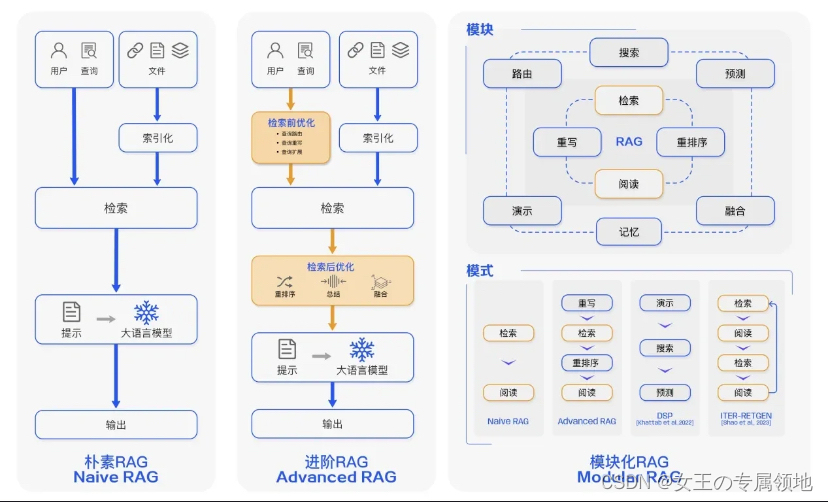
1、负载均衡流程图
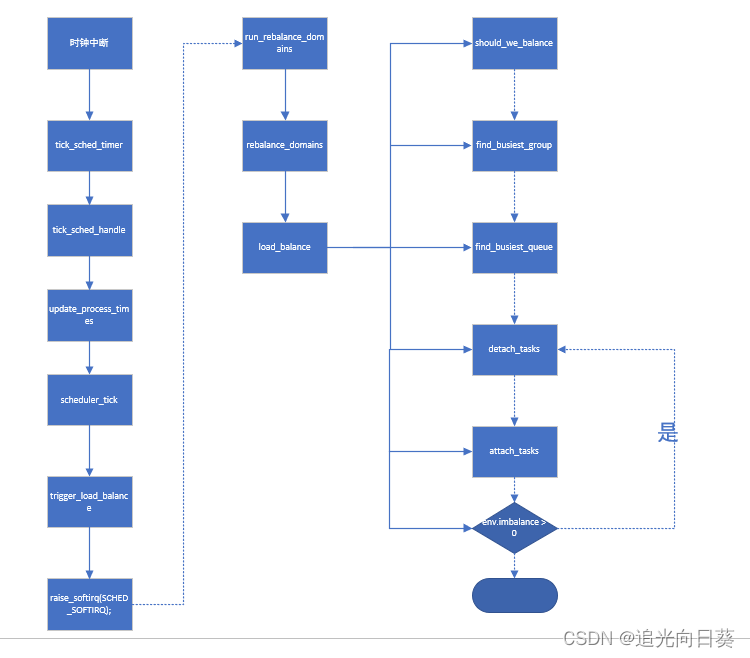
2、触发负载均衡函数trigger_load_balance
void trigger_load_balance(struct rq *rq)
{
/* Don't need to rebalance while attached to NULL domain */
if (unlikely(on_null_domain(rq)))//当前调度队列中的调度域是空的则返回
return;
if (time_after_eq(jiffies, rq->next_balance))//判断下一次均衡的时间是否到
raise_softirq(SCHED_SOFTIRQ);//触发软中断,在init_sched_fair_class中初始化open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
if (nohz_kick_needed(rq, false))
nohz_balancer_kick(false);
#endif
}
2.1 run_rebalance_domains
static __latent_entropy void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();//获取当前运行队列
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;//判断当前运行队列是空闲还是非空闲
/*
* If this cpu has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle cpus whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle cpus a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
nohz_idle_balance(this_rq, idle);//给空闲cpu一个均衡的机会进行均衡,
update_blocked_averages(this_rq->cpu);//更新阻塞平均值
#ifdef CONFIG_NO_HZ_COMMON
if (!test_bit(NOHZ_STATS_KICK, nohz_flags(this_rq->cpu)))//如果当前cpu设置了NOHZ_STATS_KICK,则跳过,否则进行rebalance_domain
rebalance_domains(this_rq, idle);
clear_bit(NOHZ_STATS_KICK, nohz_flags(this_rq->cpu));
#else
rebalance_domains(this_rq, idle);
#endif
}
2.1.1 nohz_idle_balance
static void nohz_idle_balance(struct rq *this_rq, enum cpu_idle_type idle)
{
int this_cpu = this_rq->cpu;//获取cpu
struct rq *rq;
struct sched_domain *sd;
int balance_cpu;
/* Earliest time when we have to do rebalance again */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
#ifdef CONFIG_SPRD_CORE_CTL
cpumask_t cpus;
#endif
if (idle != CPU_IDLE ||
!test_bit(NOHZ_BALANCE_KICK, nohz_flags(this_cpu)))//如果cpu不是空闲,或者设置了NOHZ_BALANCE_KICK,则返回
goto end;
/*
* This cpu is going to update the blocked load of idle CPUs either
* before doing a rebalancing or just to keep metrics up to date. we
* can safely update the next update timestamp
*/
rcu_read_lock();//rcu读锁
sd = rcu_dereference(this_rq->sd);//获取当前this_rq的调度域
/*
* Check whether there is a sched_domain available for this cpu.
