概述
什么是ckman
ckman,全称是ClickHouse Management Console, 即ClickHouse管理平台。它是由擎创科技数据库团队主导研发的一款用来管理和监控ClickHouse集群的可视化运维工具。目前该工具已在github上开源,开源地址为:github.com/housepower/ckman。
为什么要有ckman
我们不妨思考一下这样的场景:如果要部署一个ClickHouse集群,需要怎么做?
首先,我们需要在所有ClickHouse节点上安装ClickHouse的rpm包,然后,需要修改配置文件,包括但不限于config.xml、users.xml、metrika.xml。注意,是所有节点上都要修改,修改完成后需要依次启动各个节点。
当集群规模不大,这些操作手动去完成可能不觉得有什么,但是如果集群规模比较大,单个集群的节点达到了上百台甚至上千台,这时候要手工去每台机器上去操作,显然变得不太现实。
如果需要往集群增加一个节点呢?
我们需要在已有的节点上的metrika.xml配置文件中加上该节点,然后在新增节点上安装rpm包,修改metrika.xml,启动ClickHouse服务,最后还要同步其他节点上的schema表结构,至此才能完成。
删除节点亦如是。
如果要升级集群呢?我们不仅需要在每个节点上重新安装升级rpm包,还需要考虑一些其他的问题:需不需要停服务?如果升级失败了怎么办?
总之,ClickHouse的集群运维,如果靠人工去做,不仅繁琐,容易出现各种问题,当集群规模变大后,也变得不切实际。
这时候,ckman的出现,就可以完美解决上述的问题。ckman将这些运维操作都集成在管理界面中,用户只需要在web界面上通过简单的信息配置,点击鼠标,就可以完成所有的配置工作,而无需关注其他细节,也减少了出错的可能。
ckman能做什么
ckman主要的功能是管理和监控ClickHouse集群。因此,它的操作对象只能是ClickHouse集群,而不是单个ClickHouse节点。
管理ClickHouse集群
- 部署
ClickHouse集群 - 导入
ClickHouse集群 - 升级
ClickHouse集群 - 增加或删除集群节点
- 对集群(或节点)进行启停
- 实现数据再均衡
- 存储策略配置
- 用户权限配额控制
- 集群配置文件最佳实践及定制化能力
- 简单
SQL查询能力
监控ClickHouse集群
- 监控
ClickHouse Query - 监控节点系统性能指标(
CPU,Memory,IO等) - 监控
Zookeeper相关指标 - 监控集群分布式表相关指标
- 监控副本状态相关指标
- 监控慢
SQL等相关指标
如何部署ckman
见ckman部署文档。
如何使用源码编译ckman
编译依赖
由于ckman使用golang实现,因此需要提前安装go(请使用>=1.17版本);
如果需要编译成rpm包或deb包,需要安装nfpm:
wget -q https://github.com/goreleaser/nfpm/releases/download/v2.15.1/nfpm_2.15.1_Linux_x86_64.tar.gz tar -xzvf nfpm_2.15.1_Linux_x86_64.tar.gz cp nfpm /usr/local/bin
编译前端需要安装yarn。在CentOS 7上安装yarn: (参考How to Install Yarn on CentOS 7 | Linuxize)
$ curl --silent --location https://dl.yarnpkg.com/rpm/yarn.repo | sudo tee /etc/yum.repos.d/yarn.repo
$ sudo rpm --import https://dl.yarnpkg.com/rpm/pubkey.gpg
$ sudo yum install yarn
$ yarn --version
在其他平台上安装yarn,请参考yarn官方文档。
编译命令
tar.gz包编译
make package VERSION=x.x.x
以上命令会编译成打包成一个tar.gz安装包,该安装包解压即可用。
VERSION是指定的版本号,如果不指定,则默认取git describe --tags --dirty的结果作为版本号。
rpm包编译
make rpm VERSION=x.x.x
docker编译
鉴于编译环境的诸多依赖,配置起来可能比较麻烦,因此也提供了docker编译的方式,直接运行下面的命令即可:
make docker-build VERSION=x.x.x
如果想利用docker编译rpm版本,可以先进入docker环境,再编译:
make docker-sh make rpm VERSION=x.x.x
前端单独编译
为了减少编译上的麻烦,ckman代码已经将前端代码编译好,做成静态链接放在static/dist目录下,但是仍然将前端代码以submodule的形式嵌入在frontend目录下,如果想要自己编译前端,在提前安装好前端编译依赖后,可以使用如下命令:
cd frontend yarn cd .. make frontend
架构设计

配置文件
server
-
ip- 服务端的ip地址,如果不指定,取默认路由的ip
-
portckman的监听端口- 默认为
8808
-
https- 是否监听
https - 默
- 认为
false
- 是否监听
-
certfilehttps的证书文件路径,如果开启了https,必须要有证书文件- 默认使用
conf下的server.crt - 注意证书文件的路径
ckman需要有访问权限
-
keyfilehttps的key文件路径,如果开启了https,必须要有key文件- 默认使用
conf下的server.key - 注意
key文件的路径ckman需要有访问权限
-
pprof- 是否支持
pprof监控 - 默认为
true
- 是否支持
-
session_timeout- 会话超时时间,如果超过该时间没有对
ckman进行任何操作,则token失效,需要重新登录 - 默认超时时间为
3600秒
- 会话超时时间,如果超过该时间没有对
-
public_key- 用来接入
ckman的公钥 ckman可通过RSA配置公钥的方式跳过token鉴权,只需要在客户端对header配置userToken,并对userToken使用私钥加密,然后在ckman服务端使用该公钥进行解密即可。
- 用来接入
-
swagger_enable- 是否开启
swagger文档 - 默认不开启
- 是否开启
-
task_interval- 执行异步运维动作的扫描时间间隔
- 前端请求部署、升级、销毁以及增删节点等比较耗时的操作时,
ckman先记录状态,然后使用另外的协程异步扫描处理,异步扫描的时间间隔通过该参数可配,默认为5秒
-
persistant_policy- 持久化策略,主要用来存储集群的配置信息,包括集群配置、逻辑集群映射关系 、查询语句历史记录、运维操作状态等。
- 持久化策略支持
local、mysql和postgreslocal:存储到本地,在conf目录下生成一个clusters.json文件,不支持集群,为默认配置mysql:持久化到mysql,支持ckman集群,支持HA,需要提前创建数据库,数据库编码为UTF-8,不需要创建表,ckman会自动创建数据库表postgres:持久化到postgres,支持ckman集群,支持HA,需要提前创建数据库,并且需要提前创建数据库表。建表语句内置在dbscript/postgres.sql中。dm8: 持久化到达梦数据库,支持ckman集群,支持HA,需要提前创建用户,不需要自动创建表- 除
