预备知识
到目前为止,我们所学习到的关于文件的操作,全部都是基于文件被打开,被访问,访问期间比较重要的有重定向,缓冲区,一切皆文件,当我们访问完毕的时候需要将文件关闭,关闭时那也就是将对应的文件对象进行关闭,缓冲区该刷新刷新,该释放时释放,该清空清空,可是所有的动作都是基于内存级的,对于一个文件打开这种情况的一系列操作。
1.你的系统里可能有成千上万的文件,所有的文件都被打开了吗?
并不是所有的文件都会被打开,被打开的文件可能只有1/100,甚至1/500,甚至1/1000,就比如你系统里面有10000个文件,可能被打开的只有200个,还有9800多个根本就没有被打开。
2.一个文件被打开了有刚刚所谈的那些操作,那么一个文件被打开之前,文件在哪里呢?
其实这些文件都在磁盘上进行保存。
那么问题就来了,其实我们在内存中那些被打开的文件本来相对整个系统的文件数目来说本来就占少数,这些文件都需要通过struct file这样的结构体进行管理起来,那么我们没有被打开的那些那么多的文件要不要被管理起来呢? 答案当然是要管理了,要不然fopen这个接口要打开一个文件为什么可以通过带路径之后找到这个文件再打开呢?

我们没有被打开的文件不仅要在磁盘上进行保存,还需要带有规律的进行保存,方便用户进行随时读取,其实就是方便用户随时打开,随时换出内存。
其实用我们生活中的例子也很容易理解,就比如你的衣服,并不是所有的衣服都是穿在身上的,而是身上穿一件,大部分衣服都是放在你的衣柜里面的,那么你的大部分衣服虽然没有穿,但是你要不要把这些衣服放好呢?也就是管理好呢?就在你哪天需要指定的某一件衣服的时候你管理起来了,那么你想找到这件衣服会很快速的知道它在哪里,那么如果你把衣服随便扔一个地方,当你需要的时候换那一身衣服的时候你会发现你很难找到,效率特别低,甚至可能找不到了。所以说你身上那套衣服是你正在使用的衣服,而没有穿在身上的那些衣服依然需要管理好。而对于这样对衣服进行管理的核心工作是什么?是为了快速定位你需要的衣服。也就是快速定位文件。那么管理好了之后就是怎么快速定位文件的问题了,那么在我们快速定位文件就需要谈及到路径了。
