欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/135688206
视频生成技术确实是一个很有潜力的颠覆性技术领域,可以作为企业创新梯队的重点关注方向,最近发展很快,一直也有跟进这个方向的发展。
当前视频生成技术在哪些方面已突破,哪些方面还有卡点?,例如内容质量、一致性、视频长 度、清晰度、稳定性、复杂动作生成等。
视频生成技术,根据给定的文本、图像、视频等输入,自动生成符合描述的视频内容。视频生成技术在近年来取得了显著的进展,但也面临着一些挑战和限制。以下是一些视频生成技术的突破和卡点:
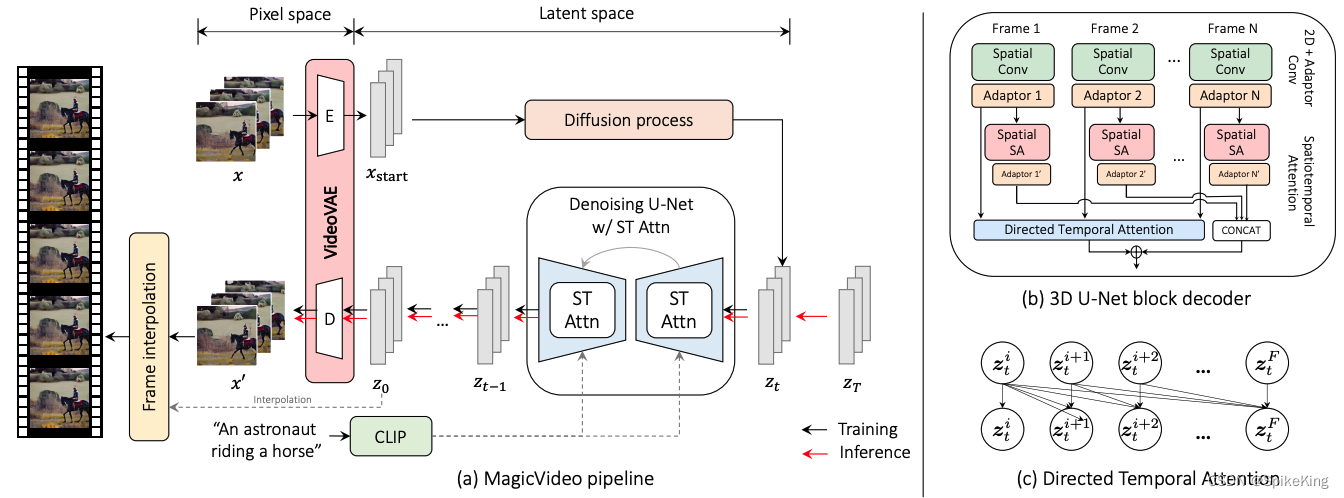
- 内容质量:视频生成技术的一个重要目标是提高生成视频的内容质量,使其更逼真、清晰和细致。目前,Phenaki,MagicVideo等。这些技术主要利用了扩散模型(Diffusion model)的优势,通过逆向降噪推断来生成图像,同时利用Transformer模型来捕捉视频的时空动态。然而,内容质量的提高也需要更大的计算资源和数据量,这可能限制了视频生成技术的普及和应用。
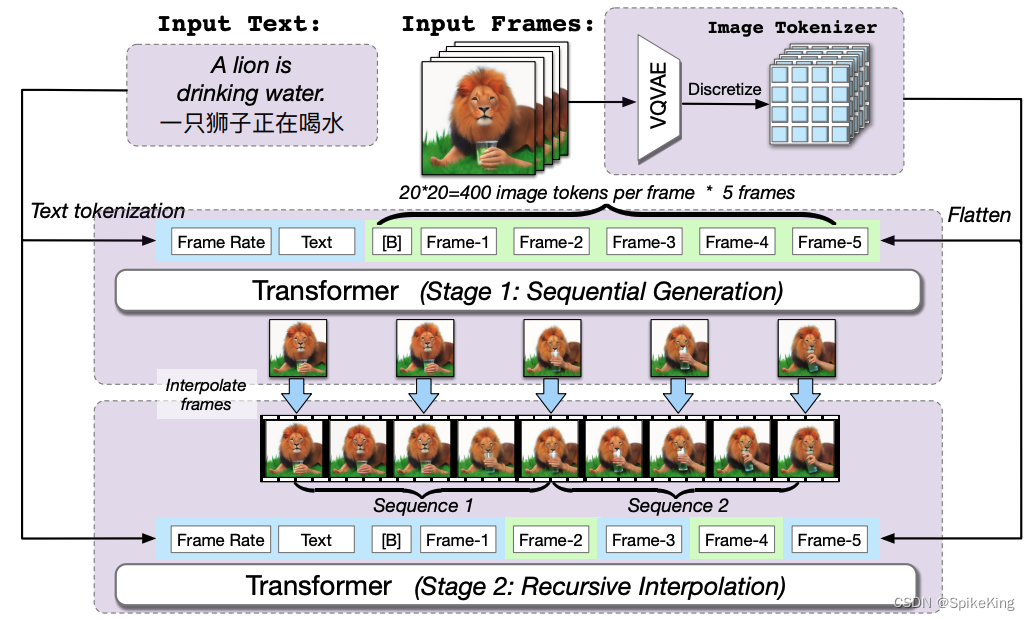
