高级的渲染步骤是由管道(软件架构)实现,各个阶段会操作输入流中的数据项,并对输出流产生数据。
管道每个阶段独立于其他阶段,所以管道的最大有点在于非常适合并行化。
渲染管道分为3个概要阶段。但在这里多讲几个阶段(包含脱机工具创建场景的阶段):
-
工具阶段(脱机):定义几何和材质
-
资产调节阶段(脱机):资产调节管道处理几何和材质数据,生成引擎可用的格式
-
应用程序阶段(CPU):识别潜在可视的网格实例并把它们和材质提交给GPU
-
几何处理阶段(GPU):变换顶点、照明,并投影至齐次裁剪空间
-
光栅化阶段(GPU):三角形转换成片段并着色。期间片段会进行多种测试,最终和帧缓冲混合
工具阶段
在Maya、3ds Max、SketchUp等工具中制作三维模型。美术也需要定义材质(包括贴到网格表面的纹理设置,以及其他高级特性比如选用哪个着色器、着色器的输入参数。。。)
资产调节阶段
导出、处理、链接多个种类的资产,生成一个整体,并已准备就绪供引擎导入。
应用程序阶段
主要进行三个方向的处理:
-
可见性判断。仅把潜在可见的物体提交给GPU。
-
提交几何图元给GPU。
-
控制那些不可编程但可配置的GPU管道参数及渲染状态。
可见性判断
首先进行平截头体剔除,用物体的包围体积(通常是球体)与平截头体的六个平面进行运算。每个平截头体的六个平面向外移动球体半径的距离,如若球的中心点在平截头体内部,则视为是在平截头体里面无需剔除,否则就应该剔除。
但目前游戏能达到非常大的规模,所有物体进行平截头体剔除有点不太现实,所以可以通过“场景图”的方式来进行剔除,即设计一些数据结构来管理几何物体,这类数据结构能短时间内判断是否在平截头体中,并在判断不在时迅速丢弃里面的物体。
四叉树是其中一个数据结构,把空间递归分割成象限,每层递归生成四个节点,直到每个子节点中含有n个物体。通常是每个子节点中包含一个物体。进行平截头体判断的方式很简单,就是从根节点向叶节点遍历,检查节点是否在平截头体范围内,如果该节点不在则迅速停止判断,并且此节点的叶节点都不可能在平截头体范围内了。
八叉树是四叉树的三维版本。二元空间分割(BSP)则是空间递归分割一半。kd树和BPS的特殊情况,BSP每次分割可以任意方向,kd每次分割都是轴对齐,先切割x坐标,再切割y坐标,依次类推。
其次进行遮挡判断。
有几项技术,其中一项是潜在可见集(PVS),即将场景划分为几个区域,每个区域提供能看见的其他区域列表。
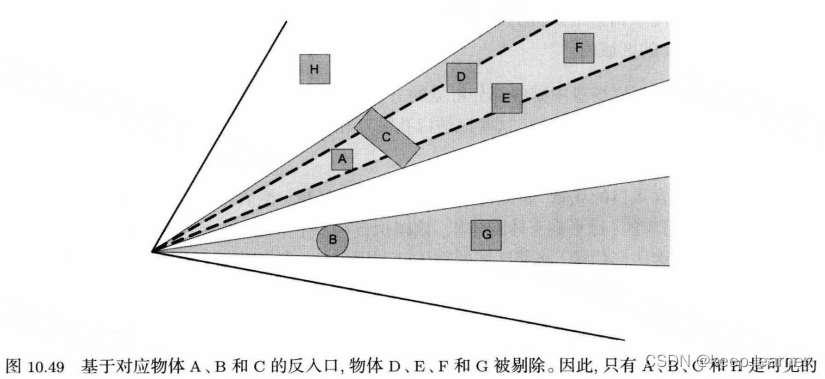
还有另一个方法:入口,每个区域用孔洞连接,每个孔洞(比如窗户/门户)和摄像机交互并向前延伸形成类似平截头体的效果,便可以和平截头体剔除一样确定哪些物体可不被渲染。