local策略外,其他持久化策略都依赖persistent_config中的配置项,当然local也可以配置该项。
clickhouse
clickhouse连接池相关设置。
max_open_conns:- 每个ck节点最大可以打开的连接数
max_idle_conns:- 每隔ck节点最大的空闲连接数
conn_max_idle_time:- 每个ck连接最大空闲时间
log
level- 日志打印级别
- 默认为
INFO - 支持
DEBUG、INFO、WARN、ERROR、PANIC、FATAL
max_count- 滚动日志数量
- 默认为
5个
max_age- 日志生命有效期
- 默认为
10天
cron
定时任务相关的配置。支持cron表达式,格式为:Second | Minute | Hour | Dom | Month | Dow | Descriptor
-
enabled:- 是否开启定时任务
-
sync_logic_schema- 同步逻辑表的
schema定时任务, 默认为1分钟一次。
- 同步逻辑表的
-
watch_cluster_status- 针对tgz集群,监控节点状态,如果有节点非正常挂掉,自动拉起,默认3分钟一次
-
sync_dist_schema- 同步集群内物理表的
schema,默认10分钟一次
- 同步集群内物理表的
persistent_config
mysql & postgres & dm8
mysql和postgres配置项基本一致,主要涉及以下配置项:
-
host- 连接数据库的
ip地址
- 连接数据库的
-
port- 连接数据库的端口号,如
mysql默认为3306,postgres默认为5432
- 连接数据库的端口号,如
-
user- 连接数据库的用户
-
password-
连接数据库的密码,可选择是否加密,如果需要加密,可使用下面命令获得密码的密文 。
ckman --encrypt 123456 E310E892E56801CED9ED98AA177F18E6
-
如果数据库密码选择加密,请使用
ENC()将密文包含起来,如:
password: ENC(E310E892E56801CED9ED98AA177F18E6)
-
-
database- 需要连接的数据库,需提前创建,并且保证编码为
UTF-8
- 需要连接的数据库,需提前创建,并且保证编码为
local
format- 本地文件格式,支持
JSON和yaml,默认为json
- 本地文件格式,支持
config_dir- 本地文件的目录,需要填写路径,默认为
ckman工作路径的conf目录下
- 本地文件的目录,需要填写路径,默认为
config_file- 本地文件的文件名,默认为
clusters
- 本地文件的文件名,默认为
nacos
enabled- 是否开启
nacos - 默认为不开启
- 是否开启
hostsnacos服务的ip地址- 可以配置多组
portnacos服务的端口
user_name- 登录
nacos的用户名
- 登录
password- 登录
nacos的密码,加密规则同持久化策略数据库密码,同样,如果需要加密,需要以ENC()将密文包含起来。
- 登录
namespace- 指定
nacos的namespace,默认为DEFAULT
- 指定
group- 向
nacos注册的服务所在的组 - 默认为
DEFAULT_GROUP
- 向
data_id- 向
nacos注册服务名称、数据项名称 - 默认为
ckman
- 向
示例如下:
// ckman config file
// All password can be encrypt by ENC(xxxxxxxxx),
// you can get encrypt password by using: ./ckman --encrypt 123456 to get password like: E310E892E56801CED9ED98AA177F18E6
// If password not including by ENC(), that means it's a plaintext.
// hjson(https://hjson.github.io/) is easy for humans to read and write.{"server":{"port": 8808,"https": false,//certfile://keyfile:"pprof": true,"session_timeout": 3600,//support local, mysql, postgres"persistent_policy": "local","task_interval": 5//public_key:},"log":{"level": "INFO","max_count": 5,// megabyte"max_size": 10,// day"max_age": 10},// clickhouse connect pool options"clickhouse":{//sets the maximum number of open connections to the database"max_open_conns": 10,//sets the maximum number of connections in the idle"max_idle_conns": 2,//sets the maximum amount of time a connection may be idle."conn_max_idle_time": 10},// cron job task"cron":{"sync_logic_schema": "0 * * * * ?","watch_cluster_status": "0 */3 * * * ?","sync_dist_schema": "30 */10 * * * ?"},//"persistent_config":{ // // if peristent_policy is mysql, must config this// "mysql":{// "host": "127.0.0.1",// "port": 3306,// "user": "root",// // you can use ./ckman --encrypt 123456 to get password like: E310E892E56801CED9ED98AA177F18E6// "password": "ENC(E310E892E56801CED9ED98AA177F18E6)",// // database must be created before start ckman// "database": "ckman_db"// },// "local":{// "format": "json"// "config_dir": "/etc/ckman/conf"// "config_file": "clusters"// }//},"nacos":{"enabled": false,"hosts":["127.0.0.1"],"port": 8848,"user_name": "nacos",// you can use './ckman --encrypt nacos' to get password like: A7561228101CB07938FAFF00C4444546"password": "ENC(A7561228101CB07938FAFF00C4444546)"//namespace:}