- 一致性:视频生成技术的另一个重要目标是保证生成视频的一致性,使其与输入的描述、风格和语义相匹配,同时在时间上保持流畅和连贯。目前,CogVideo能够根据中文文本描述生成视频,利用多帧率分层训练策略来对齐文本和视频剪辑。然而,一致性的保证也需要更复杂的模型设计和训练策略,例如如何处理输入的多样性、不确定性和歧义性,如何平衡生成视频的多样性和准确性,如何避免生成视频的模式崩溃(mode collapse)等。
- 视频长度:视频生成技术的一个挑战是如何生成可变长度的视频,以满足不同的应用需求。目前,Phenaki能够根据一长串的文本描述生成长达2分钟的视频,利用C-ViViT模型来压缩视频的表示,同时在时间上保持自回归。然而,视频长度的增加也会带来更多的难度,例如如何保持视频的完整性和连贯性,如何避免视频的重复和冗余,如何处理视频的转场和剪辑等。
- 清晰度:视频生成技术的一个挑战是如何提高生成视频的清晰度,使其更锐利和细腻。目前,MagicVideo能够生成1080p的视频,利用潜在扩散模型来提高视频的分辨率和细节。然而,清晰度的提高也会带来更多的问题,例如如何处理视频的噪声、模糊和失真,如何平衡视频的清晰度和自然度,如何适应不同的视频场景和风格等。