* The last other cpu can have been unplugged since the ILB has been
* triggered and the sched_domain can now be null. The idle balance
* sequence will quickly be aborted as there is no more idle CPUs
*/
if (sd)
nohz.next_update = jiffies + msecs_to_jiffies(LOAD_AVG_PERIOD);//计算下一次空闲cpu负载均衡的时间
rcu_read_unlock();
cpumask_andnot(&cpus, nohz.idle_cpus_mask, cpu_isolated_mask);移除隔离的cpu
for_each_cpu(balance_cpu, &cpus) {//遍历空闲cpu
if (balance_cpu == this_cpu || !idle_cpu(balance_cpu))//如果均衡cpu是当前cpu或者不是空闲的,则进行下一个循环。
continue;
/*
* If this cpu gets work to do, stop the load balancing
* work being done for other cpus. Next load
* balancing owner will pick it up.
*/
if (need_resched())//判断如果此cpu需要调度,则停止均衡
break;
rq = cpu_rq(balance_cpu);//获取要均衡cpu的运行队列
/*
* If time for next balance is due,
* do the balance.
*/
if (time_after_eq(jiffies, rq->next_balance)) {//判断均衡时间有没有到
struct rq_flags rf;
rq_lock_irq(rq, &rf);//获取运行队列锁
update_rq_clock(rq);//更新运行队列时钟
cpu_load_update_idle(rq);//更新队列负载
rq_unlock_irq(rq, &rf);//释放锁
update_blocked_averages(balance_cpu);//更新均衡cpu的阻塞平均值
/*
* This idle load balance softirq may have been
* triggered only to update the blocked load and shares
* of idle CPUs (which we have just done for
* balance_cpu). In that case skip the actual balance.
*/
if (!test_bit(NOHZ_STATS_KICK, nohz_flags(this_cpu)))//如果没有设置NOHZ_STATS_KICK,则进行均衡
rebalance_domains(rq, idle);//域负载均衡
}
if (time_after(next_balance, rq->next_balance)) {//更新下一次均衡时间
next_balance = rq->next_balance;
update_next_balance = 1;
}
}
/*
* next_balance will be updated only when there is a need.
* When the CPU is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance))//更新下一次均衡时间
nohz.next_balance = next_balance;
end:
clear_bit(NOHZ_BALANCE_KICK, nohz_flags(this_cpu));
}
2.2 rebalance_domains函数
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
unsigned long interval;
struct sched_domain *sd;
/* Earliest time when we have to do rebalance again */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
rcu_read_lock();
for_each_domain(cpu, sd) {//遍历调度域中每个cpu
/*
* Decay the newidle max times here because this is a regular
* visit to all the domains. Decay ~1% per second.
*/
if (time_after(jiffies, sd->next_decay_max_lb_cost)) {//判断衰减时间有没有到
sd->max_newidle_lb_cost =
(sd->max_newidle_lb_cost * 253) / 256;//衰减百分之一
sd->next_decay_max_lb_cost = jiffies + HZ;//衰减时间更新
need_decay = 1;
}
max_cost += sd->max_newidle_lb_cost;
if (energy_aware() && !sd_overutilized(sd) && !sd->parent)//在使能了eas且调度域没有过载已及这是个根调度域时跳过
continue;
if (!(sd->flags & SD_LOAD_BALANCE)) {//判断此调度域是否设置了SD_LOAD_BALANCE
if (time_after_eq(jiffies,
sd->groups->sgc->next_update))
update_group_capacity(sd, cpu);//更新cpu调度组能力
continue;
}
/*
* Stop the load balance at this level. There is another
* CPU in our sched group which is doing load balancing more
* actively.