}
功能介绍
集群管理
部署集群
点击主页的 Create a ClickHouse Cluster,就会进入创建集群的界面:
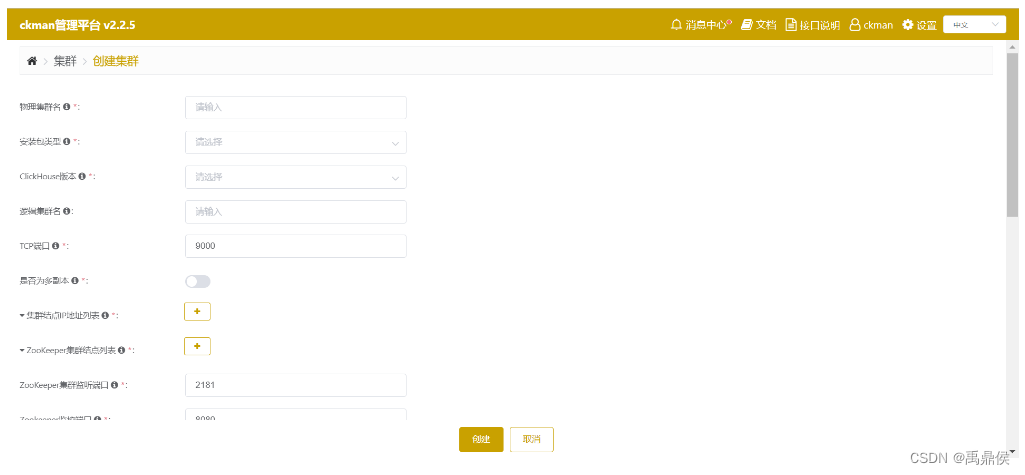
需要填写的项主要有以下:
Cluster Name: 集群的名字,注意不要和ckman已有的名字重合Package Type: 安装包类型,用来区分平台和架构,不需要自己填写,上传安装包后可通过下拉框选择。
- 如果选择的平台和架构不正确,如在
arm的机器上部署x86的安装包,则不会成功。ClickHouse Version:ck的版本,不需要自己填写,通过下拉列表选择,下拉列表中会列出ckman服务器中所有的安装包版本。
- 此处版本信息只会列出当前
ckman服务下的安装包版本,如果配置了多中心,其他ckman的安装包是无法看见的- 在部署集群之前,需要先上传安装包。部署的集群版本是基于上传安装包的版本的。
Logic Name:逻辑集群名字,可以指定,也可以不指定TCP Port:clickhouse的TCP端口,默认是9000,当然也可以自己指定ClickHouse Node List:clickhouse节点列表,支持简写对于
clickhouse节点机器,推荐配置如下:
- 所有
HDD做一个大的RAID 5阵列- 用
hostnamectl设置hostname- 用
timedatectl set-timezone设置timezone- 启动
ntpd或者chrony网络时间同步- 永久关闭
swap- 永久关闭防火墙
firewalld- 安装
tmux,mosh,emacs-nox等常用软件- 创建一个普通账户并加入
wheel组,允许其sudo切换(是否输入密码均可)到超级用户
Replica: 是否开启副本,默认是关闭
- 如果开启了副本,默认是1个
shard2个副本,如果节点是奇数,则最后一个shard为1个副本。- 如果要增加节点的副本数,可通过增加节点完成,创建集群时最多只能指定2个副本
- 如果没有开启副本,则有几个节点就有几个
shard- 注意:集群是否支持副本在部署集群时就已经决定了,后续不可更改
Zookeeper Node List:zk列表
ckman并没有提供zookeeper集群搭建的功能,因此在部署集群之前,需要将zookeeper集群搭建好。
ZooKeeper Port:zk端口,默认是2181
ZK Status Port:zookeeper指标监控的端口,默认8080
- 该功能是
zookeeper v3.5.0以上版本开始支持的,如果zk版本太旧,无法从界面看到zk的指标
Data path:ck节点数据存放的路径
Cluster Username:ck的用户名
- 注意:
default用户作为保留用户,此处不能填default。
Cluster Password:ck的密码
SSH Username:ssh登录ck节点的用户名
- 该用户必须具有
root权限或是sudo权限,可以是普通用户,只需要该普通用户具有sudo权限即可。
AuthenticateType: 认证方式
- 支持三种认证方式:
0-密码认证(保存密码), 1-密码认证(不保存密码),2-公钥认证- 默认方式为公钥认证,公钥认证需要配置免密登录, 并将证书(
.ssh/id_rsa)拷贝到ckman的工作目录的conf下(rpm安装位置为/etc/ckman/conf),同时需要保证ckman与用户对id_rsa有可读权限。- 如果认证方式为密码认证(不保存密码),则后续运维操作如增删节点、启停集群以及升级等,都需要手动输入密码
SSH Password:ssh登录ck节点的密码
SSH Port:ssh端口,默认是22
Storage: 存储策略
disks
- 支持
local,hdfs,s3三种磁盘,clickhouse内置了名为default的磁盘策略- 注意
hdfs只有在ck版本大于21.9时才支持。policies
- 策略的磁盘必须要在上述
disks中存在。
User Config:用户配置
Users:配置用户的名字 ,密码,以及使用什么profile和quota策略Profiles:配置信息,规定了资源使用以及是否只读等权限策略Quotas: 配额配置,该配置项规定了一段时间内查询、插入等使用的资源配置User Custom Config: 用户自定义配置 ,规则同下面的Custom Config,不过该项自定义配置最终生成在users.xml中。
Custom Config:自定义配置项
自定义配置项最终生成在
config.d/custom.xml中,在clickhouse启动时会与默认的config.xml进行merge,形成最终的config.xml配置文件自定义配置项提供一个空的
key-value模板,key的写法尽量靠近xpath语法标准(请参阅:https://www.w3schools.com/xml/xpath_syntax.asp),不同`xml`层级之间以`/`分隔 ,attr属性以[]包裹,每个属性的key以@开头,举例如下:
key填写内容:title[@lang='en', @size=4]/header
value填写内容:header123则生成的
xml样式如下:<title lang="en" size="4"> <header>header123</header> </title>
除此之外,还有一个强制覆盖的选项。如果待部署的主机上已经有clickhouse服务正在运行了(可能是其他的集群的其中一个节点,但不受当前的ckman纳管),正常情况下是不允许部署的。如果勾选了强制覆盖,则会强制销毁该节点上已有的clickhouse服务,重新覆盖部署。
通过此种方式安装部署成功的集群的mode就是deploy,可以对其进行删、改、rebalance、启停、升级以及节点的增删等操作。
导入集群
点击主页的 Import a ClickHouse Cluster按钮,会进去导入集群界面。
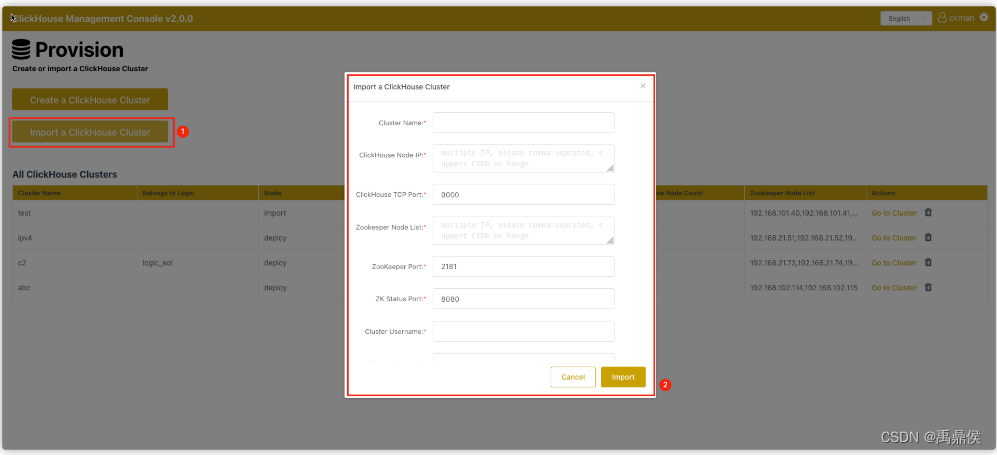
需要填写的信息如下所示:
Cluster Name: 节点名称,该名称必须是确实存在的集群名,且不能与ckman中已有的集群名字重复。
ClickHouse Node IP:clickhouse节点ip列表,以逗号分隔
ClickHouse TCP Port:ck节点TCP端口,默认为9000
Zookeeper Node List:zk节点列表
ZooKeeper Port:zk端口,默认为2181
ZK Status Port:zookeeper指标监控的端口,默认8080
Cluster Username:ck的用户名
Cluster Password:ck的密码,非必输
导入集群有个前提是该集群必须确实存在,否则导入会出现问题。
导入的集群的mode为import,这种模式的集群不能进行修改、rebalance、启停、升级以及节点的增删等操作,但是可以删除和查看。
升级集群
如果上传了新版本的安装包,可以从Upgrade Cluster下拉列表中选择新版本,点击Upgrade即可进行升级。
目前支持全量升级和滚动升级两种策略。并让用户选择是否检查相同版本。
升级界面如下:

销毁集群
集群销毁后,该集群在物理上都不存在了。因为销毁集群动作不止会停止掉当前集群,还会将节点上的ClickHouse卸载,相关目录清空,所以该动作应该慎重操作。
增加节点