- 稳定性:视频生成技术的一个挑战是如何提高生成视频的稳定性,使其更平滑和稳定。目前,Phenaki能够生成流畅的视频,利用时间上的因果注意力来捕捉视频的时空动态。然而,稳定性的提高也会带来更多的困难,例如如何处理视频的抖动、闪烁和断层,如何适应视频的快速和复杂的运动,如何避免视频的失真和失真等。
- 复杂动作生成:视频生成技术的一个挑战是如何生成复杂的动作,使其更逼真和自然。目前,Phenaki能够根据文本描述生成人物的表情和姿态,利用预训练的文本生成图像模型来生成第一帧,然后利用C-ViViT模型来生成后续帧。然而,复杂动作的生成也需要更高的技术水平,例如如何处理视频的遮挡、遮挡和遮挡,如何生成视频的深度和透视,如何生成视频的光照和阴影等。
综上所述,视频生成技术在内容质量、一致性、视频长度、清晰度、稳定性和复杂动作生成等方面都取得了一些突破,但也还有一些卡点和难点。视频生成技术是一个前沿而有趣的研究领域,有着广阔的应用前景和挑战。
比较前沿的一些Paper:
- Phenaki: Variable Length Video Generation from Open Domain Textual Descriptions
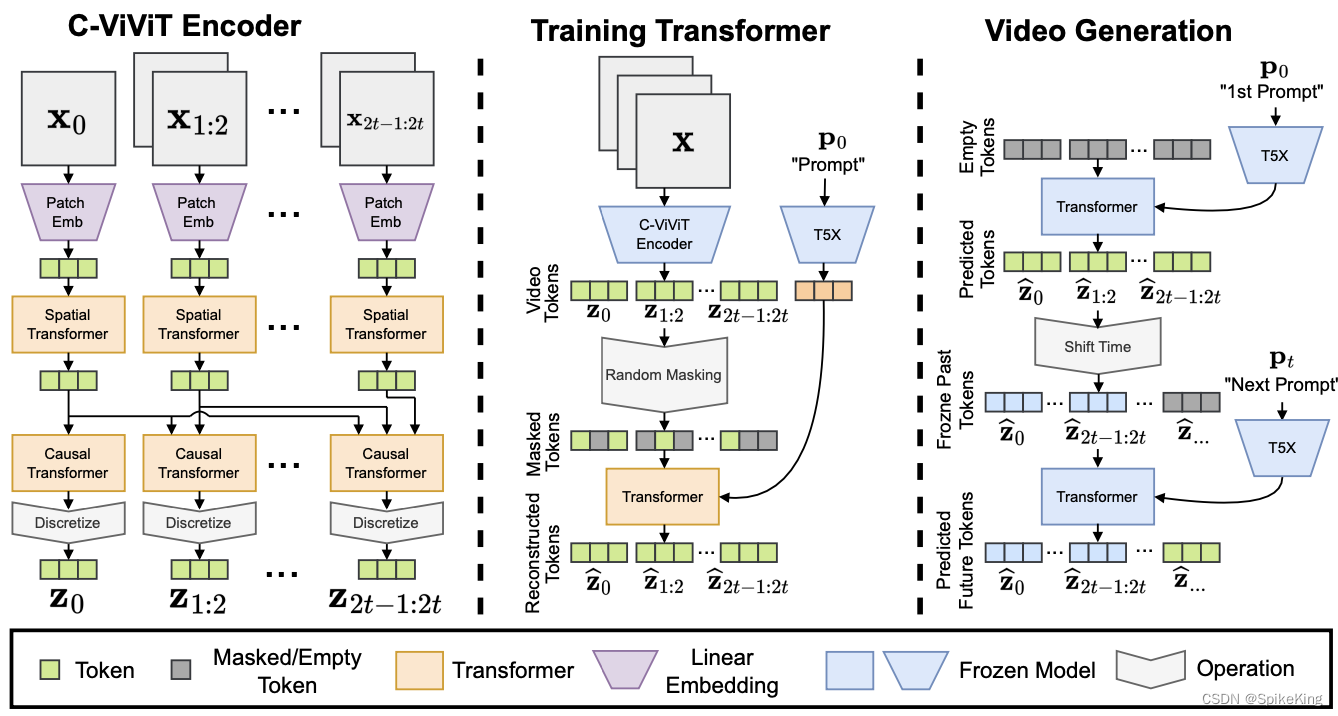
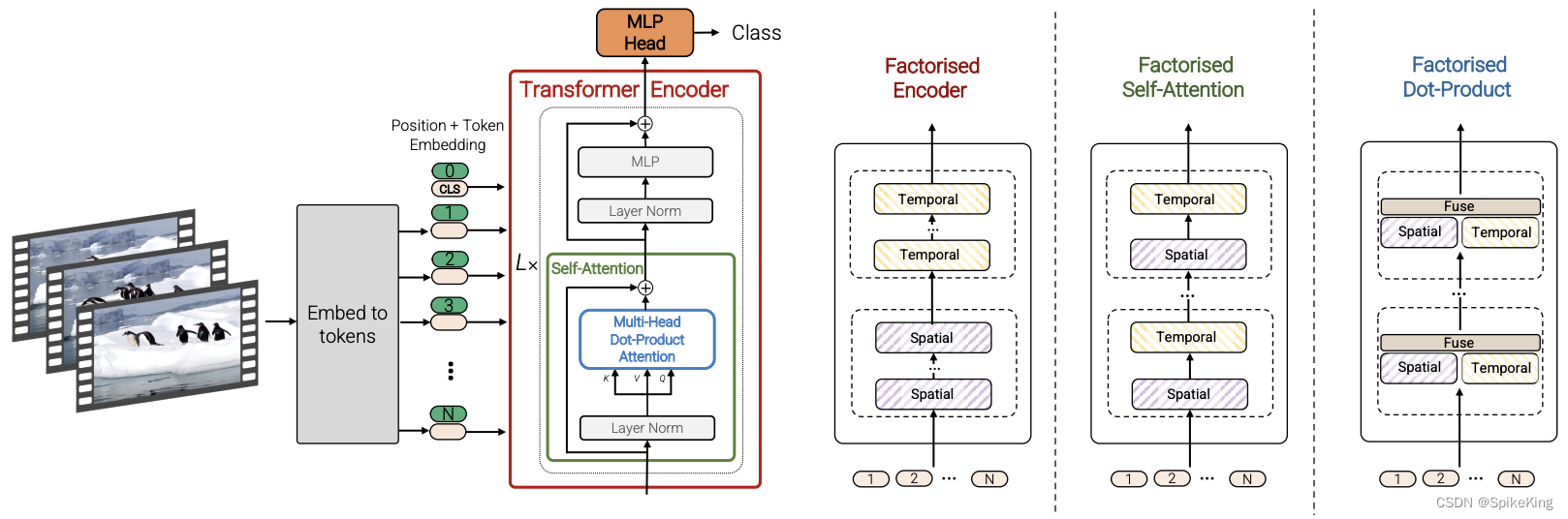