*/
if (!continue_balancing) {//判断是否停止均衡
if (need_decay)
continue;
break;
}
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);//得到调度域的均衡间隔
need_serialize = sd->flags & SD_SERIALIZE;//判断是否需要串行化
if (need_serialize) {
if (!spin_trylock(&balancing))//获取锁
goto out;
}
if (time_after_eq(jiffies, sd->last_balance + interval)) {//判断均衡时间是否到
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {//进行均衡
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;//获取cpu空闲状态
}
sd->last_balance = jiffies;//更新均衡时间
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);//获取均衡间隔
}
if (need_serialize)
spin_unlock(&balancing);//释放锁
out:
if (time_after(next_balance, sd->last_balance + interval)) {//判断next_balance是否需要更新
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
if (need_decay) {//判断是否需要衰减
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
rcu_read_unlock();
/*
* next_balance will be updated only when there is a need.
* When the cpu is attached to null domain for ex, it will not be
* updated.
*/
if (likely(update_next_balance)) {
rq->next_balance = next_balance;//更新运行队列下一次均衡时间
#ifdef CONFIG_NO_HZ_COMMON
/*
* If this CPU has been elected to perform the nohz idle
* balance. Other idle CPUs have already rebalanced with
* nohz_idle_balance() and nohz.next_balance has been
* updated accordingly. This CPU is now running the idle load
* balance for itself and we need to update the
* nohz.next_balance accordingly.
*/
if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance))//如果cpu状态是空闲且运行队列的下次均衡时间小于空闲cpu的下次均衡时间
nohz.next_balance = rq->next_balance;//更新空闲cpu的下次均衡时间
#endif
}
}
2.2.1 load_balance
static int load_balance(int this_cpu, struct rq *this_rq,
struct sched_domain *sd, enum cpu_idle_type idle,
int *continue_balancing)
{
int ld_moved, cur_ld_moved, active_balance = 0;
struct sched_domain *sd_parent = lb_sd_parent(sd) ? sd->parent : NULL;
struct sched_group *group;
struct rq *busiest;
struct rq_flags rf;
struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask);
struct lb_env env = {//负载平衡环境,包含了一组与负载平衡相关的参数和状态信息
.sd = sd,//调度域
.dst_cpu = this_cpu,//均衡给此cpu
.dst_rq = this_rq,//均衡给此队列
.dst_grpmask = sched_group_span(sd->groups),//目标调度组掩码
.idle = idle,//cpu状态
.loop_break = sched_nr_migrate_break,//迁移间隔
.cpus = cpus,
.fbq_type = all,
.tasks = LIST_HEAD_INIT(env.tasks),
};
cpumask_and(cpus, sched_domain_span(sd), cpu_active_mask);//将调度域中处于active状态的cpu挑选出来
schedstat_inc(sd->lb_count[idle]);//更新负载均衡idle类型的计数
redo:
if (!should_we_balance(&env)) {//判断是否应该均衡
*continue_balancing = 0;
goto out_balanced;
}
group = find_busiest_group(&env);//找到最繁忙的组
if (!group) {
schedstat_inc(sd->lb_nobusyg[idle]);
goto out_balanced;
}
busiest = find_busiest_queue(&env, group);//找到最繁忙的队列
if (!busiest) {
schedstat_inc(sd->lb_nobusyq[idle]);
goto out_balanced;
}
BUG_ON(busiest == env.dst_rq);//最繁忙的队列不等于目的队列
schedstat_add(sd->lb_imbalance[idle], env.imbalance);更新负载均衡idle类型不均衡的计数
env.src_cpu = busiest->cpu;//最繁忙的队列的cpu给要均衡的cpu
env.src_rq = busiest;//最繁忙的队列给要均衡的队列
ld_moved = 0;
if (busiest->nr_running > 1) {最繁忙的运行队列中的task要大于1
/*
* Attempt to move tasks. If find_busiest_group has found
* an imbalance but busiest->nr_running <= 1, the group is
* still unbalanced. ld_moved simply stays zero, so it is
* correctly treated as an imbalance.