生活中的例子其实比比皆是,你们平常都有各种网购买东西,你们学校附件的菜鸟驿站都有来自各个学生的成千上万的快递,但是不是所有的快递都会及时的被同学们拿走,比如说你取你的快递,把你的快递取走打开了,你要使用这个快递了,叫做你打开这个文件了,但是大部分的快递还是暂时存在菜鸟驿站里面,那么剩下的这么多没有被访问的快递,菜鸟驿站的工作人员也需要将这些快递进行管理起来,如果快递就随便堆积如山,也不进行管理,那么如果有个人来取快递,那估计得找个大半天,那还不一定能找着。所以我们平常都有看到菜鸟驿站工作人员有给快递进行分类然后贴上对应的取件码,其实这个取件码就很像我们谈到的文件路径,我们通过取件码可以迅速找到自己的快递,同样我们也可以通过文件存放在磁盘上的路径对文件进行快速定位。我们菜鸟驿站工作人员所做的工作叫做文件系统,文件系统是我们操作系统的一个分支,操作系统有内存管理,进程管理,也有文件管理等等。
所以,我们可以把文件的管理工作总结为:
1.打开的文件进行管理
2.没有被打开的文件也要在磁盘中进行管理
这就是文件系统做的工作。
其实文件系统解决的是文件存储的问题,而我们的文件=内容+属性,所以进而转化成了对文件内容存储和对文件属性存储的问题。文件存储在磁盘中需要方便我们的操作系统/用户对文件进行增删查改。
而我们下面主要谈的是没有被打开的文件也要在磁盘中进行管理,下面我们需要先对磁盘硬件进行深入了解,也就是理解硬件的物理存储结构,然后对其进行逻辑抽象,来理解逻辑存储结构,最后来理解文件系统与操作系统之间的关系。
理解磁盘---硬件——物理存储结构
为什么要用磁盘来对文件进行存储呢?因为它便宜,容量大,所以大部分的公司企业就会大量使用。
如下是磁盘的图片


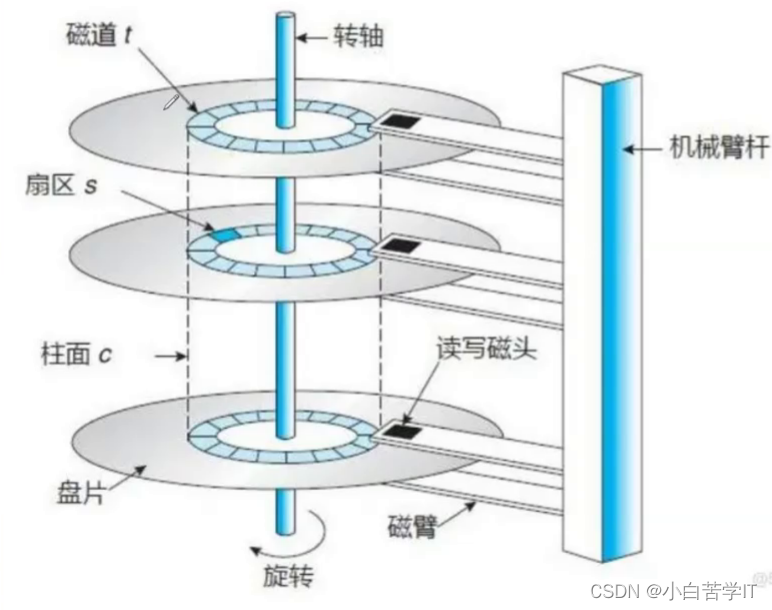
如下是侧视图:
如下是俯视图
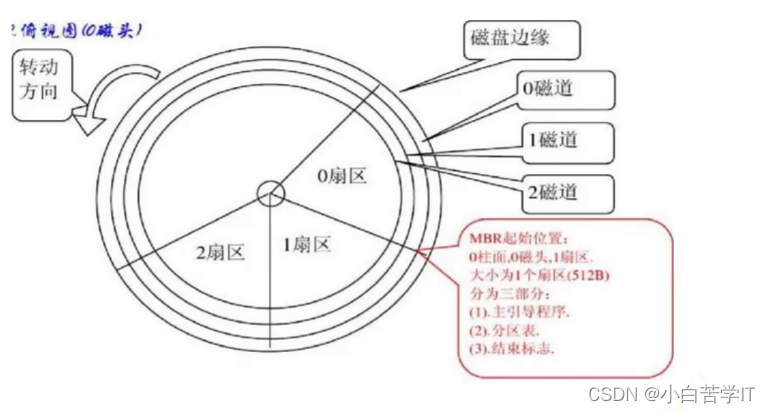
一个盘面可以有很多的同心磁道,一圈磁道可以有很多扇形的扇区,扇区是磁盘的最小存储单元---512字节。其中如果你自己只想改变这一个扇区里面的一个比特位,你都必须把整个扇区加载到内存中,所以我们把磁盘这样的设备叫做块设备。如果我想向一个扇区写入,我们该如何寻址呢?
