目录
一、常见的多GPU训练方法
1、问题拆分
2、数据并行
二、代码实现
1、实现ResNet-18网络
2、网络初始化
3、训练
三、总结
一、常见的多GPU训练方法
1、问题拆分
假设我们有多个GPU。我们希望以一种方式对训练进行拆分,为实现良好的加速比,还能同时受益于简单且可重复的设计选择。毕竟,多个GPU同时增加了内存和计算能力。简而言之,对于需要分类的小批量训练数据,我们有以下选择。
(1)在多个GPU之间拆分网络
也就是说,每个GPU将流入特定层的数据作为输入,跨多个后续层对数据进行处理,然后将数据发送到下一个GPU。与单个GPU所能处理的数据相比,我们可以用更大的网络处理数据。此外,每个GPU占用的显存(memory footprint)可以得到很好的控制,虽然它只是整个网络显存的一小部分。
然而,GPU的接口之间需要的密集同步可能是很难办的,特别是层之间计算的工作负载不能正确匹配的时候,还有层之间的接口需要大量的数据传输的时候(例如:激活值和梯度,数据量可能会超出GPU总线的带宽)。此外,计算密集型操作的顺序对拆分来说也是非常重要的,其本质仍然是一个困难的问题,目前还不清楚研究是否能在特定问题上实现良好的线性缩放。综上所述,除非存框架或操作系统本身支持将多个GPU连接在一起,否则不建议这种方法。
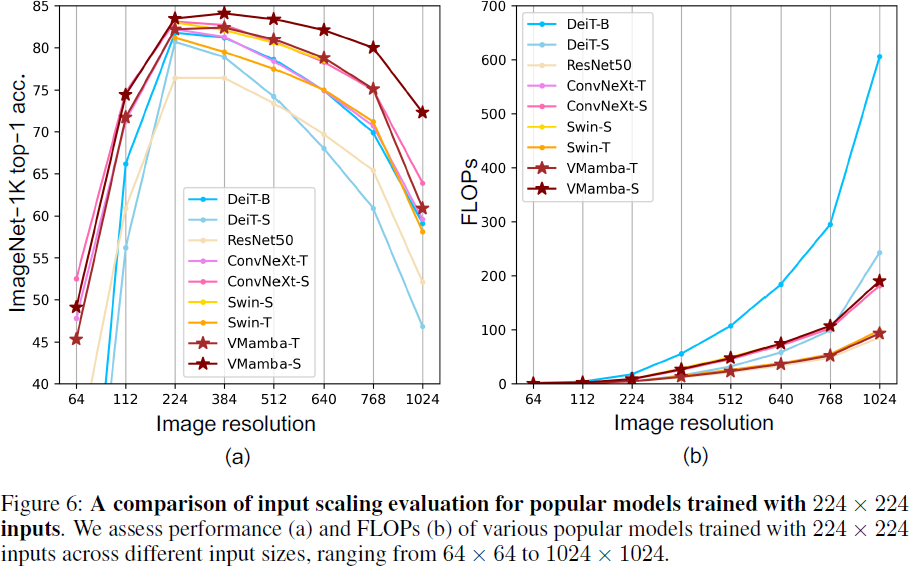
(2)拆分层内的工作
例如,将问题分散到个GPU,每个GPU生成
个通道的数据,而不是在单个GPU上计算
个通道。对于全连接的层,同样可以拆分输出单元的数量。下图描述了这种设计,其策略用于处理显存非常小(当时为2GB)的GPU。当通道或单元的数量不太小时,使计算性能有良好的提升。此外,由于可用的显存呈线性扩展,多个GPU能够处理不断变大的网络。

然而,我们需要大量的同步或屏障操作(barrier operation),因为每一层都依赖于所有其他层的结果。此外,需要传输的数据量也可能比跨GPU拆分层时还要大。因此,基于带宽的成本和复杂性,我们同样不推荐这种方法。
(3)跨多个GPU对数据进行拆分