*/
env.flags |= LBF_ALL_PINNED;
env.loop_max = min(sysctl_sched_nr_migrate, busiest->nr_running);//最大循环的次数
more_balance:
rq_lock_irqsave(busiest, &rf);//获取锁
update_rq_clock(busiest);//更新最忙的队列的时钟
/*
* cur_ld_moved - load moved in current iteration
* ld_moved - cumulative load moved across iterations
*/
cur_ld_moved = detach_tasks(&env, &rf);//出队,将要迁移的task从src cpu中移除并返回出队的个数
/*
* We've detached some tasks from busiest_rq. Every
* task is masked "TASK_ON_RQ_MIGRATING", so we can safely
* unlock busiest->lock, and we are able to be sure
* that nobody can manipulate the tasks in parallel.
* See task_rq_lock() family for the details.
*/
rq_unlock(busiest, &rf);//释放锁
if (cur_ld_moved) {
attach_tasks(&env);//入队,将移除的task加入到新的队列中
ld_moved += cur_ld_moved;
}
local_irq_restore(rf.flags);//恢复本地的中断状态
if (env.flags & LBF_NEED_BREAK) {//判断是否设置了LBF_NEED_BREAK
env.flags &= ~LBF_NEED_BREAK;
goto more_balance;
}
/*
* Revisit (affine) tasks on src_cpu that couldn't be moved to
* us and move them to an alternate dst_cpu in our sched_group
* where they can run. The upper limit on how many times we
* iterate on same src_cpu is dependent on number of cpus in our
* sched_group.
*
* This changes load balance semantics a bit on who can move
* load to a given_cpu. In addition to the given_cpu itself
* (or a ilb_cpu acting on its behalf where given_cpu is
* nohz-idle), we now have balance_cpu in a position to move
* load to given_cpu. In rare situations, this may cause
* conflicts (balance_cpu and given_cpu/ilb_cpu deciding
* _independently_ and at _same_ time to move some load to
* given_cpu) causing exceess load to be moved to given_cpu.
* This however should not happen so much in practice and
* moreover subsequent load balance cycles should correct the
* excess load moved.
*/
if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) {//如果sched domain仍然未达均衡均衡状态,并且在之前的均衡过程中,有因为affinity的原因导致任务无法迁移到dest cpu,这时候要继续在src rq上搜索任务,迁移到备选的dest cpu,因此,这里再次发起均衡操作。这里的均衡上下文的dest cpu设定为备选的cpu,loop也被清零,重新开始扫描。
/* Prevent to re-select dst_cpu via env's cpus */
cpumask_clear_cpu(env.dst_cpu, env.cpus);
env.dst_rq = cpu_rq(env.new_dst_cpu);//备用cpu队列
env.dst_cpu = env.new_dst_cpu;
env.flags &= ~LBF_DST_PINNED;
env.loop = 0;
env.loop_break = sched_nr_migrate_break;
/*
* Go back to "more_balance" rather than "redo" since we
* need to continue with same src_cpu.
*/
goto more_balance;
}
/*
* We failed to reach balance because of affinity.
*/
if (sd_parent) {//如果父调度域存在
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if ((env.flags & LBF_SOME_PINNED) && env.imbalance > 0)//由于亲和性原因不能在目标cpu上迁移而设置了LBF_SOME_PINNED
*group_imbalance = 1;
}
/* All tasks on this runqueue were pinned by CPU affinity */
if (unlikely(env.flags & LBF_ALL_PINNED)) {//设置了LBF_ALL_PINNED,由于亲和性原因在这个运行队列上的所有的任务不能迁移
cpumask_clear_cpu(cpu_of(busiest), cpus);//清除在cpus中的busiest所在的cpu
/*
* Attempting to continue load balancing at the current
* sched_domain level only makes sense if there are
* active CPUs remaining as possible busiest CPUs to
* pull load from which are not contained within the
* destination group that is receiving any migrated
* load.
*/
if (!cpumask_subset(cpus, env.dst_grpmask)) {//如果选中的busiest cpu上的任务全部都是通过affinity锁定在了该cpu上,那么清除该cpu(为了确保下轮均衡不考虑该cpu),再次发起均衡。这种情况下,需要重新搜索source cpu,因此跳转到redo
env.loop = 0;
env.loop_break = sched_nr_migrate_break;
goto redo;
}
goto out_all_pinned;
}
}
if (!ld_moved) {//如果前面迁移的task如果为0,则走这里
schedstat_inc(sd->lb_failed[idle]);//增加负载均衡lb_failed计数
/*
* Increment the failure counter only on periodic balance.
