接上篇《46、58同城Scrapy项目案例介绍》
上一篇我们学习了58同城的Scrapy项目案例,并结合实际再次了项目结构以及代码逻辑的用法。本篇我们来学习Scrapy的一个终端命令行工具Scrapy Shell,并了解它是如何帮助我们更好的调试爬虫程序的。
一、Scrapy Shell简介
Scrapy是一个强大的Python网络爬虫框架,而Scrapy Shell是Scrapy的一个命令行工具,用于在爬虫过程中实时查看和调试网页内容。

Scrapy Shell可以在未启动spider的情况下尝试及调试我们的爬取代码。其本意是用来测试提取数据的代码,不过我们可以将其作为正常的python终端,在上面测试任何的Python代码。该终端是用来测试xPath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写我们的spider爬虫时,该终端提供了交互性测试我们的表达式代码的功能,免去了每次修改后运行spider的麻烦。旦熟悉了scrapy终端后,我们会发现其在开发和调试spider时发挥的巨大作用。
二、Scrapy Shell的原理
1、Scrapy Shell的作用
Scrapy Shell是Scrapy框架中的一个重要组件,它提供了一个交互式的Python shell环境,允许开发者在爬虫运行过程中实时查看和操作网页内容。以下是Scrapy Shell的主要作用:
(1)网页内容查看:通过Scrapy Shell,可以方便地查看网页的结构和内容,包括HTML、CSS、JavaScript等。这对于分析网页结构和提取数据非常有用。
(2)调试与断言:在Scrapy Shell中,可以执行各种Python代码,进行断言和调试。例如,可以检查请求是否成功、响应的状态码是否为200、数据提取是否正确等。这有助于发现和解决爬虫中的问题。
(3)数据提取与处理:Scrapy Shell允许开发者直接在网页上提取数据,并进行处理。这有助于快速验证数据提取的逻辑和代码的正确性。
(4)请求与响应修改:在Scrapy Shell中,可以对请求和响应进行修改,例如修改请求头、请求URL、请求方法等,或者修改响应内容。这有助于测试和调整爬虫的行为。