这种方式下,所有GPU尽管有不同的观测结果,但是执行着相同类型的工作。在完成每个小批量数据的训练之后,梯度在GPU上聚合。这种方法最简单,并可以应用于任何情况,同步只需要在每个小批量数据处理之后进行。也就是说,当其他梯度参数仍在计算时,完成计算的梯度参数就可以开始交换。而且,GPU的数量越多,小批量包含的数据量就越大,从而就能提高训练效率。但是,添加更多的GPU并不能让我们训练更大的模型。
上图中比较了多个GPU上不同的并行方式。总体而言,只要GPU的显存足够大,数据并行是最方便的。在深度学习的早期,GPU的显存曾经是一个棘手的问题,然而如今除了非常特殊的情况,这个问题已经解决。下面我们将重点讨论数据并行性。
2、数据并行
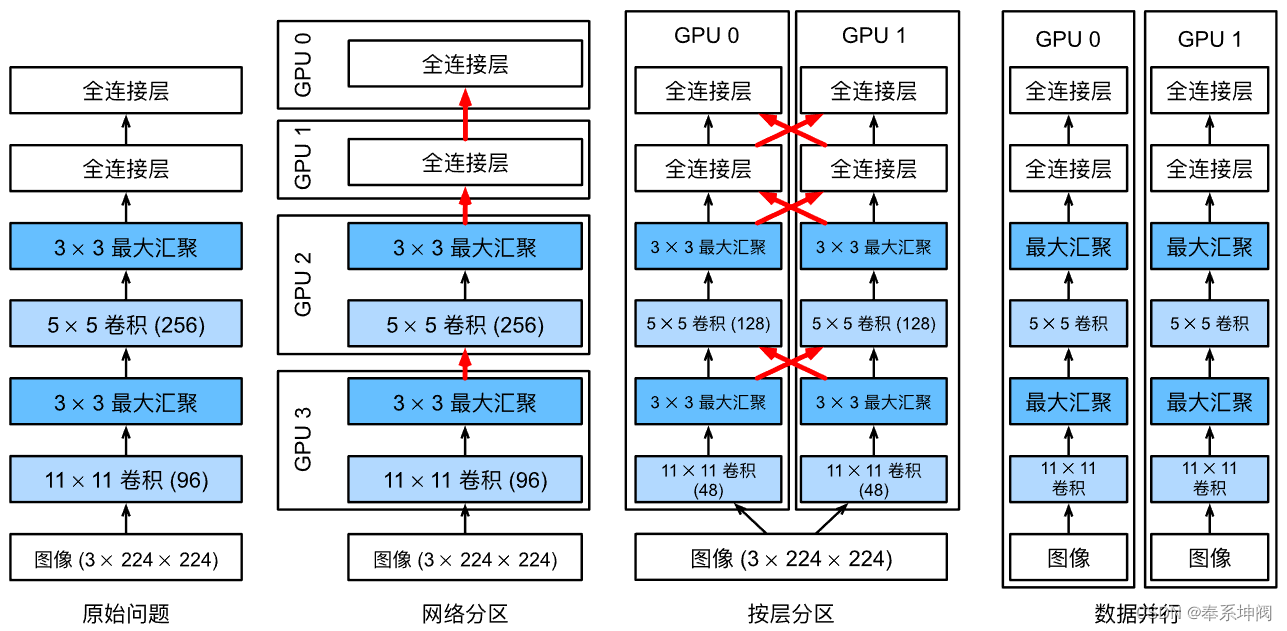
假设一台机器有 个GPU。给定需要训练的模型,虽然每个GPU上的参数值都是相同且同步的,但是每个GPU都将独立地维护一组完整的模型参数。例如,下图演示了在
时基于数据并行方法训练模型。
一般来说, 个GPU并行训练过程如下:
- 在任何一次训练迭代中,给定的随机的小批量样本都将被分成
个部分,并均匀地分配到GPU上;
- 每个GPU根据分配给它的小批量子集,计算模型参数的损失和梯度;
- 将
- 聚合梯度被重新分发到每个GPU中;
- 每个GPU使用这个小批量随机梯度,来更新它所维护的完整的模型参数集。
在实践中请注意,当在 个GPU上训练时,需要扩大小批量的大小为
的倍数,这样每个GPU都有相同的工作量,就像只在单个GPU上训练一样。因此,在16-GPU服务器上可以显著地增加小批量数据量的大小,同时可能还需要相应地提高学习率。还请注意,批量规范化也需要调整,例如,为每个GPU保留单独的批量规范化参数。
二、代码实现
import torch
from torch import nn
from d2l import torch as d2l1、实现ResNet-18网络
让我们使用一个比LeNet更有意义的网络,它依然能够容易地和快速地训练。我们选择的是 ResNet-18。因为输入的图像很小,所以稍微修改了一下。我们在开始时使用了更小的卷积核、步长和填充,而且删除了最大池化层。
