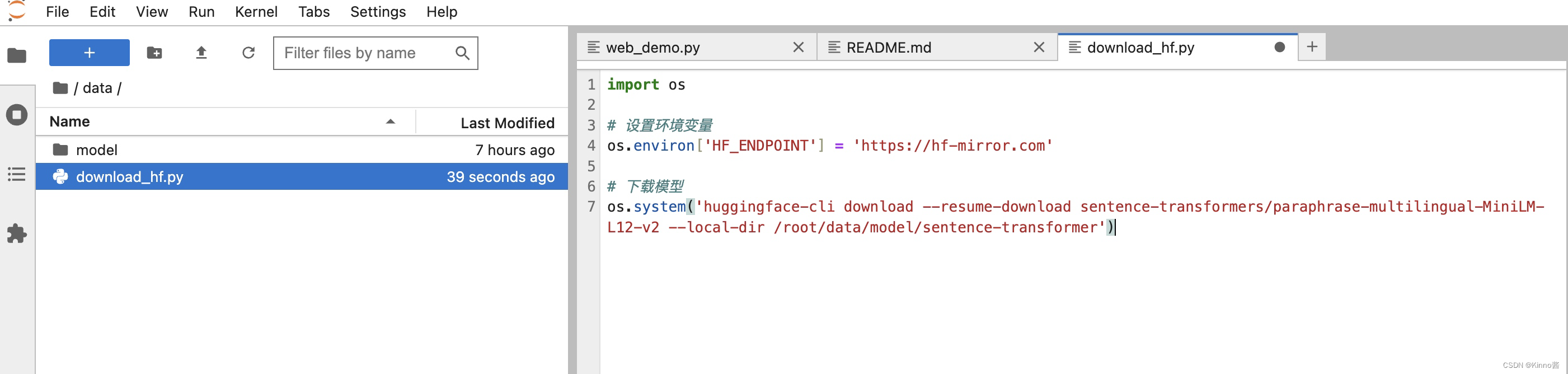
下载并使用开源词向量模型 Sentence Transformer
pip install -U huggingface_hub
使用huggingface镜像下载
1.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。
我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-page s
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
知识库搭建
2.1 数据收集
选择由上海人工智能实验室开源的一系列大模型工具开源仓库作为语料库来源,包括:
OpenCompass:面向大模型评测的一站式平台
IMDeploy:涵盖了 LLM 任务的全套轻量化、部署和服务解决方案的高效推理工具箱
XTuner:轻量级微调大语言模型的工具库
InternLM-XComposer:浦语·灵笔,基于书生·浦语大语言模型研发的视觉-语言大模型
Lagent:一个轻量级、开源的基于大语言模型的智能体(agent)框架
InternLM:一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖
首先我们需要将上述远程开源仓库 Clone 到本地,可以使用以下命令:
2. 进阶作业:
选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)