(5)自动化测试:使用Scrapy Shell,可以对爬虫进行自动化测试,例如检查数据提取是否符合预期、爬虫是否能够正确地跟踪链接等。这有助于提高爬虫的稳定性和可靠性。
2、Scrapy Shell的工作原理
Scrapy Shell通过发送HTTP请求获取网页响应,并在交互式的Python shell环境中允许开发者查看和操作响应内容,以下是Scrapy Shell的工作原理:
(1)请求与响应:当启动Scrapy Shell时,它会向目标URL发送一个HTTP请求。Scrapy Shell使用Scrapy的下载器来处理请求,并获取响应。响应是一个Scrapy Response对象,它包含了网页的HTML、CSS、JavaScript等内容。
(2)Python Shell环境:在接收到响应后,Scrapy Shell会启动一个交互式的Python shell环境。在这个环境中,开发者可以输入Python代码来查看和操作响应内容。Scrapy Shell会自动将响应对象注入到shell环境中,使得开发者可以直接访问和操作响应对象。
(3)代码执行与断言:在Python shell环境中,开发者可以执行各种Python代码,进行断言和调试。例如,可以使用Python的BeautifulSoup库来解析HTML,提取数据并进行断言。如果断言失败,Scrapy Shell会显示断言错误,并允许开发者继续在shell环境中进行调试。
(4)请求与响应的修改:在Scrapy Shell中,开发者还可以对请求和响应进行修改。例如,可以修改请求头、请求URL、请求方法等,或者修改响应内容。这些修改可以在shell环境中立即生效,并允许开发者测试和调整爬虫的行为。
(5)退出与清理:当开发者完成在Scrapy Shell中的操作时,可以退出shell环境。退出后,Scrapy Shell会自动清理和释放相关资源。
3、Scrapy Shell与Scrapy的其他组件之间的关系