* We do not want newidle balance, which can be very
* frequent, pollute the failure counter causing
* excessive cache_hot migrations and active balances.
*/
if (idle != CPU_NEWLY_IDLE)//如果cpu状态不是刚刚处于空闲状态
if (env.src_grp_nr_running > 1)//要迁移的调度组中的队列个数大于1
sd->nr_balance_failed++;//失败计数加一
if (need_active_balance(&env)) {//判断是否要启动active balance。所谓activebalance就是把当前正在运行的任务迁移到dest cpu上。也就是说经过前面一番折腾,runnable的任务都无法迁移到dest cpu,从而达到均衡,那么就考虑当前正在运行的任务
unsigned long flags;
raw_spin_lock_irqsave(&busiest->lock, flags);
/* don't kick the active_load_balance_cpu_stop,
* if the curr task on busiest cpu can't be
* moved to this_cpu
*/
if (!cpumask_test_cpu(this_cpu, &busiest->curr->cpus_allowed)) {//在启动active balance之前,先看看busiestcpu上当前正在运行的任务是否可以运行在dest cpu上。如果不可以的话,那么不再试图执行均衡操作,跳转到out_one_pinned
raw_spin_unlock_irqrestore(&busiest->lock,
flags);
env.flags |= LBF_ALL_PINNED;
goto out_one_pinned;
}
/*
* ->active_balance synchronizes accesses to
* ->active_balance_work. Once set, it's cleared
* only after active load balance is finished.
*/
#ifdef CONFIG_SPRD_CORE_CTL
if (!busiest->active_balance &&
!cpu_isolated(cpu_of(busiest))) {
#else
if (!busiest->active_balance) {//busiest cpu运行队列上设置active balance的标记
#endif
busiest->active_balance = 1;
busiest->push_cpu = this_cpu;
active_balance = 1;
}
raw_spin_unlock_irqrestore(&busiest->lock, flags);
if (active_balance) {//将正在运行的busiest cpu 正在运行的任务停止并进行迁移
stop_one_cpu_nowait(cpu_of(busiest),
active_load_balance_cpu_stop, busiest,
&busiest->active_balance_work);
}
/* We've kicked active balancing, force task migration. */
sd->nr_balance_failed = sd->cache_nice_tries+1;
}
} else
sd->nr_balance_failed = 0;//完成了至少一个任务迁移
if (likely(!active_balance)) {
/* We were unbalanced, so reset the balancing interval */
sd->balance_interval = sd->min_interval;//重新设置均衡间隔
} else {
/*
* If we've begun active balancing, start to back off. This
* case may not be covered by the all_pinned logic if there
* is only 1 task on the busy runqueue (because we don't call
* detach_tasks).
*/
if (sd->balance_interval < sd->max_interval)
sd->balance_interval *= 2;
}
goto out;
out_balanced:
/*
* We reach balance although we may have faced some affinity
* constraints. Clear the imbalance flag if it was set.
*/
if (sd_parent) {
int *group_imbalance = &sd_parent->groups->sgc->imbalance;
if (*group_imbalance)
*group_imbalance = 0;
}
out_all_pinned://由于所有的亲和性原因
/*
* We reach balance because all tasks are pinned at this level so
* we can't migrate them. Let the imbalance flag set so parent level
* can try to migrate them.
*/
schedstat_inc(sd->lb_balanced[idle]);
sd->nr_balance_failed = 0;
out_one_pinned://由某个task亲和性原因
ld_moved = 0;
/*
* idle_balance() disregards balance intervals, so we could repeatedly
* reach this code, which would lead to balance_interval skyrocketting
* in a short amount of time. Skip the balance_interval increase logic
* to avoid that.
*/
if (env.idle == CPU_NEWLY_IDLE)
goto out;
/* tune up the balancing interval */
if (((env.flags & LBF_ALL_PINNED) &&
sd->balance_interval < MAX_PINNED_INTERVAL) ||
(sd->balance_interval < sd->max_interval))
sd->balance_interval *= 2;
out:
return ld_moved;
}
![[小程序]API、数据与事件](https://img-blog.csdnimg.cn/direct/d4b60f2fa98e47baaef0d5ef1ab1a675.png)


![[计算机网络]基本概念](https://img-blog.csdnimg.cn/direct/f55102cf38bb4aaeb850f691e5ec0699.png)