点击Manage页面的Add Node按钮以增加节点。
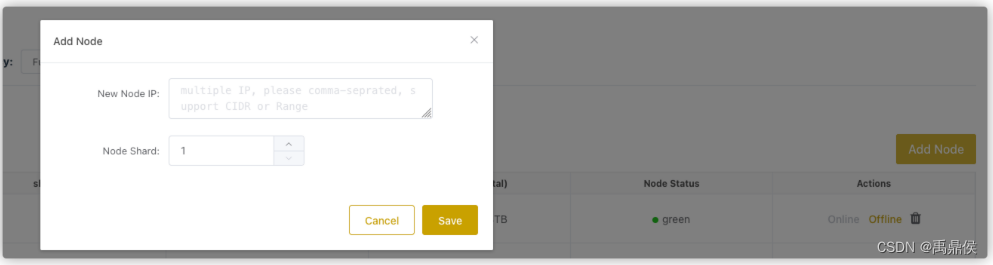
增加节点需要填写:
New Node IP: 新节点的IP,可以一次性增加多个节点,这些节点将会位于同一个shard上。Node Shard: 节点的Shard NUmber。- 如果填写的
shard是已经存在的,那么增加的节点会作为已存在shard的一个副本;如果shard不存在(一般是最大的shard编号+1,如果不是就不正确了),就会新增加一个shard。- 如果集群不支持副本模式,则每个
shard只能有一个节点,不可以给已有shard添加副本节点,如果集群支持副本模式,则可以在任意shard增加节点。
同部署集群,增加节点时也有一个强制覆盖的选项,即:如果待添加的节点上已经有clickhouse服务正在运行了,则不允许部署,当勾选了覆盖安装选项后,会强制销毁已有服务,重新部署。
删除节点
删除节点时需要注意的是:删除节点并不会销毁该节点,只会停止该节点的clickhouse服务,并从clusters.json中删除掉。
删除节点时,如果某个shard有且只有一个节点,那么这个节点一般是不可以被删除的,除非该节点处于shard编号的最大位置。
如果被删除的节点上仍然存在数据,且该节点被删除后会造成整个shard的缩容,则存在数据丢失的风险,这种情况下默认不允许删除,可通过数据均衡功能先将该shard的数据迁移到其他shard上,然后再进行删除。
如果该shard的数据本身就不打算要了,也可以通过勾选强制删除选项,主动丢弃这部分数据,完成节点的删除。
监控管理
ckman提供了ClickHouse相关的一些指标监控项。这些监控项依赖于从prometheus中获取数据,因此,需要提前配置好prometheus。相关配置教程见ckman部署文档。
从v2.3.5版本以后,ckman支持http service discovery功能,只需要在promethues中配置好对应的url,即可自动发现需要监控的节点。配置方法如下:
- job_name: "ckman" http_sd_configs: - url: http://192.168.0.1:8808/discovery/node?cluster=abc - url: http://192.168.0.1:8808/discovery/zookeeper?cluster=test2 - url: http://192.168.0.1:8808/discovery/clickhouse
node会⾃动发现node_exporter相关的指标配置,默认端⼝为9100zookeeper会⾃动发现zookeeper相关的指标配置,默认端⼝为7000clickhouse会⾃动发现clickhouse相关的指标配置,默认端⼝为9363
如果url不带参数,则默认发现该ckman管理的所有集群,如果通过cluster指定集群名,则只⾃动
发现该集群相关的指标服务。
ClickHouse Database KPIs
| 指标 | 说明 |
|---|---|
clickhouse.Query | 针对Clickhouse集群的分布式表发起的查询,按照发起时刻的分布图 |
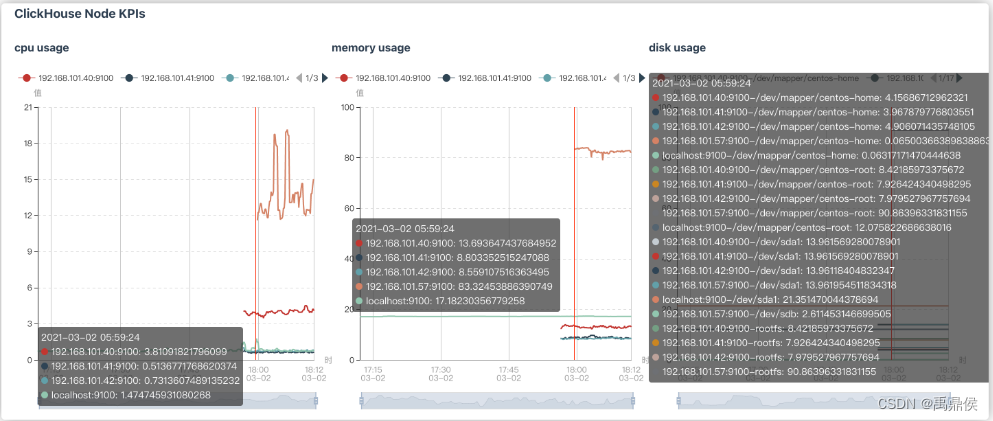
ClickHouse Node KPIs
| 指标 | 说明 |
|---|---|
cpu usage | CPU占用情况 |
memory usage | 内存占用情况 |
disk usage | 硬盘占用情况 |
IOPS | IO指标 |
ZooKeeper KPIs
| 指标 | 说明 |
|---|---|
znode_count | znode数 |
leader_uptime | leader存活时间 |
stale_sessions_expired | 过期的会话 |
jvm_gc_collection_seconds_count | jvm gc的次数 |
jvm_gc_collection_seconds_sum | jvm gc花费的时间 |
表&会话管理
Table Metrics
统计表的一些指标。除system数据库的表之外,其他数据库的表都会显示在下面。
指标包括:
Table Name
- 表名
Columns
- 列数
Rows
- 行数
Partitions
- 当前所有未合并的分区数
Parts Count
- 分区数
Disk Space(uncompress)
- 使用磁盘(未压缩)
Disk Space(compress)
- 使用磁盘(压缩),该大小是最终数据落盘的占用空间
RWStatus
- 读写状态,
TRUE代表可读写,FALSE代表不可读写Completed Queries in last 24h
- 过去
24小时成功的SQL条数Failed Queries in last 24h
- 过去
24小时失败的SQL条数Queries cost(0.5, 0.99, max) in last 7days(ms)
过去
7天SQL花费的时间。
Queries Cost有三个值:
0.5:过去7天50% SQL的平均耗时0.99:过去7天99% SQL的平均耗时max:过去7天SQL最大耗时
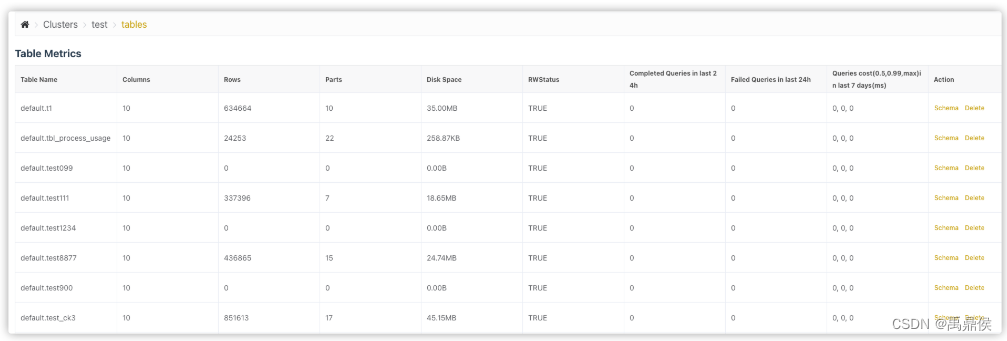
Table Replication Status
统计复制表的一些状态。
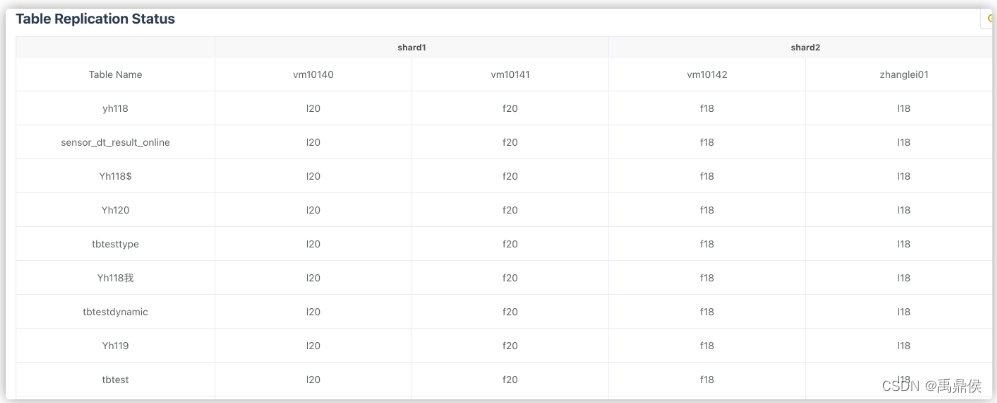
此处会统计每个shard下每张表的各副本之间的统计量。
理论上每个shard内副本之间各表的统计都应该相等的,如果有不相等,就说明有节点落后了,这时候落后的节点会标黄。如果某个副本上所有的表都落后,说明这个副本可能出问题了。
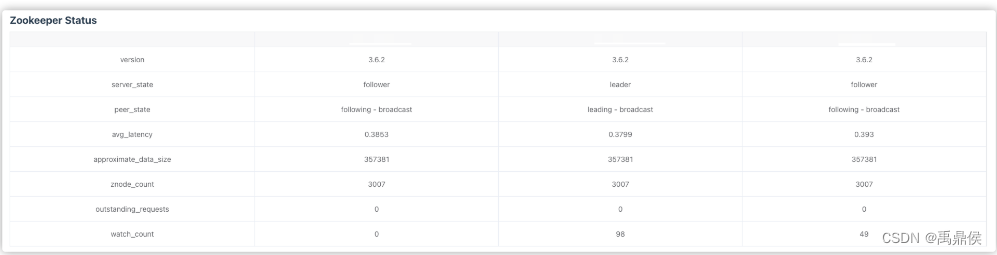
Zookeeper Status
zookeeper的相关指标查看。zookeeper监控使用的是zookeeper-3.5.0版本新增的特性,通过暴露的8080端口监控mntr指标信息,因此,如果想要看到zookeeper的监控指标,需要保证当前使用的zookeeper版本大于等于3.5.0。
可查看的指标包括:版本,主从状态,平均延迟,近似数据总和大小,znode数等。
Open Sessions
显示当前正在进行的会话,如果有正在执行的SQL,可通过界面将其kill掉。

Slow Sessions
显示7天内最慢的10条SQL语句。
包含SQL的执行时间、SQL耗时、SQL语句、ck用户、query id、查询的IP以及线程号。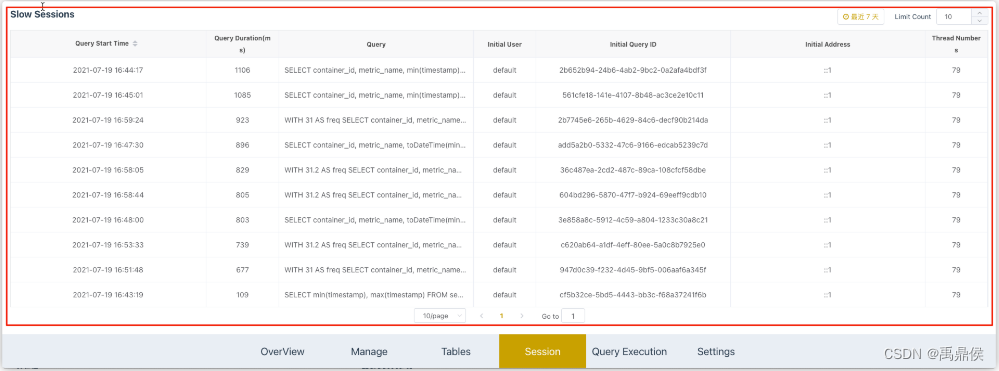
Query管理
ckman还提供了简单的clickhouse查询的页面。通过该页面可以查询集群中的数据。
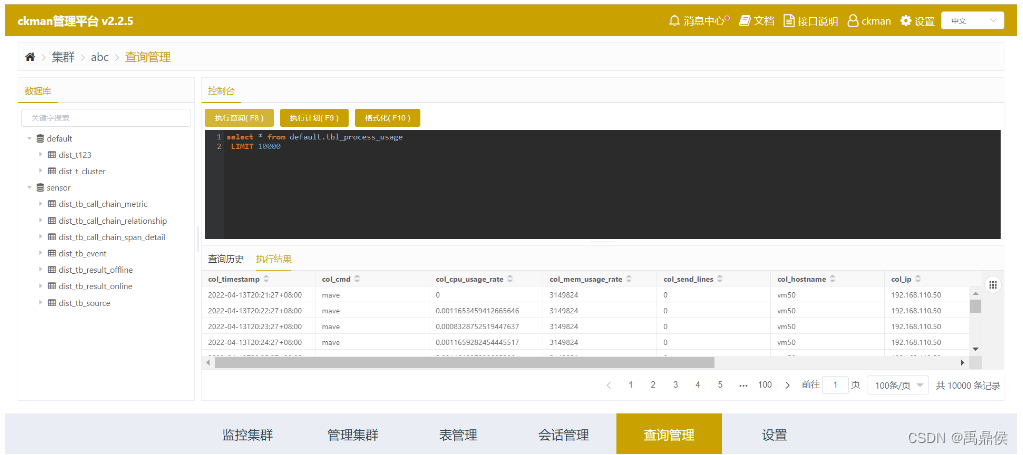
注意:
该工具只能查询,不能进行
mutation的相关操作。该工具主要针对分布式表,本地表也能查,但是如果本地表在集群的其他节点不存在,就会报错。即使表在所有节点都存在,查询出来的数据也是某个节点的数据,因此每次查询出来的数据可能不一致。
默认情况下,
sql随机挑选一个节点执行,因此返回的结果依赖于该节点的本地查询情况,如果查询的是本地表,则结果可能是不一致的。可以通过右上角的下拉框指定执行sql的节点。
配置管理
通过集群配置管理页面,可以修改集群的配置,注意对存储策略的配置的修改,如果已有的存储介质上已有数据,则该存储介质不可删除。
ckman会根据修改的集群配置的具体内容来决定集群是否需要重启。