Scrapy Shell作为Scrapy框架中的一个重要组件,与其他组件之间存在着密切的关系。了解这些关系有助于更好地理解和应用Scrapy Shell。以下是Scrapy Shell与Scrapy其他组件之间的关系:
(1)下载器与Scrapy Shell:Scrapy Shell通过Scrapy的下载器组件来发送HTTP请求并获取响应。当启动Scrapy Shell时,下载器会处理请求并返回响应,使得开发者可以在Shell环境中查看和操作响应内容。
(2)调度器与Scrapy Shell:Scrapy Shell可以与调度器组件配合使用,以按照特定的计划或规则发送请求。调度器负责管理请求的排队和执行,而Scrapy Shell则可以在Shell环境中直接发送请求并获取响应。
(3)爬虫与Scrapy Shell:爬虫是Scrapy的核心组件,负责定义如何提取数据和跟踪链接等。Scrapy Shell可以与爬虫配合使用,帮助开发者在爬虫运行过程中实时查看和调试网页内容。开发者可以在Shell环境中测试和调整爬虫的行为。
(4)项目管理与Scrapy Shell:Scrapy Shell通常与Scrapy的项目管理相关联。当启动Scrapy Shell时,它会自动加载相应的项目配置和设置。这使得开发者可以在Shell环境中使用项目特定的设置和代码,进行数据提取和处理等操作。
(5)扩展与Scrapy Shell:Scrapy Shell可以与Scrapy的扩展组件配合使用,以扩展其功能。例如,可以使用扩展来修改请求和响应、处理特殊内容类型等。这些扩展可以在Shell环境中直接使用,以支持开发者进行调试和测试。
三、安装ipython
安装: pip install ipython
简介:
IPython 是一个基于 Python 的交互式计算环境,它为用户提供了一个更为强大和丰富的界面来使用Python语言。相较于标准的Python解释器,IPython提供了更多的增强功能,例如提供智能的自动补全,高亮输出,及其他特性。
如果我们安装了IPython,scrapy终端将使用IPython (替代标准Python终端)。 IPython终端与其他终端命令行工具相比更为强大。
四、Scrapy Shell的使用方法
1、启动Scrapy Shell