1.先选择哪一面? --- 本质选择磁头
2.选择该面上的哪一个磁道
3.选择在该该磁道的哪一个扇区
我们一般把这种定位方法叫做CHS定位法,既然我们可以向一个扇区写入,就可以向任意一个/多个扇区写入,甚至连续多个扇区式的写入,当然也可以随机写入。那么文件的存储问题就是文件的内容和属性的存储,而文件内容和属性的存储本质就是二进制数据的存储,所以文件的存储问题最终都会落在磁盘当中以扇区的形式为基本单元,把文件的属性和内容的数据全部都给我们保存好。这些文件的存储全部都是在磁盘盘片某一面上的某个磁道上的某个扇区上以512字节进行存储,如果你是一个比较大的文件,那你可能要存在多个扇区上,如果你是属性可能只需要一个512字节,如果是内容可能需要多个512字节,也可能只需要一个扇区。所以多个扇区里,有的可能存的是属性,有些可能存的是内容。
其实每个磁头都有编号,所以定位磁头不需要机械运动,而寻找磁道是通过磁头在盘面上左右转动,而盘面高速旋转是为了找到对应的扇区。这就是为什么磁头需要这么运动,然后盘面需要高速旋转。这就是CHS定位法的寻址原理。
理解逻辑抽象——逻辑存储结构

上图不知道小伙伴们有没有见过,它叫做磁带,磁带这玩意和那个光盘是同一个时代的产物,磁带是软性介质,里面是可以存储数据的,复读机里面也有马达,可以把磁带转起来,磁带去旋转的时候会有相应的硬件进行数据读取。

这种复读机可以把它打开,然后把磁带放进去,我们之前如果有见过磁带的小伙伴应该知道,他是有两个圈圈的,磁带从左边转到右边,转完的时候还可以取下来反一面倒着转,叫倒带。
磁带把那些黑色条状的东西拉出来就是上述第一张图那个样子,这个是软性介质,所以我们也可以把它拉的很长,拉的很直,卷起来就是同心圆的样子,拉直了就是一根长长的直线,磁盘的盘面卷起来就是圆状的。
所以呢,我们也可以把磁盘盘片想象成一个线性的空间