接口规范
[POST]/api/login
ckman登录接口,输入用户名和密码,返回一个token。该token用户http鉴权,当用户对ckman不作任何操作超过1小时(超时时间可通过配置文件配置),该token会失效,此时访问任何页面都会重新跳转到登录页面。
username
- 用户名,默认是
ckman
password
密码,
ckman接收到的密码是前端通过hash之后的密码,默认hash之前是Ckman123456!, 该密码可以通过ckmanpassword工具进行修改。修改登录密码步骤:
注意:
Ckman123456!是默认的密码,该密码可以通过ckmanpassword工具进行修改。修改方式和ckman的安装方式有关:如果是
tar.gz解压安装,则需要进入到bin目录下,在该目录下执行:./ckmanpassword如果是通过
rpm方式安装,则需要cd到/etc/ckman/conf目录下,执行:cd /etc/ckman/conf ckmanpassword执行完成后,在
conf目录下会生成一个新的password文件,覆盖掉原来的password,这样就可以使用新的密码登录了。
请求参数示例:
{"password": "63cb91a2ceb9d4f7c8b1ba5e50046f52","username": "ckman"
}
返回示例:
{"retCode":"0000","retMsg":"ok","entity":{"username":"ckman","token":"eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9"}
}
[PUT]/api/logout
退出ckman登录状态的接口,无需任何参数,无任何返回数据。
调用该接口后,退出登录,跳转回登录状态,同时原来的token失效。
[POST]/api/v1/ck/archive/{clusterName}
归档指定表的一定时间段的数据。
begin
- 指定时间段的开始时间,该时间要小于结束时间
database
- 指定数据库的名字
end
- 指定时间段的结束时间,该时间要大于开始时间
- 注意时间段是包含开始时间,不包含结束时间
maxfilesize
- 每个文件的最大大小,如果超过该大小,会被切割成另外的文件
- 默认每个文件大小为
1G- 如果文件过大,则在备份时需要耗费更大的内存,如果系统内存不大,或者配置的
clickhouse可使用的内存比较小,则容易造成备份失败tables
- 需要导入的表名,该参数是一个数组,可以配置多个
format
- 备份格式。支持
ORC、CSV、Parquet三种格式的备份target
- 备份的目标
- 支持以下三种备份:
hdfs: 备份到hdfslocal:备份到本地s3: 备份到s3hdfs:
- 当
target为hdfs时有效addr
HDFS的地址dir
HDFS的目录,如果该目录不存在会报错- 导入到
HDFS的最终路径为:hdfs://addr/dir/shard_%d_host/cluster/database.table/archive_table_slotbegin/data.suffixuser
- 登录
HDFS的用户名local
- 当
target为local时有效path
- 每个节点的本地路径,该路径不能与
ck的原始数据路径重合- 最终存储的路径为:
path/shard_%d_host/cluster/database.table/archive_table_slotbegin/data.suffixs3
- 当
target为s3时生效Endpoint
- 连接
s3使用的端点地址AccessKeyID
- 连接
s3使用的访问key,需要提前创建好SecretAccessKey
- 连接
s3使用的访问秘钥,需要提前创建好Region
s3的region,需要提前制定好Bucket
- 数据存放的
bucket,如果不存在则自动创建Compression
- 压缩格式, 支持
none, gzip/gz, brotli/br, xz/LZMA, zstd/zstgzip压缩格式对比none,压缩率高达80倍左右gzip压缩存入s3,磁盘占用比之存储ck,压缩率达到2倍左右- 如果不配置压缩格式,默认使用
gzip- 最终存储的路径为:
bucket/shard_%d_host/cluster/database.table/archive_table_slotbegin/data.suffix.compression
请求参数示例:
{"begin": "2023-01-01","database": "default","end": "2023-01-11","format": "ORC","hdfs": {"addr": "sea.hub:8020","dir": "/ckman","user": "hdfs"},"local": {"Path": "/data/backup/"},"maxfilesize": 1000000000,"s3": {"AccessKeyID": "KZOqVTra982w51MK","Bucket": "ckman.backup","Compression": "gzip","Endpoint": "http://192.168.0.1:9000","Region": "zh-west-1","SecretAccessKey": "7Zsdaywu7i5C2AyvLkbupSyVlIzP8qJ0"},"tables": ["tb_result_offline"],"target": "hdfs"
}
[GET]/api/v1/ck/cluster
获取集群列表。
返回给前端的集群信息中,凡是涉及到密码的都进行了脱敏,显示的全是星号。
[POST] /api/v1/ck/cluster
导入一个集群。
该接口可以导入一个已经存在的ClickHouse集群。
cluster- 集群名称,该集群需要在
ClickHouse中已经存在,不可乱填hosts- 节点列表,导入集群是通过该节点查询
system.clusters获取集群的相关信息,所以该节点实际上可以只填一个- 如果填写多个节点,会从节点中随机选取一个去连接数据库查询相关信息
portClickHouse的TCP端口,默认是9000user- 连接
ClickHouse集群的用户名password- 连接
ClickHouse集群的密码,该密码不能为空zkNodesClickHouse集群依赖的zookeeper集群,该集群也要提前存在zkPortzookeeper端口,默认是2181zkStatusPort- 监控
zookeeper指标的端口,默认是8080,3.5.0以上版本支持
请求参数示例:
{"cluster": "test","hosts": ["192.168.0.1","192.168.0.2","192.168.0.3","192.168.0.4"],"password": "123456","port": 9000,"user": "ck","zkNodes": ["192.168.0.1","192.168.0.2","192.168.0.3"],"zkPort": 2181,"zkStatusPort": 8080
}
[GET]/api/v1/ck/cluster/{clusterName}
获取指定集群的配置信息。
返回示例:
{"retCode": "0000","retMsg": "ok","entity": {"mode": "deploy","hosts": ["192.168.0.1", "192.168.0.2"],"port": 9000,"httpPort": 8123,"user": "ck","password": "********","cluster": "test","zkNodes": ["192.168.0.1", "192.168.0.2", "192.168.0.3"],"zkPort": 2181,"zkStatusPort": 8080,"isReplica": false,"version": "21.3.9.83","sshUser": "root","sshPassword": "********","sshPasswdFlag": 0,"sshPort": 22,"shards": [{"replicas": [{"ip": "192.168.0.1","hostname": "node1"}]}, {"replicas": [{"ip": "192.168.0.2","hostname": "node2"}]}],"path": "/data01","zooPath": null,"logic_cluster": "logic_eoi"}
}
[DELETE]/api/v1/ck/cluster/{clusterName}
删除一个集群。
注意:此处的删除集群只是从ckman的纳管列表中将集群移除,该集群物理上仍然存在,并不会实际销毁集群。
该操作导入的集群和部署的集群均可操作。
[PUT]/api/v1/ck/destory/{clusterName}
销毁一个集群。
该操作只有使用ckman部署的集群才能操作。与删除集群不同,该操作会将集群彻底销毁,卸载掉集群所有节点的rpm或deb包。
[POST]/api/v1//ck/dist_logic_table/{clusterName}
为逻辑集群创建分布式表。
由于逻辑集群自身的限制,无法直接通过创建常规分布式表的方式创建出跨逻辑集群的分布式表,该接口主要用来创建跨逻辑集群查询的分布式表。
database
- 数据库名
table_name
- 需要创建的表名称
- 需要注意的是该表指的是本地表,需要在逻辑集群纳管的所有物理集群中都存在。
dist_name
- 分布式表名
- 本地表名和分布式表名只需指定一个即可
请求参数示例:
{"database": "default","table_name": "test_table"
}
[DELETE]/api/v1/ck/dist_logic_table/{clusterName}
删除逻辑集群的逻辑表。接口参数同创建逻辑表。
[GET]/api/v1/ck/get/{clusterName}
获取集群状态。
返回示例:
{"retCode": "0000","retMsg": "ok","entity": {"status": "red","version": "20.8.9.6","nodes": [{"ip": "192.168.0.1","hostname": "node1","status": "green","shardNumber": 1,"replicaNumber": 1,"disk": "2.21TB/13.64TB"}, {"ip": "192.168.0.2","hostname": "node2","status": "green","shardNumber": 1,"replicaNumber": 2,"disk": "2.06TB/13.64TB"}, {"ip": "192.168.0.3","hostname": "node3","status": "red","shardNumber": 2,"replicaNumber": 1,"disk": "NA/NA"}, {"ip": "192.168.0.4","hostname": "node4","status": "red","shardNumber": 2,"replicaNumber": 2,"disk": "NA/NA"}, {"ip": "192.168.0.5","hostname": "node5","status": "green","shardNumber": 3,"replicaNumber": 1,"disk": "2.87TB/19.02TB"}],"mode": "deploy","needPassword": false}
}
[PUT]/api/v1/ck/node/start/{clusterName}
只有当节点状态是red的时候才可以调用。
[PUT]/api/v1/ck/node/stop/{clusterName}
只有当节点状态是green时才可以调用。
[POST]/api/v1/node/{clusterName}
增加节点。
- ips
- 需要增加节点的ip列表
- 可以增加多个,支持CIDR和Range简写
- shard
- 分片编号
- 如果集群为非副本模式,只能在最后添加(也就是只能增加新的分片,无法为已有分片添加副本)
- 如果集群为副本模式,可以填写已有分片编号或新分片编号
- 如果填写已有分片编号,则为已有分片添加一个副本
- 如果填写新的分片编号,则新增一个分片
- 新增分片编号只能填写当前最大分片编号
+1
请求参数示例:
{"ips":["192.168.0.5","192.168.0.6"],"shard": 3
}
[DELETE]/api/v1/node/{clusterName}
删除节点。
删除节点时需要注意:
- 当集群为非副本模式,只能删除最后一个节点,无法删除中间的节点
- 当集群为副本模式,可以删除任意分片的节点。但是如果该分片有且仅有一个节点,除非它是最后一个分片,否则不允许删除
- 总之,如果删除节点会导致某个分片被删除,则该节点只能是最后一个,否则不允许删除
当点击Manage页面节点列表的删除按钮时,该接口会被调用。
[GET]/api/v1/ck/open_sessions/{clusterName}
获取正在运行的SQL语句。
[POST]/api/v1/ck/ping/{clusterName}
探测集群节点可用性。
原则是只要每个shard有一个节点可用,那么该集群就属于可用状态。
[POST]/api/v1/ck/purge_tables/{clusterName}
删除指定时间段范围的历史数据。
begin
- 指定时间段的开始时间,该时间要小于结束时间
database
- 指定数据库的名字
end
- 指定时间段的结束时间,该时间要大于开始时间
- 注意时间段是包含开始时间,不包含结束时间
tables
- 需要导入的表名,该参数是一个数组,可以配置多个
请求参数示例:
{"begin": "2021-01-01","database": "default","end": "2021-04-01","tables": ["t1","t2","t3"]
}
[GET]/api/v1/ck/query/{clusterName}
简单的查询SQL接口。
该接口只支持分布式表的查询,且数据量不宜太大。
如果查询的表是本地表,如果该表在所有节点都存在,那么查询不会报错,但是查询的结果只会显示其中某一个节点上的数据。
[PUT]/api/v1/ck/rebalance/{clusterName}
数据再均衡。
数据再均衡提供了两种模式:按partition做rebalance,和按shardingkey做rebalance。
在请求参数中,用户可以填写需要均衡的表名和shardingkey,表名支持正则表达式写法,如果shardingkey不填,则默认按照partition做rebalance。