- ViViT: A Video Vision Transformer
- MagicVideo: Efficient Video Generation With Latent Diffusion
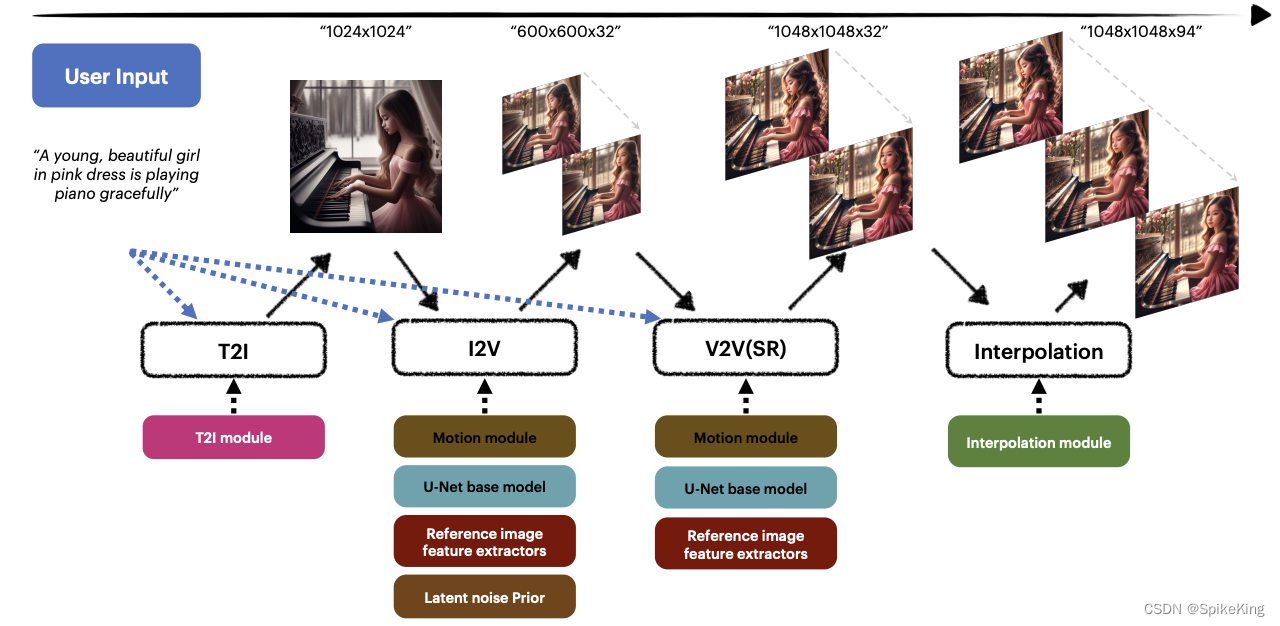
- MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
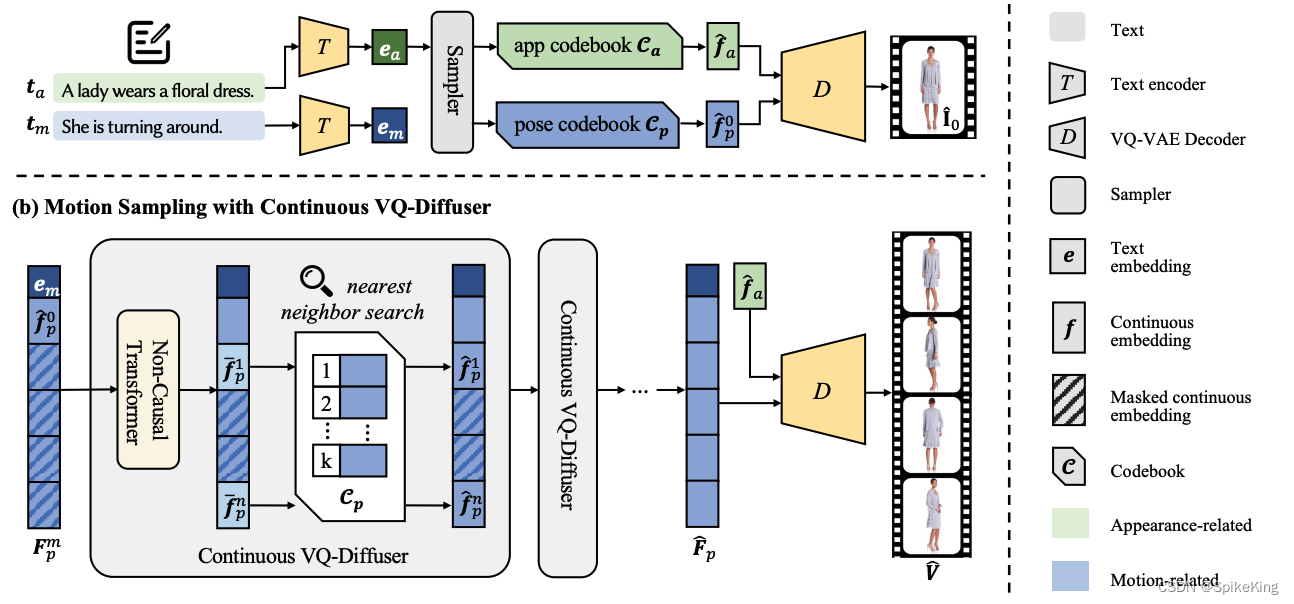
- Text2Performer: Text-Driven Human Video Generation
- CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
如果从自动化程度、效果等维度来划分视频生成的级别 (L1 到 L4,L1 就是从创意产生到 视频生成都是人工完成,效果真实,L2 是 ai 辅助素材匹配和抓取,叠加运镜效果,有 ppt 感,L3 是 ai 生成素材和视频,开始有比较逼真的效果,但仍有大动作等卡点,L4 是各环节 都是 ai 产生,效果极致),当前处于哪个阶段? L3 到 L4 需要多久,以及突破哪些技术卡点?