我们还可以把这一面继续进行划分,可以划分成很多的磁道,然后磁道也可以继续划分,划分成一片一片的扇区。
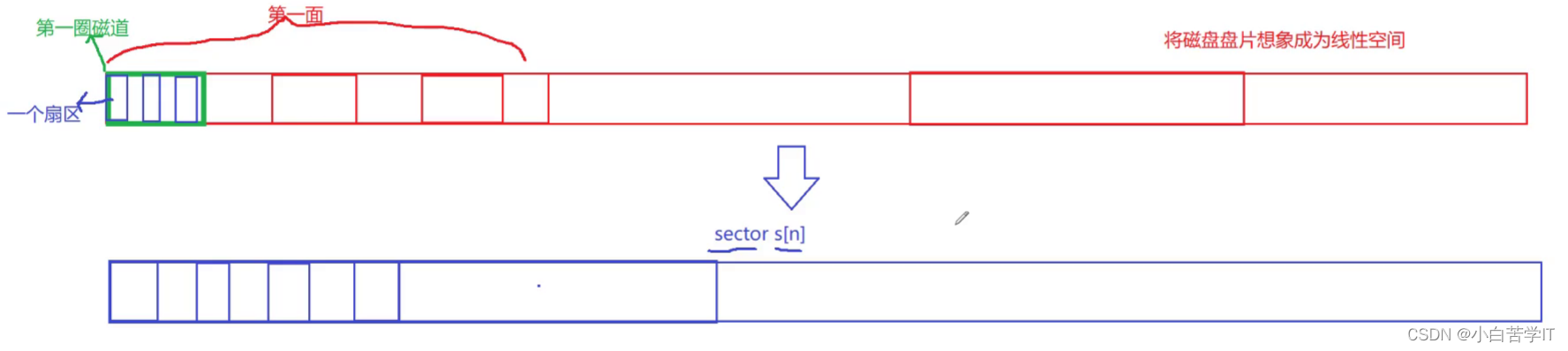
那么我们就可以把它逻辑抽象成以扇区为单位的数组,数组都是有下标的,那么我们假设从1~100000是第一面,100001~200000叫做第二面,第一面里面又可以化分成1~10000是第一个磁道,10001~20000是第二个磁道,每一面每一个磁道都是这么划分。所以我们对磁盘的管理就变成了对数组的管理。
假设寻找第123456个扇区的位置,那么我们首先寻找他在第几个面:123456/100000=1,也就是第2个面,然后123456%100000=23456,那么就是在第一个面的第23456个位置上。
那么我们就把我们的线性地址转化成了CHS地址。
操作系统可以按照扇区为单位进行存取,操作系统也可以基于文件系统,按照块为单位进行数据存取。其实操作系统以一个扇区为单位来进行访问有点小,为了提高一定的效率,所以进行了规定,以8个扇区为基本单位,也就是一个文件块来进行访问 (8*512 = 4096字节,也就是4KB)。从此往后我们只需要知道起始的地址,我们就可以访问8个扇区,我们把这种地址叫做LBA地址(Logical Block Address) 通过将这些LBA地址进行转化变成CHS地址就可以交给磁盘,磁盘就可以把数据写到对应的位置上了。
所以我们形成的最终的结论:对存储设备的管理在操作系统层面转换成了对(4KB blocks[])数组的增删查改。
理解文件系统
假设你的笔记本电脑有500GB大的磁盘空间,这个空间想要直接管理起来是非常困难的,就好比中国这么大的地方,我们叫中央政府来管理整个中国,那是不是很不现实,所以中国又分了很多个省,省里又分了很多个市,市里又分了一些小县城,所以我们会有区政府,市政府,省政府,所以这是在干什么呢?这不就是把一个很大的区域拆分成很多的小区域吗?