def resnet18(num_classes, in_channels=1):"""稍加修改的ResNet-18模型"""def resnet_block(in_channels, out_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(d2l.Residual(in_channels, out_channels,use_1x1conv=True, strides=2))else:blk.append(d2l.Residual(out_channels, out_channels))return nn.Sequential(*blk)# 该模型使用了更小的卷积核、步长和填充,而且删除了最大池化层net = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU())net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))net.add_module("resnet_block2", resnet_block(64, 128, 2))net.add_module("resnet_block3", resnet_block(128, 256, 2))net.add_module("resnet_block4", resnet_block(256, 512, 2))net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1, 1)))net.add_module("fc", nn.Sequential(nn.Flatten(),nn.Linear(512, num_classes)))return net2、网络初始化
我们将在训练回路中初始化网络。
net = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus()
# 我们将在训练代码实现中初始化网络
print(devices)[device(type='cuda', index=0)]3、训练
如前所述,用于训练的代码需要执行几个基本功能才能实现高效并行:
- 需要在所有设备上初始化网络参数;
- 在数据集上迭代时,要将小批量数据分配到所有设备上;
- 跨设备并行计算损失及其梯度;
- 聚合梯度,并相应地更新参数。
最后,并行地计算精确度和发布网络的最终性能。除了需要拆分和聚合数据外,训练代码与单GPU实现非常相似。
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多个GPU上设置模型net = nn.DataParallel(net, device_ids=devices) # parallel:(计算机)并行的;并联的trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')接下来看看这在实践中是如何运作的。我们先在单个GPU上训练网络进行预热。
train(net, num_gpus=1, batch_size=256, lr=0.1)测试精度:0.93,12.2秒/轮,在[device(type='cuda', index=0)]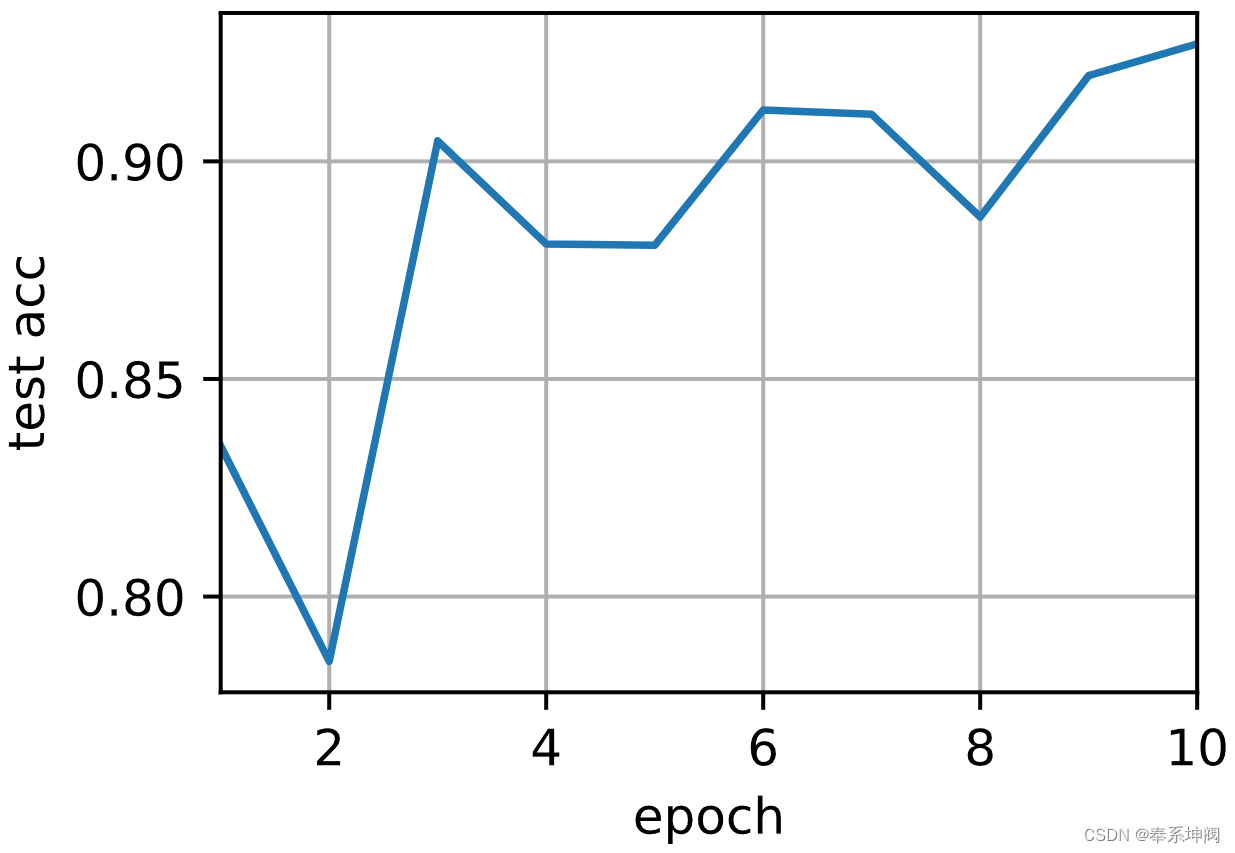
接下来我们使用2个GPU进行训练。与LeNet相比,ResNet-18的模型要复杂得多。这就是显示并行化优势的地方,计算所需时间明显大于同步参数需要的时间。因为并行化开销的相关性较小,因此这种操作提高了模型的可伸缩性。
train(net, num_gpus=2, batch_size=512, lr=0.2)测试精度:0.67,7.4秒/轮,在[device(type='cuda', index=0), device(type='cuda', index=1)]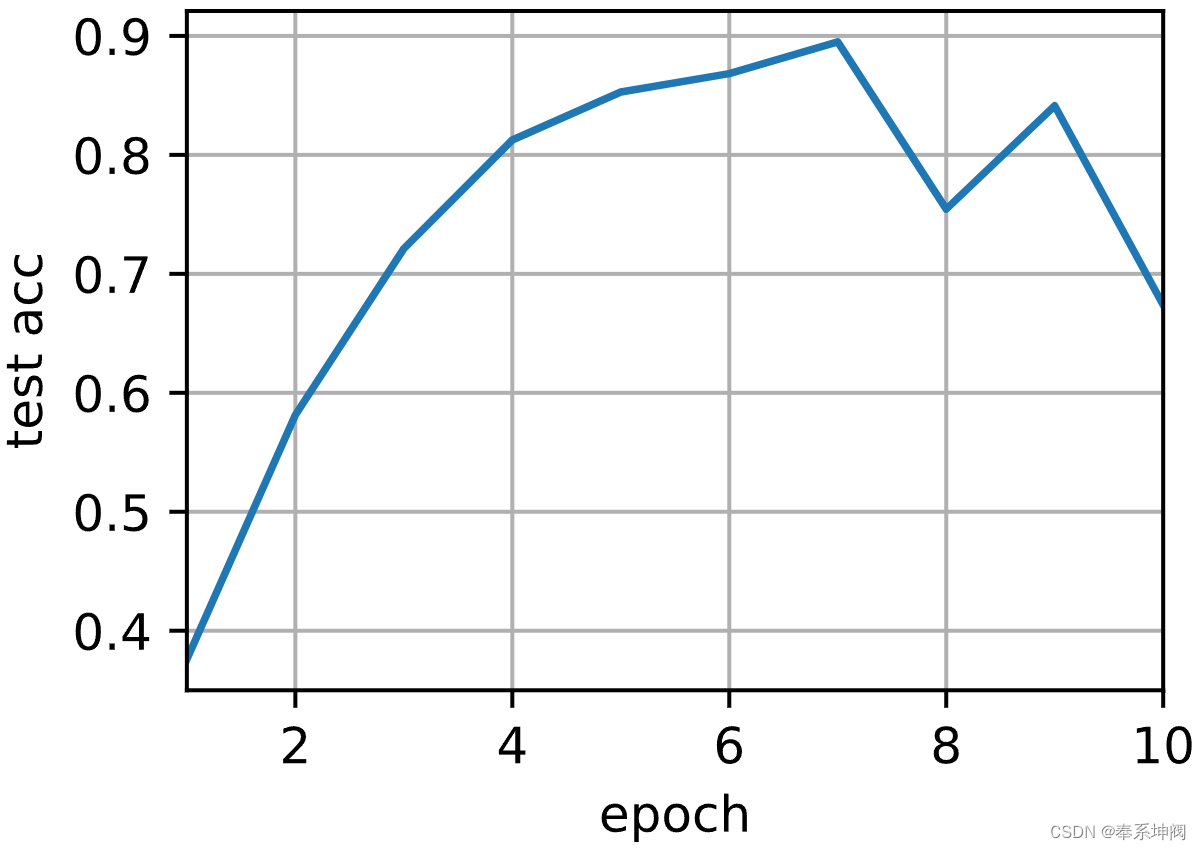
三、总结
- 神经网络可以在(可找到数据的)单GPU上进行自动评估。
- 每台设备上的网络需要先初始化,然后再尝试访问该设备上的参数,否则会遇到错误。
- 优化算法在多个GPU上自动聚合。