反入口则是相反概念,锥形视角也可视作是不可见区域,通过不可见区域来排除一定不可见的那些物体。
几何排序
为了增加GPU渲染效率,可以按照材质来排序几何物体,即先渲染材质A再渲染材质B。但是为了保证预先丢弃被遮挡的像素,有应该从前至后的顺序来渲染三角形,这样是更快的。那如何解决这一冲突呢,可以采用GPU的深度预渲染步骤,主要方式是渲染场景两次,第一次快速产生深度缓冲的内容,不透明物体用从前至后的顺序更新深度缓冲,第二次再用材质进行排序,用最少的状态改变渲染颜色。
渲染完不透明物体后再从后至前渲染半透明表面。也可使用次序无关透明,每个像素存储多个片段,场景渲染后无需排序直接渲染透明物体。但是因为每个像素要存储所有透明片段,所以存在高内存成本。
GPU管道
几乎所有GPU(图形处理器)都会把管道拆分为以下的子阶段:
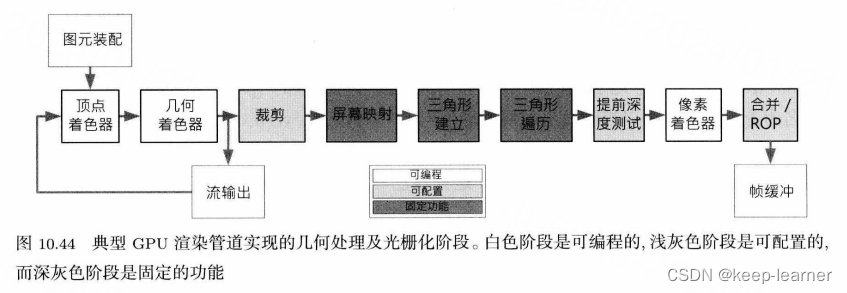
顶点着色器负责变换及着色顶点。输出是变换和着色后的顶点。
几何着色器处理以齐次裁剪空间表示的整个图元(三角形、线段、点),包括剔除、修改、添加图元,包括阴影体积拉伸、立方体贴图的渲染、布料模拟等。
流输出即数据能从这里回到管道开始的地方做进一步处理,比如头发的渲染,顶点着色器进行物理模拟完之后交给几何着色器渲染,然后顶点数据重新流入管道开始的地方渲染。
裁剪即是把三角形在平截头体外的部分切掉。同样能剔除完全在平截头体外的三角形。此阶段可配置,比如除了平截头体的平面外可定义额外的裁剪平面。
屏幕映射即简单的顶点变换,把其从齐次裁剪空间变换到屏幕空间。
三角形建立&遍历即将三角形转换成片段(光栅化)。
在提前深度测试阶段能够检查片段的深度,若某片段确定会被帧缓冲内的像素遮挡,就可在此时丢弃该片段。值得注意的是,不是所有GPU都支持这项操作,过去的GPU的深度测试是在像素着色器之后进行,所以这里被称为提前z测试或者提前深度测试。
像素着色阶段里,输入时一组每片段属性(通过顶点属性插值获得),输出则是颜色矢量,代表片段颜色。
合并/混合/光栅运算(ROP)阶段中,负责执行多个片段测试,包括深度测试、alpha测试、模板测试等。此片段若通过所有测试,则与帧缓冲原来的颜色进行混合。为了让alpha混合显示正常,必须先将不透明几何物体渲染至帧缓冲,然后依次渲染透明物体。
可编程着色器
着色器从输入数据取得一个元素,并变换为输出数据的零个或多个元素。
-
顶点着色器输入模型空间或者世界空间的顶点,输出变换和着色后的齐次裁剪空间的顶点。
-
几何着色器输入一个有n个顶点(1是点,2是线段,3是三角形)的图元,输出一个经过阴影体积拉伸、立方体贴图的渲染、布料模拟等处理后的图元。
-
像素着色器输入一个片段,输出的是将要写进帧缓冲的颜色。也可以丢弃这个片段,输出则是空。
抗锯齿
全屏抗锯齿/超采样抗锯齿(FSAA)
把场景渲染至比实际屏幕大的帧缓冲中,渲染完之后再向下采样至目标分辨率。
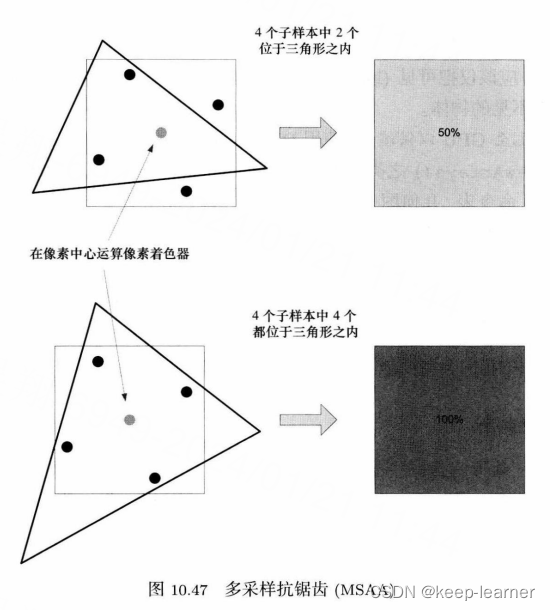
多采样抗锯齿(MSAA)
因为锯齿主要产生在三角形边缘而非内部,所以相对上个方法有所改良。
因为光栅化三角形可分为三个操作:1.判断三角形重叠(覆盖测试)。2.判断三角形遮挡(深度测试)。3.这两个测试之后着色。
非抗锯齿情况下的光栅化中每个像素都是基于一个点来做上面三个操作的,一般是选像素中央点。

但是MSAA中就是一个像素内采样多个点进行前两个测试,着色时就取这些采样点的子样本平均值来着色。
覆盖采样抗锯齿(CSAA)则是以上方法进一步优化,一次着色,N次深度测试,但是覆盖测试过程中会更多采样点进行测试,这样子能有更细致的色彩融合效果。比如1次着色,4次深度测试,16次覆盖测试。
形态学抗锯齿(MLAA)
正常尺寸渲染,通过扫描找出阶梯形状的图像模式,发现这些图像模式后通过模糊化降低混叠效果。





![有效的数独[中等]](https://img-blog.csdnimg.cn/direct/bea61b9a60d94065889e390f341bcdfd.jpeg)