大区域不好管,小区域好管对吧。所以呢,我们也可以按照这种做法,把磁盘的500GB进行拆分,拆分成100GB,100GB,100GB,100GB,100GB。所以呢我们要想把这500GB管好,只需要把这100GB管好就可以了,因为这些100GB都可以采用一样的管理方法进行管理,这个动作我们叫做分区。其实这个例子也随处可见,比如说我们自己的笔记本电脑,一般只有一块磁盘,而出现像C盘,D盘,E盘,F盘这种都是通过分区实现的,但是实际上只有一块磁盘。
然后我们还可以把这100GB划分成50个2GB的组(Group),也就是50组,那么管理好500GB也就变成了管理好一个组,也就是2GB的内容就可以了。这种思想就是大事化小的思想,分治法。
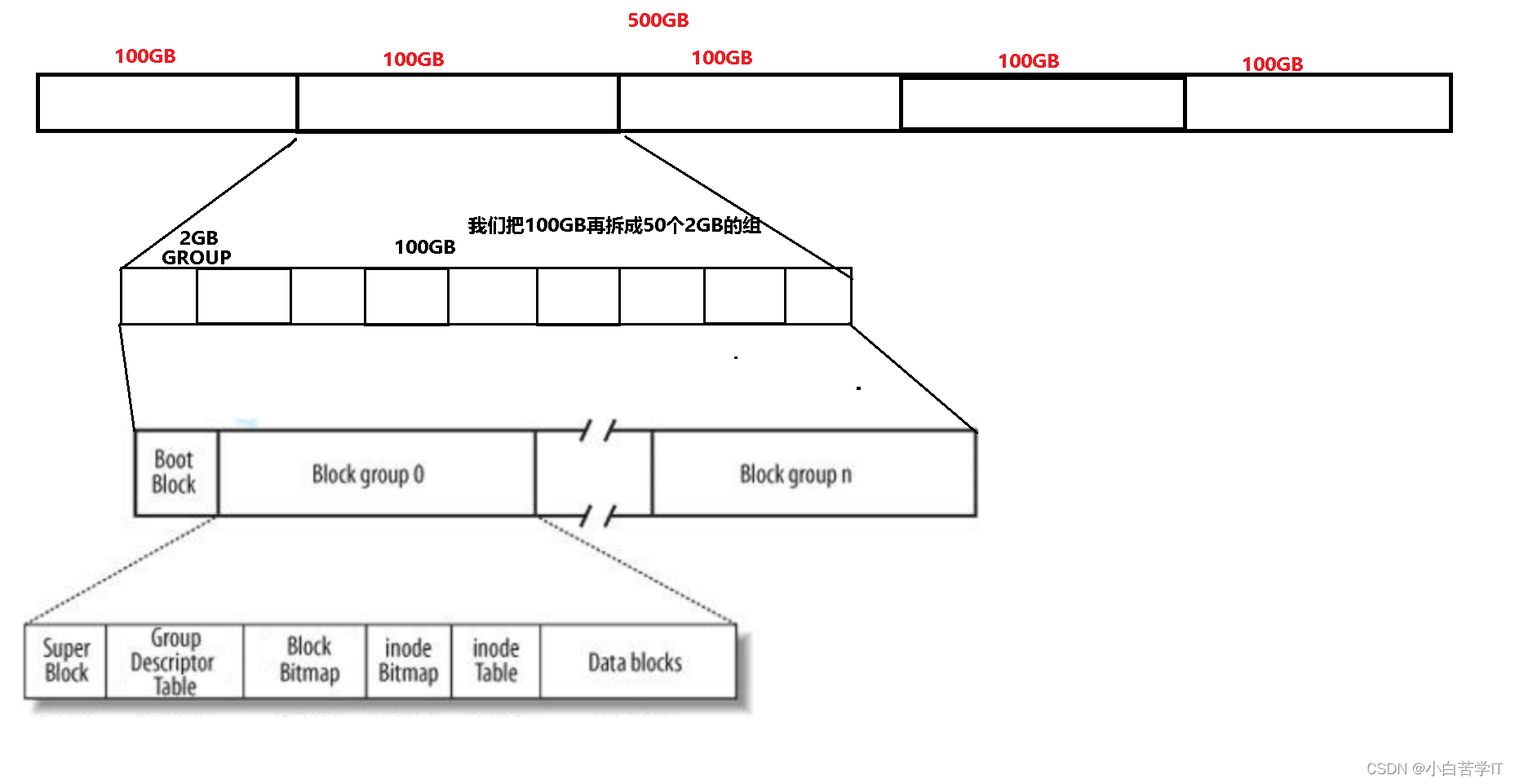
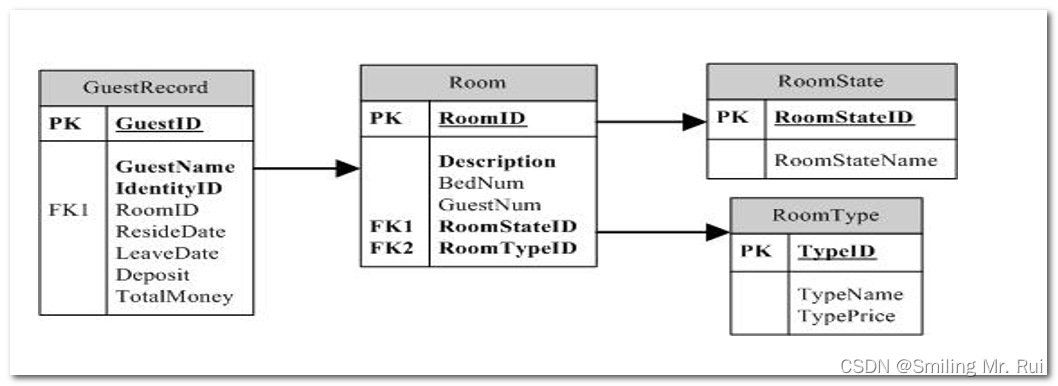
如上图所示,我们把这些组叫做块组,这些块组里面存的数据有两种,一种是我的文件信息,另一种是跟多的文件管理的数据。而我的文件信息包括内容和属性,这些都是数据,内容和属性分开存储。而在我们班级里面,除了有普通的学生,也有一些班干部,对班级进行管理的一些成员,我们步入学校不久,那么班级的管理者会很快就选出来,因为方便后续对班级进行管理,所以对一个分组来讲呢,在正式使用文件系统之前,我们一定要把每一个组当中的管理数据写入到块组当中,也就是说比如说使用了多大的空间,还剩多少空间等等这些数据是应该提前显示出来的。所以换句话说就是块组里面的各个分区都要先写入管理数据,我们把这个操作称之为格式化。
下面我们在Xhell里面新建文件和目录:

我们认识一条新的指令:
ls -li
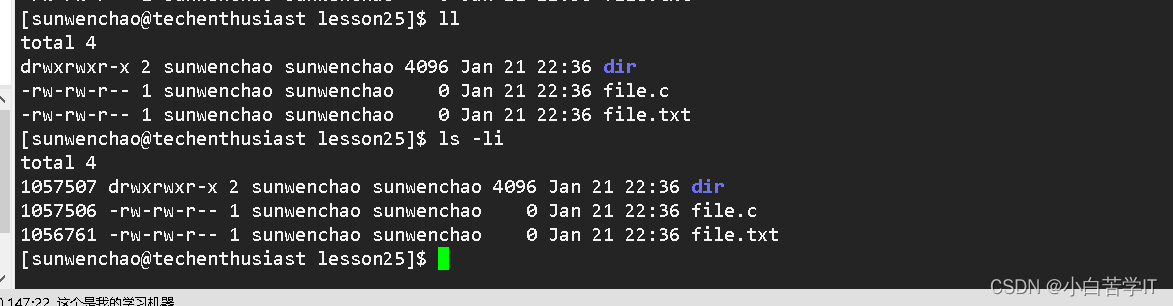