要启动Scrapy Shell,可以在命令行中输入以下命令:
scrapy shell <URL>其中,<URL>是要爬取的网页的URL地址。执行该命令后,Scrapy Shell会发送一个HTTP请求到目标URL,并在交互式的Python shell环境中启动。
2、使用Scrapy Shell查看网页内容
在Scrapy Shell中,可以直接输入response来获取响应对象,并通过响应对象访问网页内容。例如,可以使用以下代码提取网页标题:
response.title.strip()Scrapy Shell会自动将响应对象注入到shell环境中,因此可以直接访问响应对象的属性和方法。
3、使用Scrapy Shell进行断言和调试
在Scrapy Shell中,可以使用Python的断言语句来进行数据验证。例如,可以断言某个元素的文本是否符合预期:
assert response.css('h1.title').get().strip() == 'Expected Title'如果断言失败,Scrapy Shell会显示断言错误,并允许开发者继续在shell环境中进行调试。
4、使用Scrapy Shell修改请求和响应
在Scrapy Shell中,可以直接修改请求和响应对象的内容。例如,可以修改请求头、请求URL、请求方法等,或者修改响应内容。这些修改可以在shell环境中立即生效,并允许开发者测试和调整爬虫的行为。例如,可以修改请求头中的User-Agent:
request.headers['User-Agent'] = 'New User-Agent'5、Scrapy Shell的退出与清理
当开发者完成在Scrapy Shell中的操作时,可以输入exit()或Ctrl+D退出shell环境。退出后,Scrapy Shell会自动清理和释放相关资源。
五、Scrapy Shell的使用实例
首先我们cmd打开Windows的命令符对话终端,然后通过“scrapy shell <URL>”可以直接启动Scrapy Shell,请求目标url:
或者我们需要看到高亮或者自动补全,可以安装ipython(这里我们已经安装过了,会自动调用ipython)。