另外有一个可选的all选项,当all为true时,则会自动均衡所有的分布式表,如果all为false,则仅均衡请求中传过来的表。默认为true。
按partition做rebalance
需要注意,如果集群为非副本模式,是通过rsync直接进行分区数据的迁移的,因此,需要机器提前安装好rsync工具,且需要保证clickhouse各节点之间配置ssh互信。如果部署时使用的是普通用户,则需要配置/etc/sudoers文件里该用户为NOPASSWD。
为了保证数据均衡时不影响数据写入,最新的partition不参与数据的均衡。因此,分区粒度越细,均衡效果越好。
按shardingkey做rebalance
shardingkey支持字符串、日期、数值等类型,如果是字符串,则使用xxHash该key,计算出一个数值,除以shard数目,余数为几,就落到哪个分区,如果是数值类型,也是一样,直接拿这个数值除以shard数目取余数。
ckman会将计算出来的数据插入到对应分片的一个本地临时表内,然后清空正式表,再将临时表数据物理搬运过去。因此,在搬运期间如果失败,可能造成正式表数据丢失,但是临时表数据是全的,所以需要手动将临时表数据迁移回正式表。
另外,数据均衡时提供了一个选项,是否清空最后一个shard的数据,如果打开此开关,则会将最后一个分片的所有数据均衡地迁移到剩余的shard种,使最后一个分片处于没有数据的状态,方便无丢失数据地进行缩容。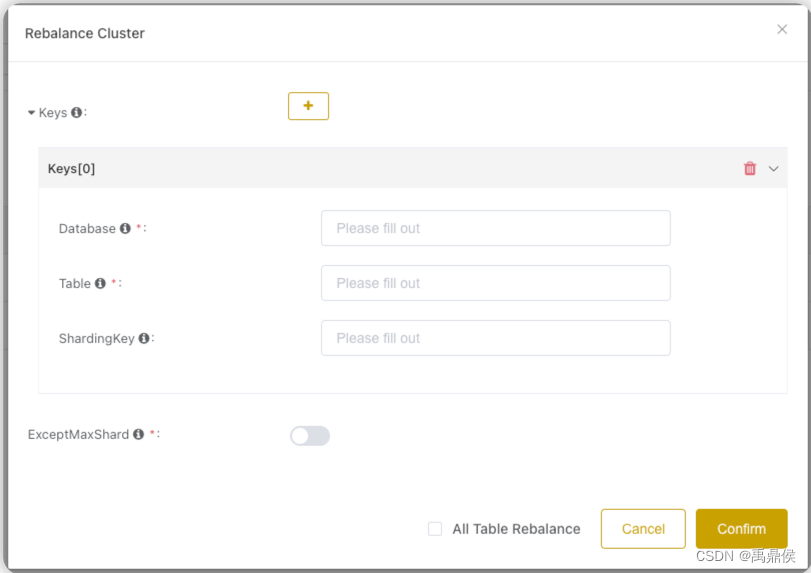
[GET]/api/v1/ck/slow_sessions/{clusterName}
获取慢SQL查询。
该接口提供了三个参数,分别为start、end、limit。
start
- 开始时间,可通过时间选择器选择,默认是
7天前end
- 结束时间,可通过时间选择器选择,默认是当前时间
limit
- 查询条数,默认是
10条
调用示例:
/api/v1/ck/slow_sessions/abc?limit=10&start=1626665021&end=1627269821
[PUT]/api/v1/ck/start/{clusterName}
启动集群。
如果集群内的节点本身就是green状态,则该节点不会被启动。如果所有节点都是start状态,则Start Cluster按钮是灰色的,不能点击。
[PUT]/api/v1/ck/stop/{clusterName}
停止集群。
如果集群内的节点本身就是red状态,则该节点不会被启动。如果所有节点都是red状态,则Stop Cluster按钮是灰色的,不能点击。
[GET]/api/v1/ck/table/{clusterName}
获取表的描述信息。
该接口的对象为本地表,且该本地表需要在集群的各个节点上都存在。
调用示例:
/api/v1/ck/table/test?tableName=tbtest&database=default
返回示例:
{"retCode": "0000","retMsg": "ok","entity": [{"name": "service","type": "String","defaultType": "","defaultExpression": "","comment": "","codecExpression": "","ttlExpression": ""},{"name": "ip","type": "String","defaultType": "","defaultExpression": "","comment": "","codecExpression": "","ttlExpression": ""},{"name": "metric","type": "String","defaultType": "","defaultExpression": "","comment": "","codecExpression": "","ttlExpression": ""},{"name": "value","type": "Int64","defaultType": "","defaultExpression": "","comment": "","codecExpression": "","ttlExpression": ""},{"name": "timestamp","type": "DateTime","defaultType": "","defaultExpression": "","comment": "","codecExpression": "","ttlExpression": ""}]
}
[PUT]/api/v1/ck/table/{clusterName}
更新表。使用ALTER语句完成分布式表的更新。
支持的操作包括增加列、修改列、删除列。
修改完成后需要删除分布式表并重建。
name
- 表名
database
- 数据库名
add
- 要添加的字段,包含以下属性
name
- 字段名
type
- 字段类型
after
- 字段位置
modify
- 要修改的字段,包含以下属性
name
- 字段名
type
- 字段类型
drop
- 需要删除的字段,可以是多个
请求参数示例:
{"name":"t1","database":"default", "add":[{"name":"fieldNew", "type":"String","after":"field3"},{"name":"filedLast", "type":"Int32"}],"modify":[{"name":"field6", "type":"DateTime"}],"drop": ["field8", "field9"]
}
[POST]/api/v1/ck/table/{clusterName}
创建表。默认使用的是MergeTree引擎,如果指定了distinct为false,表示支持去重,使用的引擎为ReplacingMergeTree。
最终的引擎还要根据集群是否支持副本来决定,一共有以下几种情况:
| distinct | isReplica | engine |
|---|---|---|
true | true | ReplicatedReplacingMergeTree |
true | false | ReplacingMergeTree |
false | true | ReplicatedMergeTree |
false | false | MergeTree |
与此同时,还需要在集群里创建一张dist_开头的分布式表。
name
- 表名
database
- 数据库名
fields
- 字段名称,可以是多个字段,包含以下属性:
name
- 字段名
type
- 字段类型
order
order by的字段,可以是多个partition
partition by的字段,支持以下三种策略
policy
- 分区策略,
0- 按天 1-按周 2-按月"name
- 分区字段
distinct
- 是否支持去重
请求参数示例:
{"name": "t1", "database": "default", "fields":[{ "name":"id","type":"Int32"},{"name":"birth","type":"Date"},{"name":"name","type":"String"}],"order": ["id"], "partition": "partition by的字段","partition":{"policy": 0,"name": "birth"},"distinct": true