我们发现它比ll多一条数据,这条数据都是数字,每一个文件对应的这个数字都不一样,我们把这条数据叫做文件的inode编号,一般情况下,一个文件一个inode,也就是说inode 每个文件都有。在整个分区具有唯一性,在Linux内核当中,识别文件和文件名无关,和inode有关。
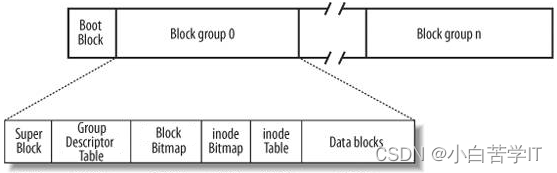
而我们这张图对应的inode Table叫做i节点表:存放文件属性 如 文件大小,所有者,最近修改时间等。保存文件属性是通过inode来保存的,Linux内核中有一个inode的结构体:
struct inode
{
大小,权限,拥有者,所属组,ACM时间,inode编号等。
}
这个结构体占128字节。
假设inodeTable里面有1000个4KB的文件块,那就是32000个inode,所以inode由于大小是固定的,所以inode在这张表里也很好定位,所以我想要知道inode在整张表的定位,我们只需要知道inode在整张表里的偏移量,所以给文件分配一个inode是很容易的,所以我们就可以把这张inode Table看成一个数组struct inode inode_table[N].
上图中的DataBlock是数据区:存放文件内容。

这些文件块都有对应的编号。其实inode结构体里面会维护一个int blocks[N]的数组,这个数组记录的是该inode对应的文件存放在数据区的文件内容所对应的文件块的编号,维持在一个数组里面,比如说该文件的文件内容存放在1,2,4编号的文件快中,那么就把这三个编号存在这个blocks数组中。
下面我们来谈inodeBitmap 表示 inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用。比特位的位置表示inode编号,比特位的内容(0/1)表示对应的inode编号是否被使用。