根据给出的视频生成的级别划分,我认为当前的视频生成技术大致处于L2到L3之间的阶段,即AI可以辅助视频制作的部分环节,例如素材匹配、抓取、剪辑、特效等,但还不能完全替代人工的创意和控制,也还不能生成高质量、高逼真、高连贯的视频内容。
要达到L4的级别,即AI可以完全自主地从创意到视频生成的各个环节,我认为还需要一定的时间和技术突破。具体来说,我觉得有以下几个方面的技术卡点:
- 视频生成的可控性:目前的视频生成技术还不能很好地满足用户的个性化需求,例如生成任意长度、任意风格、任意场景的视频,或者对视频中的元素进行编辑和修改。要提高视频生成的可控性,需要提升模型对长文本的理解能力,以及对视频的分解和重组能力。
- 视频生成的逼真度:目前的视频生成技术还不能很好地保证生成视频的质量和内容,例如生成的视频可能存在画面模糊、噪声、失真、跳帧等问题,或者视频中的物体、人物、动作、情节等不符合逻辑或常识。要提高视频生成的逼真度,需要提升模型对视频的细节和语义的捕捉能力,以及对视频的一致性和连贯性的保证能力。
- 视频生成的效率:目前的视频生成技术还需要消耗大量的计算资源和数据,以及较长的训练和生成时间,这可能限制了视频生成的普及和应用。要提高视频生成的效率,需要提升模型的压缩和优化能力,以及对视频的编码和解码能力。
视频生成技术是一个前沿而有趣的研究领域,有着广阔的应用前景和挑战。