}
[DELETE]/api/v1/ck/table/{clusterName}
操作和描述表类似,通过tableName指定表名,database指定数据库名。
调用示例:
/api/v1/ck/table/test?tableName=t1&database=default
通过以上操作就能删除掉表t1。删除时先删dist_开头的分布式表,再删表t1。
注意:表必须在集群的各个节点存在且不能是
dist_开头的分布式表。如果该本地表虽然在集群中各节点存在,但没有根据该本地表创建过分布式表,删除依然会报错。这一点需要注意。
[GET]/api/v1/ck/table_metric/{clusterName}
获取集群内表的相关指标。
[GET]/api/v1/ck/table_schema/{clusterName}
获取指定表的建表语句。该接口是v2.0.0新增接口。
[PUT]/api/v1/ck/upgrade/{clusterName}
升级集群。
packageVersion
- 版本号
policy
- 升级策略,支持全量升级和滚动升级,默认为全量升级。
Full-全量升级,Rolling-滚动升级skip
- 是否跳过相同版本
- 实时查询各节点的版本号,如过数据库无法连接,则强制升级
[GET]/api/v1/config
获取ckman配置。
[PUT]/api/v1/config
修改ckman配置。
[POST]/api/v1/deploy/ck
部署集群。
clickhouse
ckTcpPort
ClickHouse绑定的TCP端口,默认为9000clusterName
- 集群名,不可与已有集群名重复
isReplica
- 是否支持副本,部署时一旦指定,后续不可更改
logic_cluster
- 逻辑集群名称,非必输
packageVersion
ClickHouse版本password
- 连接
ClickHouse的密码,不可为空path
ClickHouse数据路径shards:分片
replicas:副本
ip:副本内的ip,可以有多个user
- 连接
ClickHouse的用户名,不可为defaultzkNodes
ClickHouse集群依赖的zookeeper集群zkPort
zookeeper集群的端口,默认为2181zkStatusPort
- 监控
zookeeper的端口,默认为8080hosts
- 集群列表
password
ssh连接节点的密码savePassword
- 是否保存
ssh密码sshPort
- 连接
ssh的端口,默认为22usePubkey
- 是否使用公钥连接
user
ssh连接节点的用户,该用户需要有root权限或sudo权限
请求调用示例:
{"clickhouse": {"ckTcpPort": 9000,"clusterName": "test","isReplica": true,"logic_cluster": "logic_test","packageVersion": "20.8.5.45","password": "123456","path": "/data01/","shards": [{"replicas": [{"ip": "192.168.0.1"},{"ip":"192.168.0.2"}]}, {"replicas": [{"ip": "192.168.0.3"},{"ip":"192.168.0.4"}] }],"user": "ck","zkNodes": ["192.168.0.1","192.168.0.2","192.168.0.3"],"zkPort": 2181,"zkStatusPort": 8080},"hosts": ["192.168.0.1","192.168.0.2","192.168.0.3","192.168.0.4"],"password": "123456","savePassword": true,"sshPort": 22,"usePubkey": false,"user": "root"
}
[GET]/api/v1/metric/query/{clusterName}
从prometheus获取单点指标数据。
[GET]/api/v1/metric/query_range/{clusterName}
从prometheus获取某一个范围的指标数据。
[GET]/api/v1/package
获取ClickHouse的rpm安装包列表。
返回示例:
{"retCode": "0000","retMsg": "ok","entity": [{"version": "22.3.3.44","pkgType": "aarch64.rpm","pkgName": "clickhouse-common-static-22.3.3.44-2.aarch64.rpm"},{"version": "22.3.6.5","pkgType": "amd64.tgz","pkgName": "clickhouse-common-static-22.3.6.5-amd64.tgz"},{"version": "22.3.3.44","pkgType": "x86_64.rpm","pkgName": "clickhouse-common-static-22.3.3.44.x86_64.rpm"},{"version": "21.9.5.16","pkgType": "x86_64.rpm","pkgName": "clickhouse-common-static-21.9.5.16-2.x86_64.rpm"},{"version": "21.8.15.7","pkgType": "x86_64.rpm","pkgName": "clickhouse-common-static-21.8.15.7-2.x86_64.rpm"},{"version": "21.8.13.6","pkgType": "x86_64.rpm","pkgName": "clickhouse-common-static-21.8.13.6-2.x86_64.rpm"},{"version": "21.8.9.13","pkgType": "x86_64.rpm","pkgName": "clickhouse-common-static-21.8.9.13-2.x86_64.rpm"}]
}
[POST]/api/v1/package
上传ClickHouse的安装包。
注意安装包上传时需要三个安装包都上传(server、client、common)。上传成功后,会显示在安装包列表中。
注意:如果上传的安装包有缺失(比如少了
common),安装包仍然能上传成功,但不会显示在列表上。所有上传成功的安装包都会保存在ckman工作目录的package/clickhouse目录下。
[DELETE]/api/v1/package
删除ClickHouse安装包。
[GET]/api/v1/version
获取ckman的版本信息。
[GET]/api/v1/zk/replicated_table/{clusterName}
获取复制表状态。统计复制表的一些状态。
[GET]/api/v1/status/{clusterName}
zookeeper的相关指标查看。
RoadMap
- 监控集成
grafna - 支持只读用户
- 云原生适配
-
clickhouse-keeper支持
本专栏知识点是通过<零声教育>的系统学习,进行梳理总结写下文章,对C/C++课程感兴趣的读者,可以点击链接,查看详细的服务:C/C++Linux服务器开发/高级架构师