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。比特位的位置表示Block编号,比特位的内容(0/1)表示对应的Block编号是否被使用。
Block Group:ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
而我们的blocks数组可以存数据区中文件块的下标,其实数据区中的文件块除了可以存文件内容,还可以存数据区的文件块的下标,比如说 0~12是一级映射,13是二级映射,14是三级映射。那么用图表示就是:
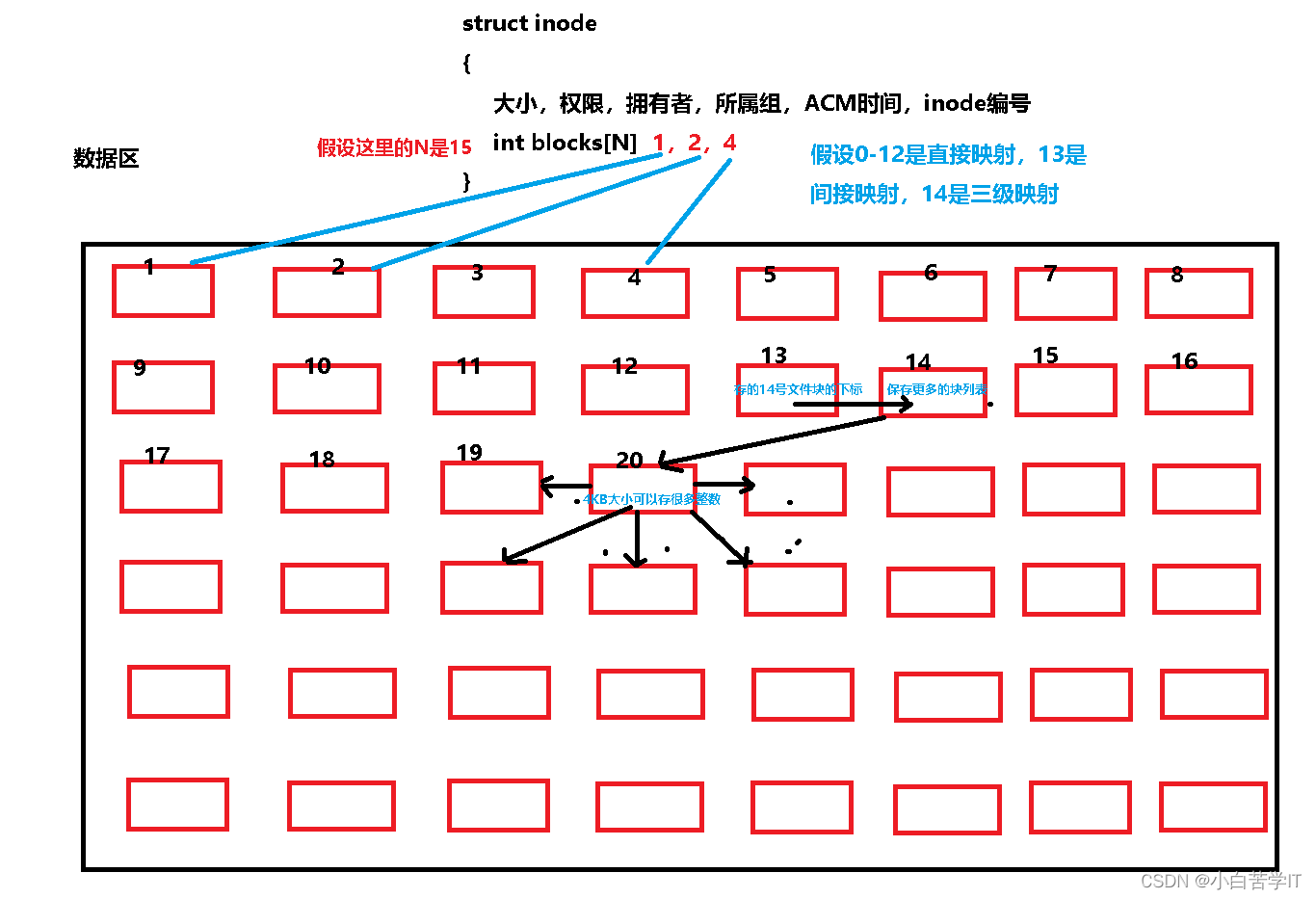
也就是说数据块里面除了能放数据还可以放索引。所以通过这样的方式就可以把一个比较大的文件拆成很多的小的文件块进行存储用blocks数组来进行管理。
假设有一个20GB的文件需要存到磁盘里面,你一个分组可能也就2GB,3GB的大小,像这种大文件,我们就可以这么去理解了,如果在一个组里面存不下,注定了要跨组访问,所以我们一个文件很大,那么一级索引,二级索引肯定都占了,那么还有一个三级索引就可以通过记录哪些块存在其他组了,把在哪个组的哪个块记录下来,比如说第5个组,1,2,4块数据块中,所以说文件如果太大了就可以通过跨组访问。
推而广之,一个组能够进行管理,那么每个组也就能进行管理了,每个组能进行管理了,那么100个GB也就能进行管理了,100GB能进行管理那么500GB自然就不是问题了。
可是,我们怎么感觉不太对啊,从刚开始说到现在,我们都好像还没用过inode这个东西啊,你用过吗?我们好像用的都是文件名啊。我们用户用的都是文件名,可是Linux操作系统一直都是用的inode,那么怎么对应起来呢?
a.用户只用文件名,Linux内核只用inode编号
b.文件名<->inode 文件名要与inode进行映射
由于我们平常谈的文件都是一些普通文件,那么目录我们该如何理解呢?目录是不是文件呢?