执行上面的代码后,我们可以看到返回了很多请求反馈信息,
其中就包括响应的Scrapy Response对象,它包含了网页的HTML、CSS、JavaScript等内容: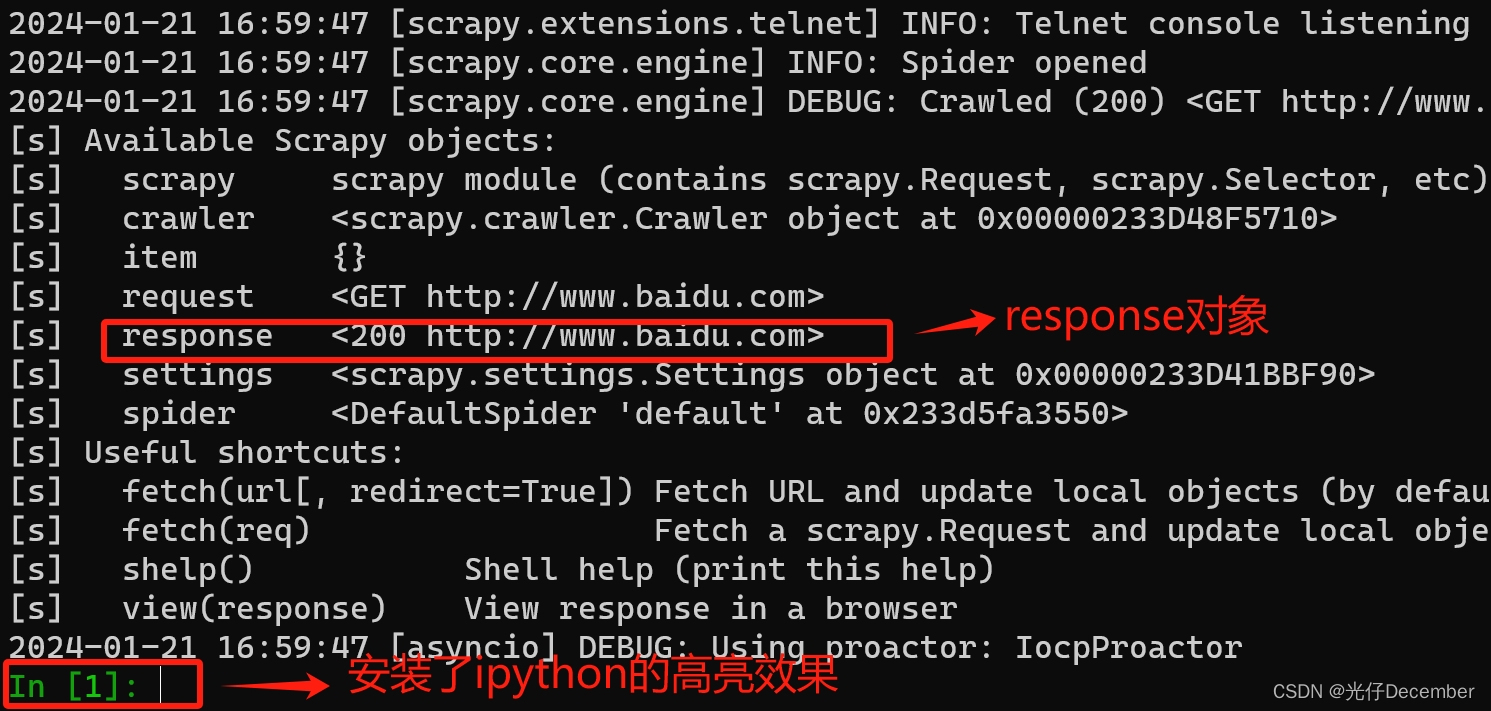
这里的response是可以直接使用的,例如我们输入“response.text”,就可以看到请求的url的网页源码的文本文档内容:
或者是查看response请求的url是哪个,或者response的返回状态码是多少: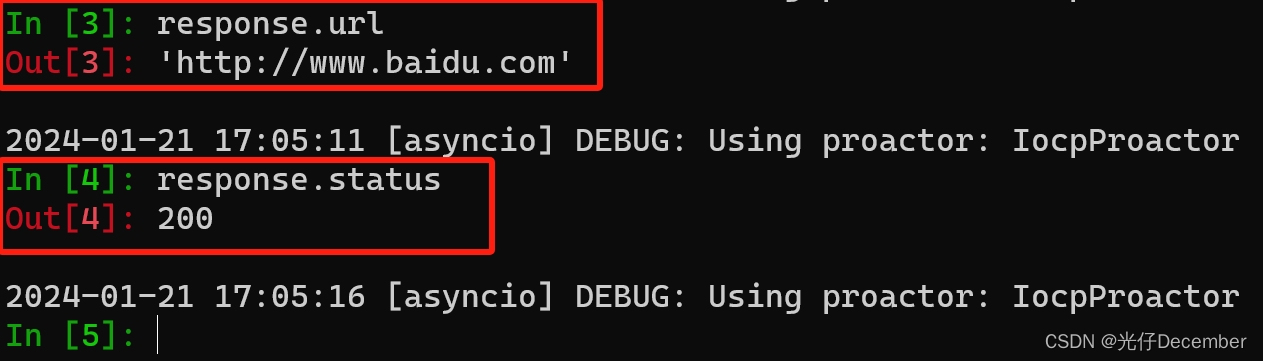
那么我们基本上就可以在不直接编写spider文件的情况下,去临时调试一个网页的爬虫逻辑。例如我们现在需要获取百度首页的“百度一下”: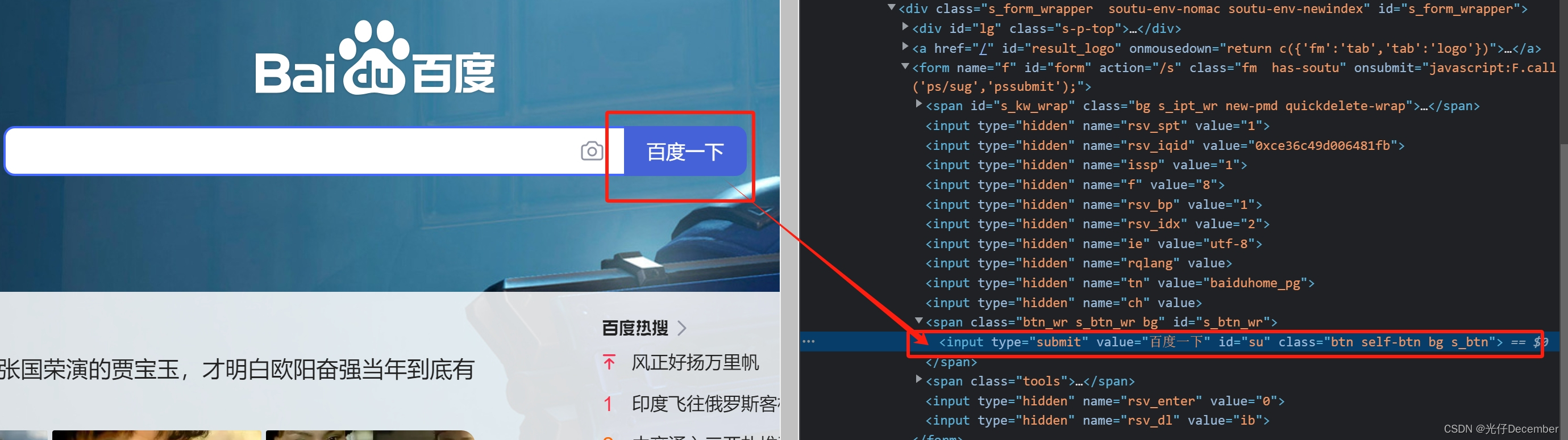
原来的xpath代码是这么写的(//input[@id='su']/@value):
此时我们利用response对象,就可以直接执行xpath函数获取该元素对象的信息: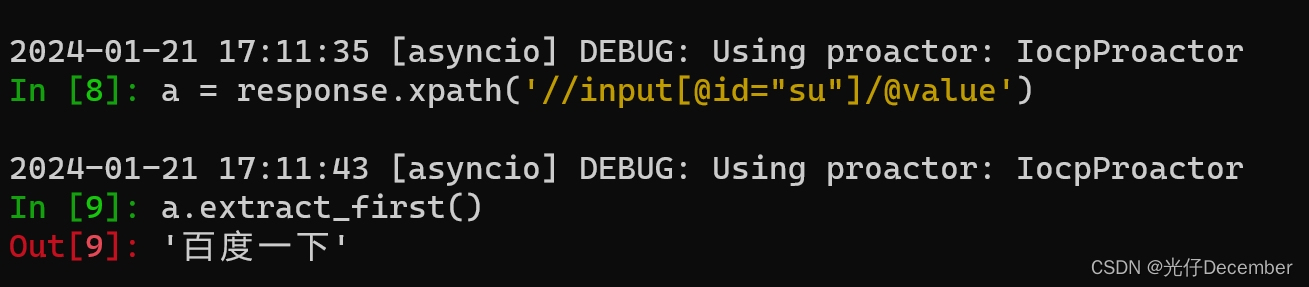
这里我们首先通过response.xpath获取到一个结果列表对象,然后通过“extract_first”函数获取列表的第一个内容,就是我们刚刚爬到的百度按钮的value值。
注:不知道函数全名咋写,安装了ipython的童鞋,可以按Tab健呼唤出提示(类似Linux的命令行提示),选择需要的函数:
这就是使用ipython的好处,可以提高我们的调试效率。
上面的方法,还可以使用css函数来实现,如: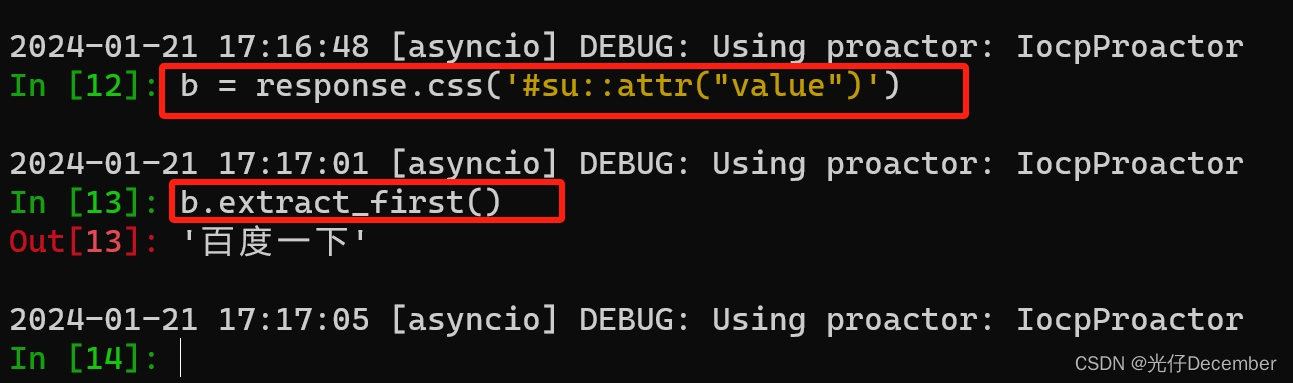
注:不推荐使用css函数获取数据,语法比较复杂。
以上就是scrapy shell的基本介绍和使用实例。下一篇我们来正式进入一个中型scrapy工程的开发,来爬取当当网的数据。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/135732129