由于Linux下一切皆文件,所以目录是文件,但是与其他文件有些不一样。
目录也有文件的各种属性,所以这进一步说明了,目录是文件。那么既然是文件,文件=属性+内容,我们都知道不同文件可以存字符串信息,代码等等。属性我们知道了,与普通文件属性都类似,但是内容存的是什么呢?存的是自己目录内部直接保存的文件的文件名和inode的映射关系,
例如: test.c:1234.所以同一个目录下不允许存在同名文件,我们也可以理解为目录也是普通文件,只不过目录存的是普通文件名与inode 的映射关系。目录里面也可以放目录。
那么我们要对目录要进行修改文件,新建文件,删除文件,需要什么权限呢?答案很简单,当我们尤其是新建文件,删除文件是需要修改文件名与inode的映射关系的也就是修改目录的内容的,所以我们需要w权限。
我们发现inode结构体里我们没有写文件名,那是在Linux中,因为文件名不属于文件的属性,文件名是在目录的内容里面存着的。
那么我们怎么找到一个文件呢?
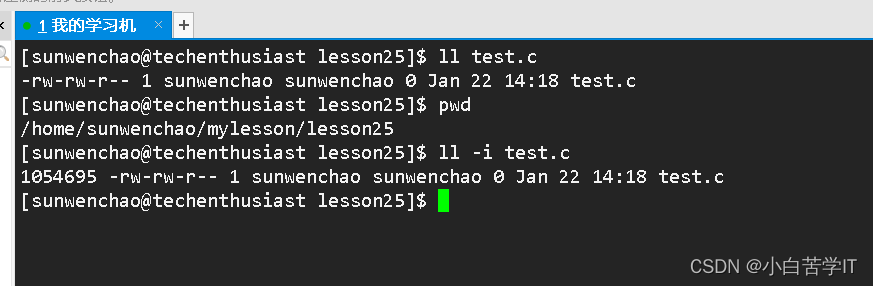
就比如说这个,我们怎么找到这个test.c呢,它的这一串属性字符串是哪里来的呢?我们知道它是在lesson25下的一个test.c的文件,通过找到这个文件的目录lesson25中的内容存的就是这个文件的inode与这个文件名的映射关系, 也就是1054695,找到这个inode之后然后去找到它在哪个分组,找到之后就找对应的分组里面的inode table里面的内容就可以得到该文件对应的这些属性对应的值,然后把这些值拼成字符串就可以显示到我们的显示器上了,该文件的内容也是一样的去找到这个文件inode对应的那个数据区,然后再通过blocks里面的对应的文件块的下标就可以加载到内存里,然后通过cat test.c就可以进行查看该文件的内容了。当然,这些都没有问题,但是我们这里都有一个前提,那就是找到lesson25这个目录,但是这个目录又该怎么找到呢?我们知道lesson25还有它的上级目录,所以我们可以继续先找到它的上级目录,也就是mylesson这个目录,找到之后还可以继续先找到该目录的上级目录,这样找下去会找到我们的根目录。所以我们是可以从根目录开始找的,同时根目录也有它的inode.
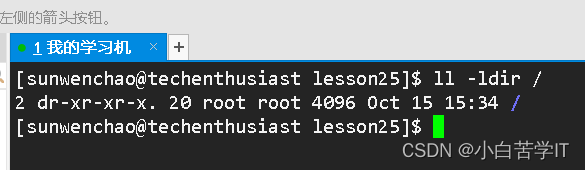
所以我们可以先通过根目录,找到home目录,然后再找到sunwenchao这个目录,然后再找到mylesson这样的路径就可以找到lesson25这个目录了。
也就是说我们想要找到一个文件是要对上述的路径进行剥离,那么这个路径是谁给的呢?
之前我们进行fopen进行文件操作的时候我们有传递过一个路径进行,所以很明显这个路径是我们用户/进程给的,当我们进入某个目录的时候会有一个pwd对我们的路径进行保存。
但是这都是在进行了路径保存的基础上,如果没有这个路径系统会解析失败的。
所以我们需要找到一个文件是需要相对应的路径的。
所以如果我们要执行这样一段代码:
int fd = fopen("./log.txt","r");
首先是进程来打开这个文件,由于进程有它自己对应的cwd路径,所以就可以通过这个路径来对这个路径进行剥离,然后就可以根据我们上面进行查找test.c这个文件的步骤来对该文件进行操作的。